
La arquitectura diseñada permite a ANJANA DATA gobernar diferentes tecnologías, clústeres y entornos, y también la hace independiente de las versiones de los productos de cada fabricante: Para cada versión habrá un microservicio con las funciones específicas que puedan existir en cada una de ellas y en caso de necesitarlo se puede aislar para evitar incompatibilidades o problemas de seguridad. Con esto, Anjana Data es la herramienta idónea para gobernar entornos y arquitecturas complejas, como puedan ser multi-cloud, híbridas, big data, etc, y la hace estar preparada para las nuevas tecnologías, y/o nuevos usos de las tecnologías de la información que están por venir.
De esta forma, ANJANA DATA ofrece una versatilidad y agilidad de crecimiento que permite ofrecer nuevas versiones con capacidades ampliadas en periodos de tiempo muy cortos, así como una capacidad de personalización total para las funcionalidades mencionadas.
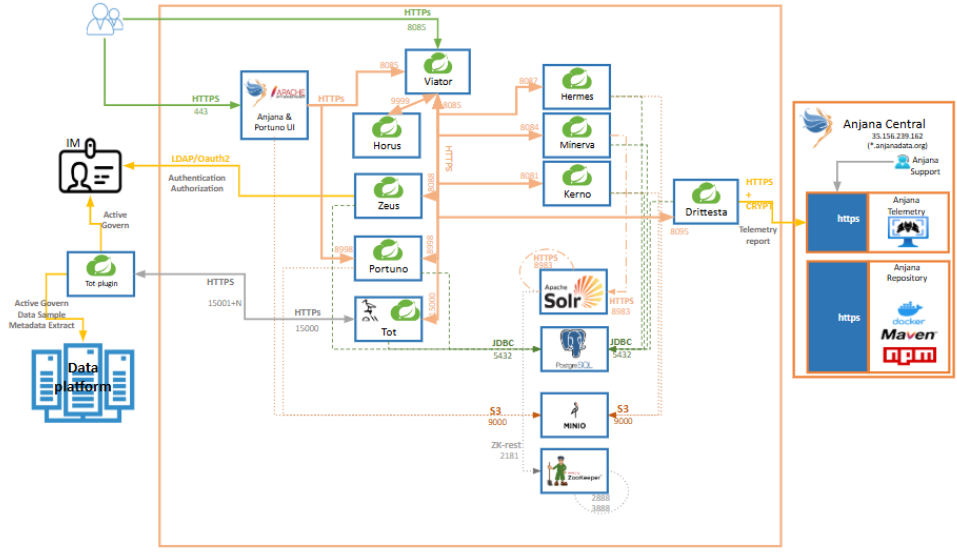

La arquitectura técnica de ANJANA DATA utiliza el stack de tecnología Spring Cloud en sus versiones más recientes incluyendo los módulos del producto correspondientes (Springboot, Eureka, Config, Security). Con el fin de lograr la máxima independencia con respecto a la tecnología / arquitectura, ANJANA DATA también hace uso de un repositorio para almacenar archivos o registros.
En este sentido, el stack tecnológico se puede agrupar en los siguientes bloques:
Microservicios basados en tecnologías spring cloud

-
Las tecnologías de Spring Cloud utilizadas y la constitución del producto hacen viable la implementación de alta disponibilidad en todos los puntos de la plataforma, muchos de los cuales son de facto redundantes debido a la tecnología utilizada y los requisitos mínimos de la plataforma.
-
Gracias a Spring Cloud + Eureka como gestor de registro y sincronización se constituye una estructura de microservicios dinámica y redundante, permitiendo una capa de personalización completa del sistema que permite la deslocalización y el equilibrio de prácticamente todos sus módulos, tanto internos como públicos.
-
A través del enfoque agnóstico ofrecido por la tecnología Spring JPA y la parte de personalización basada en microservicios de Spring Boot, estas piezas podrían sustituirse con facilidad por otras tecnologías con una funcionalidad similar.
-
Para monitorizar el ecosistema de microservicios, ANJANA DATA utiliza un panel de administración web Spring Boot Admin, a través del cual se puede conocer el estado y las métricas detalladas de cada servicio, ser observado, fácilmente consumido por el usuario o integrado en una monitorización externa plataforma.
-
En relación a la escalabilidad, el uso de tecnologías altamente eficientes multi-thread y la posibilidad de escalado horizontal prácticamente ilimitado en cada uno de sus componentes críticos, hacen que el volumen inicial de usuarios concurrentes y conjuntos de datos gobernados sea muy alto. En cifras: con la configuración recomendada, se pueden servir un volumen de 700 usuarios y un número de 100.000 activos de datos sin necesidad de realizar colas.
Tráfico interno con api gateway

-
ANJANA DATA utiliza la API Gateway para redirigir el tráfico interno de una manera muy eficiente. Así, por ejemplo, los controladores encargados de realizar tareas de sistema de bajo nivel ( listar tablas, crear directorios, etc), no están dentro de los backends, sino que son invocados por los microservicios.
-
Este diseño permite evolucionar la herramienta, en caso de que cualquier controlador esté obsoleto, desmontando y reemplazando el servicio en cuestión de la forma más efectiva.
Front-end con angular

-
Tanto el portal como el panel de administración presentan su capa de front-end construida en Angular
-
El uso de esta tecnología permite generar una interfaz amigable y totalmente operable por usuarios tanto técnicos como de negocio.
-
Completamente integrable con la tecnología de Back-end para ofrecer todas las funcionalidades que permitan un control completo de Anjana Data y sus módulos ( portal de datos, linaje, auditoría, creación/modificación, data marketplace, workflows, etc..)
-
Portal de administración totalmente manejable que permite configurar Anjana sin necesidad de escribir código o de acceder a bases de datos.
Tecnologías de almacenamiento






-
El uso de tecnologías open-source bien consolidadas permite reducir costes logrando una alta fiabilidad, interoperabilidad y evolución. ANJANA DATA utiliza PostgreSQL, SQLServer o Oracle para la capa de persistencia de datos y Apache SolR como motor de búsqueda.
-
El almacenamiento masivo de registros al ser realizado en SolR (en versiones posteriores se incluirá la incorporación de ElasticSearch), una tecnología específica basada en una redundancia y escalabilidad, es prácticamente ilimitado y fácilmente configurable.
-
Gestión documental, ficheros de configuración y traducción almacenados en MinIO o AWS S3, un servidor de almacenamiento que permite almacenar diversos tipos de datos estructurados y desestructurados.
-
La coordinación de procesos distribuidos se realiza de manera ágil y confiable gracias a la tecnología de Apache Zookeeper.
Autenticación y autorización




-
Anjana Data está diseñado para que el usuario pueda elegir sobre qué proveedor quiere autenticar y la autorización se hace con la configuración interna en base de datos configurable desde Portuno.
-
Protocolo LDAP: El módulo Zeus dispone de compatibilidad con servicio LDAP bien sea con esquemas OpenLdap o Active Directory.
-
Protocolo Oauth2 (OIDC Azure/AWS/GCP/Auth0) : El protocolo Oauth2 es un protocolo de autenticación la autorización ha de realizarse por otro circuito el cual varía en cada uno de los proveedores de Cloud:Bpm bajo estándar BPMN 2.0
|
CLOUD |
Autenticación |

|
Circuito Oauth2 mediante cliente OIDC Azure |

|
Circuito Oauth2 mediante cliente OIDC AWS |

|
Circuito Oauth2 mediante cliente OIDC GCP |

|
Circuito Oauth2 mediante cliente OIDC Okta-Auth0 |

Anjana Data incorpora Activiti como BPM open-source totalmente integrado en la solución soportando estándar BPMN2.0 gracias al cual se pueden diseñar e implementar workflows de validaciones totalmente customizados:
-
Los workflows se basan en el modelo de roles, unidades organizativas y permisos configurado y también está integrado con el módulo de alertas, mensajes y notificaciones para favorecer la colaboración entre los intervinientes.
-
En Anjana Data están disponibles workflows predefinidos, pero también se pueden crear workflows adicionales para la validación de las distintas acciones realizadas en Anjana Data (por tipo de objeto, por tipo de acción, por tipo de rol, por área de negocio, ...).
-
Para cada workflow se pueden configurar todos los pasos de validación (orden y rol/roles que validan) así como personalizar las notificaciones enviadas a los diferentes intervinientes para cada paso o incluso añadir acciones específicas soportadas por el estándar (ejecución de un script, lanzamiento de otra acción, envío de email, llamadas a APIs, ...).
-
Adicionalmente, se pueden configurar workflows complejos basados en los valores de los atributos de metadatos de un objeto (p.e. workflows distintos para activos que incluyan datos personales).
-
Todos los workflows con toda su información (pasos del workflow, estado, acciones, usuarios involucrados, etc) quedan trazados y pueden ser visualizados a través de la UI de Anjana Data donde también se puede filtrar para visualizar sólo los workflows de interés y acceder al detalle de cada workflow.
Mecanismos de integración e interoperabilidad
En referencia a la integración con diversas tecnologías, ANJANA DATA es completamente integrable e interoperable pudiéndose conectar con cualquier tecnología a través de los siguientes métodos:
-
Plugins y Agentes desarrollados por el equipo de Producto de Anjana Data, los cuales ofrecen integraciones nativas sobre diversas tecnologías, cubriendo diferentes modalidades de funcionamiento y opciones de configuración (ver detalle en integrations Zone).
-
Plugins y conectores desarrollados ad-hoc: Se proporciona un SDK (software development kit) que permite tanto a clientes como a partners desarrollar sus propios conectores de forma autónoma para implementar funcionalidades y usos requeridos específicos sin necesidad de alterar el producto.
-
Haciendo uso de las diferentes capas de API que proporciona Anjana Data, tanto para importar como para exportar la información deseada así como para ejecutar acciones concretas en la aplicación. En este sentido, Anjana Data cuenta con 3 capas de API: pública, administrativa y de configuración; cada una con un propósito específico y dirigida a unos perfiles diferentes.
Además, se añade la capacidad de ejecutar acciones personalizadas en la aplicación así como de lanzar scripts externos, gracias a las siguientes alternativas:
-
Haciendo uso de un interceptor interno y su correspondiente SDK, el cual se provee con Anjana Data
-
Mediante el uso del módulo de BPM, basado en Activiti, siguiendo el estándar BPMN 2.0, desde el cual, se puede definir cualquier tipo de workflow, en cuyos pasos se puede definir el lanzamiento de dichas acciones y/o scripts.
-
Haciendo uso de las diferentes capas de API que proporciona Anjana Data, de la misma manera que lo indicado anteriormente. En este sentido, el uso de las APIs puede ser orquestado por un planificador interno o ejecutarse a partir de triggers.
En cuanto a los Plugins, estos permiten que Anjana Data ejecute tanto acciones sobre los sistemas gobernados, como recuperar metadata e incorporar ésta en Anjana Data permitiendo la importación asistida y automática de metadatos.



API Restful con Swagger
Por último, para garantizar que Anjana Data es 100% interoperable, toda la solución está totalmente Apificada con API Restful con Swagger. Así, Anjana Data cuenta con tres capas de APIs que sirven a distintos propósitos:
-
Pública: La capa de API pública ofrece las funcionalidades de usuario para interactuar con Anjana, desde esta capa de API se puede acceder a los distintos módulos que ofrece la herramienta como son: Creación/modificación de objetos, linaje, histórico, auditoría, alertas y notificaciones y data marketplace.
-
Administrativa : Mediante la capa administrativa de API se puede gestionar el metamodelo en modo administrador, es decir, se pueden realizar modificaciones sobre el metamodelo (creación/modificación de objetos) sin necesidad de pasar por las validaciones definidas para los usuarios.
-
Configuración : Esta capa de configuración de API, permite gestionar la configuración de la herramienta en todas sus dimensiones:
-
Gestión de Unidades Organizativas, Roles y permisos.
-
Gestión de Usuarios.
-
Gestión de Objetos, workflows de validación y plantillas de atributos
-
Gestión de atributos y validaciones sobre atributos.
-
Gestión de filtros de búsqueda
-
Gestión de idiomas
-
Dashboarding

En cuanto a capacidades de reporting, Anjana Data incorpora Grafana como herramientas open-source de autoservicio y reporting totalmente integradas en su stack de arquitectura.
Dashboarding: El modelo de datos de Anjana Data es abierto, de esta manera la información contenida en la herramienta se puede extraer para su uso en cualquier herramienta de Dashboarding, como Grafana, Azure PowerBI Google Looker o Amazon QuickSight, entre otras.
Dashboarding con Grafana: Anjana Data ofrece, en su integración nativa con Grafana la posibilidad de construir reportes y cuadros de mando a medida de forma autónoma y dinámica sin necesidad de programar mediante funciones como clicks y drag & drops. Adicionalmente, Grafana aporta la capacidad de realizar análisis de series temporales y configuración de alertas en tiempo real que facilitan el seguimiento y gestión de la implantación del gobierno del dato así como de la calidad de los datos.
Cloud-first
Anjana Data funciona como una capa común para el gobierno de los datos agnóstica a la tecnología gracias a su enfoque centrado en los metadatos, al tiempo que ofrece integraciones nativas bidireccionales ampliadas sobre las tecnologías de plataformas de datos más comunes.
Como comentábamos anteriormente, esta visión la hace ideal para gobernar entornos y arquitecturas complejas, como puedan ser multi-cloud, híbridas, big data, etc, y la hace también estar preparada para las nuevas tecnologías, y/o nuevos usos de las tecnologías de la información que están por venir.
En cualquier caso, pese a esta visión, dado que la gran mayoría de organizaciones están evolucionando hacia un enfoque Cloud-first y son los proveedores de las principales nubes los que están marcando el devenir de las plataformas de datos y sus arquitecturas tecnológicas, Anjana Data aprovecha en este sentido las tecnologías y los enfoques nativos de la nube al tiempo que amplía sus capacidades mediante la integración nativa de la solución en las arquitecturas de las plataformas de datos más comunes.
Así pues, Anjana Data complementa y amplía las capacidades de los catálogos de datos nativos de la nube (AWS Glue Catalog, Azure Purview, GCP Data Catalog, ...) para ofrecer características avanzadas para la implementación de una gobernanza de datos proactiva y preventiva eficaz y eficiente mediante la automatización de procesos técnicos comunes.

En especial, para este tipo de ecosistemas, destacan los siguientes aspectos:
-
Arquitectura agnóstica, modular y flexible, pero integrada en los ecosistemas de la nube gracias a sus integraciones nativas con tecnologías y servicios nativos de los distintos proveedores de Cloud.
-
Enfoque Cloud-first para una escalabilidad y elasticidad ilimitadas mediante el uso de los servicios gestionados de las nubes que también facilitan el despliegue de servicios, así como el aprovisionamiento, la gestión y la operación de la infraestructura.
-
Gobierno de datos adaptado a las necesidades de la organización gracias a sus capacidades de personalización y flexibilidad.
-
Sin vendor lock-in, sin cajas negras y con un enfoque API-first, que ofrece plena interoperabilidad, así como herramientas de extensibilidad que facilitan el desarrollo de nuevas integraciones de forma autónoma.
-
Sistema de brokerage interno para la federación de la gestión de identidades y la delegación de la autenticación y la autorización en los sistemas de gestión de acceso e identidades nativos de la nube.
-
Acelera la adopción de arquitecturas de datos de nueva generación como Data Lakehouse, DataOps, Data Fabric, Data Mesh y Data Marketplace.
-
Alianzas y asociaciones estratégicas con Microsoft, AWS, Google y partner integradores expertos en Cloud, trabajando conjuntamente con los equipos de arquitectura de los distintos proveedores para aprovechar la evolución de sus tecnologías nativas.