
Modelo de integración
Extracción de metadatos
Se utilizan los métodos que ofrece el driver de JDBC mediante los cuales se accede a la definición de esquemas y tablas.
El plugin extrae los siguientes atributos que deben llamarse igual en la tabla attribute_definition, campo name para que aparezcan en la plantilla:
-
catalog con el valor de catalog en la base de datos
-
schema con el valor de schema en la base de datos
-
physicalName y name con el mismo valor, el nombre de la tabla
-
path con la concatenación de los valores de catalog, schema and table
-
infrastructure con el valor seleccionado
-
technology con el valor seleccionado
-
zone con el valor seleccionado
También envía los siguientes atributos relativos a los campos del recurso pedido:
-
name con el valor del campo correspondiente
-
physicalName con el valor del campo correspondiente
-
defaultValue con el valor por defecto definido para el campo correspondiente
-
fieldDataType con el tipo de dato definido para el campo correspondiente
-
length con el tamaño del campo correspondiente
-
incrementalField indicando si es un campo incremental
-
position posición que ocupa el campo correspondiente
-
precision con el valor de la precisión del campo correspondiente
-
nullable indicando si el campo correspondiente es nullable
-
pk indicando si el campo es una pk
-
description con el valor correspondiente para el campo
Los atributos a crear en Anjana deben de tener los siguientes tipos:
|
Nombre de atributo |
Tipo de atributo |
|
catalog |
INPUT_TEXT |
|
schema |
INPUT_TEXT |
|
physicalName |
INPUT_TEXT |
|
path |
INPUT_TEXT |
|
infrastructure |
SELECT |
|
technology |
SELECT |
|
zone |
SELECT |
|
name |
INPUT_TEXT |
|
defaultValue |
INPUT_TEXT |
|
fieldDataType |
INPUT_TEXT |
|
length |
INPUT_NUMBER |
|
incrementalField |
INPUT_CHECKBOX |
|
position |
INPUT_NUMBER |
|
precision |
INPUT_NUMBER |
|
nullable |
INPUT_CHECKBOX |
|
pk |
INPUT_CHECKBOX |
|
description |
ENRICHED_TEXT_AREA_INTERNATIONAL |
El plugin es capaz de realizar la extracción de metadatos sobre los tipos de elementos que se configuren para él. Por defecto se intentará extraer Tablas (TABLE) y Vistas (VIEW). Si la tecnología acepta otras, revisar el YAML mencionado en Configuración.
Documentación genérica de Java sobre los campos disponibles en JDBC si algún driver no disponibiliza su catálogo de metadata https://docs.oracle.com/javadb/10.10.1.2/ref/rrefcrsrgpc1.html
Muestreo de datos
Utilizando el driver genérico de JDBC de Java se ejecuta una query simple de SELECT para acceder a un número limitado de elementos de la tabla para recuperar una muestra de los datos almacenados. Adicionalmente se sustituyen los valores de los campos sensibles por asteriscos.
Si la muestra de datos se hace sobre una tabla del esquema default de Hive (o database por defecto), Anjana puede mostrar algún error debido a la discrepancia del nombre de las columnas que gestiona el driver y el nombre de las mismas en una consulta select. Esta discrepancia impide que se asocie de manera correcta el valor con la columna representada en Anjana.
Vendors disponibles
Para cada vendor se detalla qué versiones se soportan, el formato de conexión, y que permisos se requieren para las funcionalidades del plugin (extracción y sampleo de datos).
Oracle
Soporte
Soporte de la versión 19.X hasta la 23.3, con compatibilidad hacia atrás a la 12.1 (sin embargo ya no tiene soporte oficial con versiones anteriores a la 19.X, no se certifica el completo funcionamiento).
Configuración
Vendor
ORACLE
Formato de la conexión
El formato de la url de conexión por BD o SID es jdbc:oracle:thin:@<host>:<puerto>:<nombre_bbdd o sid>.
El formato de la url de conexión service name jdbc:oracle:thin:@<host>:<port>/<service_name>.
Permisos
Usuario o rol con permisos SELECT o READ sobre las tablas o vistas que se quieran extraer metadatos u obtener un muestreo de datos. La diferencia es que el SELECT permite bloquear los registros durante el sampleo (si se configura la query para eso).
Si se quiere dar acceso a todas las tablas del sistema para gobernar, se puede dar el rol predefinido SELECT_CATALOG_ROLE.
Extracción de metadatos
A continuación se adjunta la documentación de Oracle donde se observan los distintos campos que se extraen de las tablas *:
*Importante → Para algunos tipos de columnas la longitud observada en la tabla puede variar con respecto a la extraída por Anjana, revisar la documentación anteriormente indicada.
SQL Server
Soporte
Soporte desde SQL Server 2016 a SQL Server 2019.
Configuración
Vendor
MSSQLSERVER
Formato de la conexión
El formato de la url de conexión es
jdbc:sqlserver://<database host><instance_name>:<port>;database=<database_name>
Permisos
Usuario o rol con permisos SELECT sobre las tablas o vistas que se quieran obtener un muestreo de datos.
Usuario o rol con permisos VIEW DEFINITION sobre las tablas o vistas que se quieran extraer el metadata.
También se puede aplicar sobre esquemas o base de datos directamente y aplicará a todo lo que contiene.
Extracción de metadatos
A continuación se adjunta la documentación de SQLServer donde se observan los distintos campos que se extraen de las tablas *:
*Importante → Para algunos tipos de columnas la longitud observada en la tabla puede variar con respecto a la extraída por Anjana, revisar la documentación anteriormente indicada.
PostgreSQL
Soporte
Soporte de la 8.2 hasta la versión 13.
Configuración
Vendor
POSTGRESQL
Formato de la conexión
El formato de la url de conexión es jdbc:postgresql://<database_host>:<port>/database=<database>
Permisos
Usuario o rol con permisos USAGE sobre el esquema que contiene las tablas que se gobiernan y el permiso SELECT sobre cada tabla que se quiera hacer extracción de metadata y muestreo de datos.
Snowflake
Soporte
Al ser tecnología cloud, se soporta hasta la versión más reciente a la hora de la redacción de este documento, que es la versión de Julio de 2023.
Configuración
Vendor
SNOWFLAKE
Formato de la conexión
El formato de la url de conexión es jdbc:snowflake://<orgname>-<account>.snowflakecomputing.com/?db=<database>&warehouse=<warehouse>
Permisos
Usuario o rol con permisos USAGE sobre la base de datos y el esquema donde están las tablas/vistas que se quieren gobernar.
Usuario o rol con permisos REFERENCE sobre las tablas o vistas que se quieran extraer el metadata.
Usuario o rol con permisos SELECT sobre las tablas o vistas que se quieran obtener un muestreo de datos.
Extracción de metadatos
A continuación se adjunta la documentación de Snowflake donde se observan los distintos campos que se extraen de las tablas *:
https://docs.snowflake.com/en/developer-guide/jdbc/jdbc-api#object-databasemetadata
*Importante → Para algunos tipos de columnas la longitud observada en la tabla puede variar con respecto a la extraída por Anjana, revisar la documentación anteriormente indicada.
Hive standalone
Soporte
Soporte con hive 2.3.9.
Configuración
Vendor
HIVE_APACHE
Formato de la conexión
El formato de la url de conexión directo a hive server es jdbc:hive2://<databse_host>:<database_port>/<database>;principal=<principal>;ssl=true.
El formato de la url de conexión por HTTP es jdbc:hive2://<databse_host>:<database_port>/<database>;principal=<principal>;ssl=true;transportMode=http;httpPath=cliservice.
Permisos
Usuario o rol con permisos SELECT sobre las tablas o vistas que se quieran obtener un muestreo de datos o extracción de metadata.
Hive en entorno Cloudera
Soporte
Soporte en entornos cdh desde 6.0 a 6.3 o cdp 7.0 y 7.1 con hive 1.0 hasta 3.1.
Configuración
Vendor
HIVE_CLOUDERA
Formato de la conexión
El formato de la url de conexión directo a hive server es jdbc:hive2://<databse_host>:<database_port>/<database>;principal=<principal>;ssl=true.
El formato de la url de conexión por HTTP es jdbc:hive2://<databse_host>:<database_port>/<database>;principal=<principal>;ssl=true;transportMode=http;httpPath=cliservice.
El formato de la url de conexión por zookeeper es jdbc:hive2://<databse_host>:<database_port>/<database>;principal=<principal>;ssl=true;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2.
Permisos
Usuario o rol con permisos SELECT sobre las tablas o vistas que se quieran obtener un muestreo de datos o extracción de metadata.
DB2
Soporte
Soporte desde versiones 10.1 hasta 11.5.
Configuración
Vendor
DB2
Formato de la conexión
El formato de la url de conexión es
jdbc:db2://<database_host>:<port>/<database>.
Permisos
En el caso de que no se quiera dar acceso al esquema completo el usuario o rol que se utilice necesita el permiso SELECT sobre las tablas sobre las que se quiera extraer metadata o hacer muestreo de datos.
A partir de la versión 11.5 se pueden dar permisos sobre un esquema completo para poder extraer metadata o muestreo de datos, se necesita un usuario o rol con el permiso SELECTIN sobre el esquema.
Extracción de metadatos
A continuación se adjunta la documentación de IBM para db2 donde se observan los distintos campos que se extraen de las tablas *:
https://www.ibm.com/docs/en/db2-for-zos/12?topic=functions-sqlcolumns-get-column-information
*Importante → Para algunos tipos de columnas la longitud observada en la tabla puede variar con respecto a la extraída por Anjana, revisar la documentación anteriormente indicada.
MySQL
Soporte
Soporte de MySQL 5.7 y 8.0.
Configuración
Vendor
MYSQL
Formato de la conexión
El formato de la url de conexión es
jdbc:mysql://<database_host>:<port>/<database>.
Para el driver de mysql los schemas son catalogs y viceversa, es decir, para crear schemas hay que configurar la propiedad de using-catalogs a true y la de using-chemas a false.
Permisos
Usuario o rol con permisos SELECT sobre las tablas o vistas que se quieran extraer metadatos u obtener un muestreo de datos.
MariaDB
Soporte
Soporte desde 5.5.3 a 11.0.
Configuración
Vendor
MARIADB
Formato de la conexión
El formato de la url de conexión es
jdbc:mariadb://<database_host>:<port>/<database>.
Para el driver de mariadb los schemas son catalogs y viceversa, es decir, para crear schemas hay que configurar la propiedad de using-catalogs a true y la de using-chemas a false.
Permisos
Usuario o rol con permisos SELECT sobre las tablas o vistas que se quieran extraer metadatos u obtener un muestreo de datos.
También se puede aplicar sobre la base de datos directamente o incluso el servidor entero y aplicará a todo lo que contiene.
Teradata
Soporte
Soporte desde 16.20 hasta 20.0
Configuración
Vendor
TERADATA
Formato de la conexión
El formato de la url de conexión es
jdbc:teradata://<database_host>:<port>/<params>
En ocasiones el puerto o la base de datos puede ser un problema y se puede usar la url en este formato jdbc:teradata://<database_host>/DATABASE=<databse>,DBS_PORT=<port>
Permisos
Usuario o rol con permisos SELECT sobre las base de datos, tablas o vistas que se quieran extraer metadatos u obtener un muestreo de datos.
En el caso que la tabla contenga UDTs será necesario que el usuario tenga permisos también sobre los procedimientos correspondiente (SYSUDTLIB.X, siendo X el nombre del procedimiento)
Extracción de metadatos
A continuación se adjunta la documentación de Teradata donde se observan los distintos campos que se extraen de las tablas *:
https://teradata-docs.s3.amazonaws.com/doc/connectivity/jdbc/reference/current/frameset.html
*Importante → Para algunos tipos de columnas la longitud observada en la tabla puede variar con respecto a la extraída por Anjana, revisar la documentación anteriormente indicada.
Configuración
En la Configuración técnica y en Tot despliegue de plugins hay algunas directrices.
Existe un YAML de ejemplo para facilitar la configuración en Nexus / com / anjana / documentation (necesario login previo) con explicaciones de las propiedades y valores por defecto.
Este plugin puede conectarse a varias instancias de la misma tecnología, también se puede ver el YAML de ejemplo.
Ajustes específicos para Hive
Para la ejecución de consultas JDBC contra Hive se tienen que realizar una serie de ajustes en la JVM
-
Uso de autorización Kerberos
-
SSL
Ajustes SSL de la JVM
Cloudera necesita securizar las conexiones con SSL para poder utilizar Kerberos. La solución que utiliza por defecto es desplegar su propia CA autofirmada en un contenedor JKS utilizando unas propiedades análogas a estas:
-Djavax.net.ssl.keyStore=/....../....../cm-auto-host_keystore.jks
-Djavax.net.ssl.keyStoreType=jks -Djavax.net.ssl.trustStore=/....../...../cm-auto-global_truststore.jks
-Djavax.net.ssl.trustStoreType=jks
Hay dos opciones
-
Que las rutas sean proporcionadas al integrador por el Cliente
-
Añadir la CA autofirmada de Cloudera al contenedor de certificados por defecto de la JVM
Rutas proporcionadas
La JVM del plugin se deberá ejecutar con los siguientes parámetros:
|
Parámetro |
Valor |
|
-Djavax.net.ssl.keyStore |
Ruta donde se encuentra el almacén de claves privadas. |
|
-Djavax.net.ssl.keyStoreType |
jks |
|
-Djavax.net.ssl.trustStore |
Ruta donde se encuentra el almacén de certificados. |
|
-Djavax.net.ssl.trustStoreType |
jks |
Añadir la CA autofirmada al contenedor de certificados de la JVM
Lo que se persigue es añadir en cacerts de Java el certificado autofirmado de Cloudera
keytool -importkeystore -srckeystore /var/lib/cloudera-scm-agent/agent-cert/cm-auto-global_truststore.jks -destkeystore /etc/ssl/certs/java/cacerts -srcstorepass -deststorepass changeit -v
Este sistema tiene la ventaja de que no precisaría añadir parámetros adicionales a la JVM.
Ajustes Kerberos de la JVM
Se necesita proporcionar a la JVM el mecanismo para la utilización automática de los tickets de Kerberos.
Para ello debemos lanzar la JVM con los siguientes parámetros.
-
-Djava.security.auth.login.config=security.config
-
-Djavax.security.auth.useSubjectCredsOnly=false
Teniendo el fichero security.config la siguiente estructura:
com.sun.security.jgss.initiate {
com.sun.security.auth.module.Krb5LoginModule required
useTicketCache=true
StoreKey=true
useKeyTab=true
keyTab="/home/ubuntu/usr_anjana.keytab"
principal="usr_anjana@CDP.LOCAL";
};
Los parámetros keytab y principal se nos han de suministrar
Errores comunes
Si las tablas de Hive están encriptadas devuelve este log de error
No Route to Host from ip-10-202-21-147.eu-west-1.compute.internal/10.202.21.147 to ip-10-202-21-122.eu-west-1.compute.internal:8020 failed on socket timeout exception: java.net.NoRouteToHostException
⚠️ Nota
Si, al ejecutar la extracción de metadato conectando con una base de datos de Oracle sale el siguiente error:
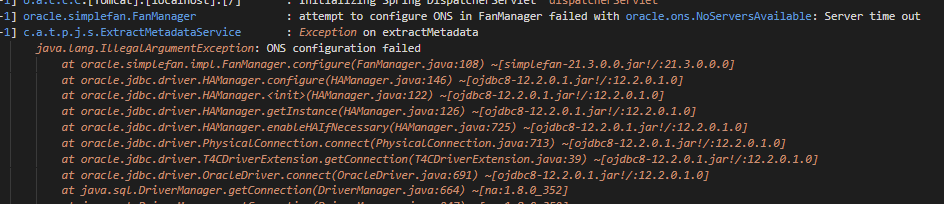
Es necesario incluir en el comando de ejecución del descriptor de servicio del plugin “-Doracle.jdbc.fanEnabled=false” (info del problema: https://support.oracle.com/cloud/faces/DocumentDisplay?_afrLoop=190836230347481&_afrWindowMode=0&id=2616175.1&_adf.ctrl-state=qk122q2vr_4)