
Despliegue de entorno single node
Para el despliegue de un entorno single node de Anjana será necesario seguir los pasos descritos en el apartado Despliegue de Anjana. Esos pasos se pueden resumir en los siguientes, pero igualmente será necesario seguir el apartado para más detalle:
-
Crear o tener una máquina virtual disponible de acuerdo a las recomendaciones.
-
Solicitar los accesos y credenciales.
-
Plataformar los entornos de acuerdo a lo documentado.
-
Clonar el inventario adecuado para crear el inventario definido en el script de plataformado:
-
localhost: cuando el kit de ansible se sitúe en la misma máquina donde se instalará el producto.
-
sample: cuando el nodo de ansible es un nodo distinto al de Anjana.
-
-
Realizar los ajustes requeridos.
-
Editar en el fichero all.yml del inventario elegido la versión deseada para el despliegue de Anjana de acuerdo a las indicaciones.
-
Lanzar ansible para el despliegue del producto con o sin datos de ejemplo según la necesidad.
AWS S3 como sustituto de MinIO
Los buckets en AWS S3 se manejarán de igual manera que como se haría con los buckets en MinIO, siendo posible personalizar la región y nombre de los buckets a los que se quiere conectar.
Más detalles sobre la conexión a AWS S3 pueden encontrarse en el apartado de Integraciones Cloud, Buckets en AWS S3.
PostgreSQL RDS como sustituto de PostgreSQL
La conexión a un RDS no tendrá prácticamente diferencias, dado que solo es necesario alterar el host y puerto de conexión.
Más detalles sobre la conexión a RDS pueden encontrarse en el apartado de Integraciones Cloud, PostgreSQL en RDS.
Despliegue de entorno balanceado
Para el modo de despliegue distribuido y balanceado de Anjana será necesario contar con las siguientes máquinas:
-
2 VM Front + Back
-
1 VM Tot + Plugins
-
1 VM Solr + Zookeeper
-
4 VM MinIO (Cluster) o AWS S3
-
PostgreSQL RDS
-
1 VM ansible manager (opcional)
⚠️IMPORTANTE:
-
La alta disponibilidad no viene dada por el producto, sino por la infraestructura. El producto solo ofrece balanceo.
-
Tot y los plugins no necesitan balanceo
-
PostgreSQL no puede ser balanceado en su versión auto hospedada debido a su complejidad técnica. Se recomienda el uso de PostgreSQL RDS en caso de necesitar balanceo o alta disponibilidad.
-
Solr y Zookeeper no requieren de balanceo o alta disponibilidad para su caso de uso
A continuación se seguirán los pasos descritos en el apartado Despliegue de Anjana a excepción del lanzamiento de Ansible para el despliegue de Anjana, ya que será necesario completar unos pasos previos.
Una vez realizados los pasos, teniendo en cuenta que:
-
Ya se cuenta con las credenciales y accesos necesarios.
-
Ya se ha descargado el script y se han plataformado los nodos que compondrán el entorno de Anjana (todas las VM mencionadas anteriormente).
-
Ya se cuenta con un inventario personalizado para el entorno.
-
Ya se ha ajustado el fichero hosts.yml para incluir las IPs y demás datos de todos los nodos del entorno.
-
Ya se ha ajustado el fichero all.yml para determinar la versión o versiones elegidas para el despliegue así como los roles de ansible que participarán en el entorno.
A continuación se siguen los siguientes apartados para ajustar las persistencias de acuerdo a lo necesario.
🛈NOTA: cabe recordar, que de acuerdo al apartado de Integraciones Cloud, en caso de haber decidido que PostgreSQL y MinIO serán sustituidos por RDS y AWS S3 respectivamente, los roles de PostgreSQL y MinIO deberán ser deshabilitados para evitar su importación y posterior instalación.
MinIO (Cluster)
Para MinIO en modo cluster habrá que editar el fichero miniohosts.yml en el inventario para ajustar los volúmenes a los cuatro nodos que hay disponibles.
Se comentará la opción de volumes para el modo Standalone y se descomenta y ajusta la línea de volumes para MinIO cluster.
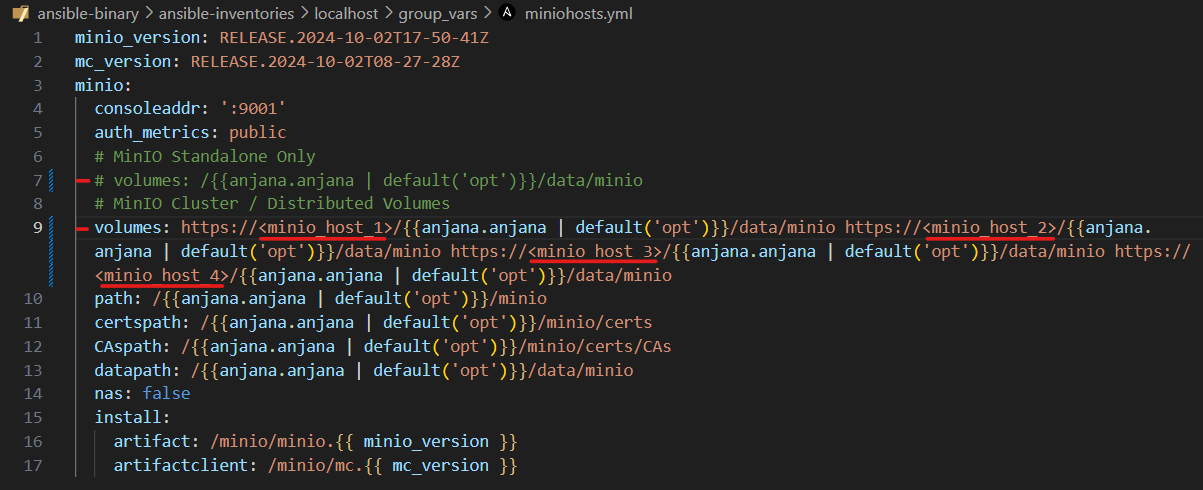
⚠️IMPORTANTE: La carpeta de datos de un MinIO Cluster debe ser un disco montado o saldrá el siguiente error en los logs de ejecución:

Acto seguido, será necesario descomentar en el fichero anjanauihosts.yml los nodos adicionales para el balanceador de MinIO y editarlos para que correspondan a los nodos existentes:
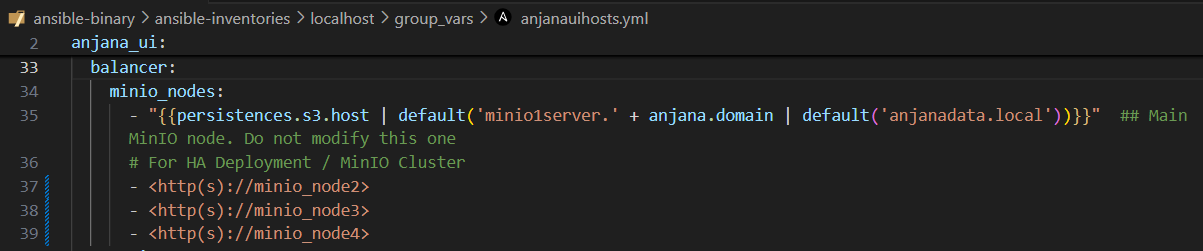
✅RECOMENDADO: para reducir la complejidad de despliegue de un cluster de MinIO y su coste, el uso de su equivalente en Cloud, en este caso AWS S3 para disponer de balanceo y alta disponibilidad.
Ahora si, una vez ajustado todo lo necesario para desplegar el producto, se procede a la instalación mediante el kit de ansible.
✅RECOMENDADO: lanzar el comando de ping de Ansible para comprobar la conectividad con los nodos del entorno antes de iniciar la instalación:
sudo ansible -i /opt/ansible/ansible-inventories/<inventario>/hosts.yml all -m ping
Para instalar Anjana con datos de ejemplo:
anjana -t anjana-sample
Para instalar Anjana sin datos de ejemplo:
anjana
Multi instancia de plugin
Para generar una segunda instancia de un plugin existente, serán necesarios los siguientes pasos:
-
Duplicar el template de configuración y el descriptor de servicio del plugin escogido en el inventario en uso tantas veces como instancias nuevas se quieran crear, añadiendo la numeración apropiada.
🛈NOTA: si ambas instancias van a usar la misma configuración, duplicar el template de configuración no es necesario.
Deberá quedar como a continuación:
-
Añadir en el fichero hosts.yml del inventario tantas entradas nuevas del plugin seleccionado como instancias del mismo plugin se quieran añadir, cambiando el puerto, nombre del servicio, perfil de configuración e índice (necesario para las utilidades como start/stop).
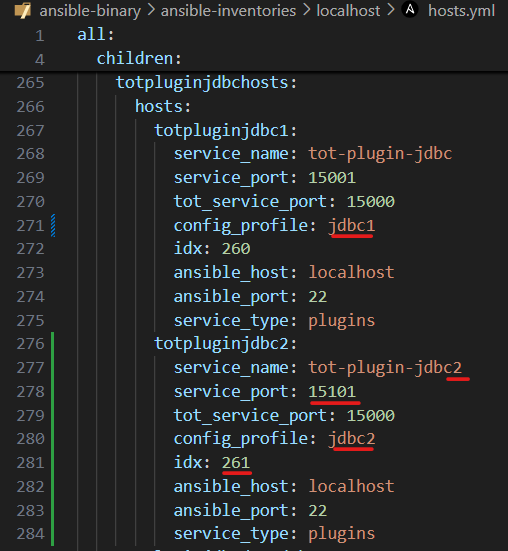
⚠️IMPORTANTE: el nombre del perfil de configuración no puede ser default en ninguna de las instancias del plugin, de lo contrario, todas las instancias recuperarán ese perfil de configuración por defecto.
-
En caso de que la configuración de la segunda instancia sea diferente, también será necesario modificar el perfil de configuración para que se aplique correctamente.
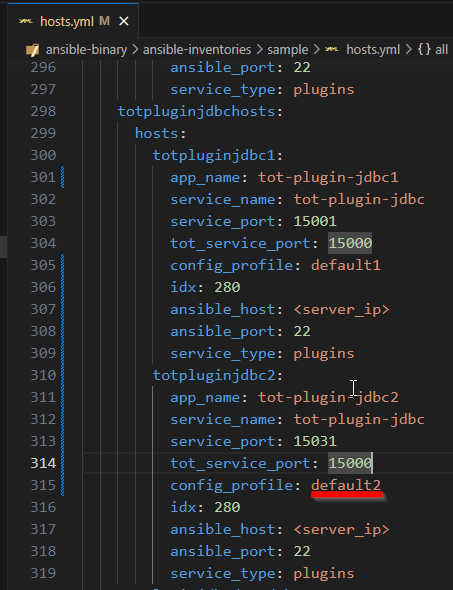
Una vez ajustado todo, se lanzará la actualización de la configuración con el comando:
anjana -t update-config
Para desplegar la nueva instancia, será necesario lanzar el role del plugin con el siguiente comando:
anjana -t tot-plugin-<plugin>
🛈NOTA: será necesario tener en cuenta los siguientes puntos para el kit de ansible cuando se trata de multi-instancias:
-
No es posible deshabilitar la importación del role en el fichero all.yml para una sola instancia, cuando se ejecute el tag del plugin correspondiente, se importará el role una vez por cada instancia hasta que se haya aprovisionado todas.
-
No es posible seleccionar una sola instancia para las operaciones de actualización de configuración y jar de plugins, se llevarán a cabo sobre todas las instancias disponibles.
-
No es posible seleccionar una sola instancia para las operaciones de arranque y parada de plugins, o el entorno, se llevarán a cabo sobre todas las instancias disponibles.
Despliegue de entorno Anjana + plugins standalone
En este caso de uso se contemplará la instalación de un entorno de Anjana singlenode a excepción de Tot+Plugins, que irán alojados en una máquina aparte.
Para ello se seguirán los pasos descritos en el apartado Despliegue de Anjana como si el despliegue fuera un entorno distribuido, ya que así lo será por la parte de Tot+Plugins, teniendo en cuenta los ajustes adicionales, que se detallan a continuación:
-
Se habilitará en el fichero all.yml en la sección de import_role todos los plugins que se quieran desplegar de acuerdo a lo mencionado en la sección Importación de roles y configuración.
-
Se editará en el fichero all.yml la propiedad anjana.plugins_config.standalone para establecerla a true de acuerdo a lo mencionado en el apartado configuración de instalación.
Una vez realizados dichos cambios ya será posible continuar con los pasos de instalación.
🛈NOTA: será necesario tener en cuenta los siguientes puntos cuando se trabaja con plugins en formato standalone:
-
No será posible deshabilitar horus aunque los plugins no lo necesiten, ya que el resto de microservicios dependen de él.
-
El directorio de configuración es el indicado en el all.yml de acuerdo al apartado configuración de instalación. Su modificación afectará tanto a los plugins standalone como los microservicios de Anjana.
-
La configuración de los plugins standalone es depositada en el mismo directorio de configuración que el resto de microservicios, pero en la máquina donde se ubica cada plugin.
-
Si se ubica el directorio de configuración fuera de la(s) máquina(s) donde se encuentren los plugins, no será alcanzable por los mismos a no ser que se trate de un almacenamiento externo montado.
Clonado de un entorno PRE a PRO
Para este caso de uso se va a tomar como punto de partida un entorno preexistente PRE, cuyos datos quieren ser migrados a otro entorno PRO.
Es posible realizar un clonado de las persistencias y la configuración haciendo uso de la funcionalidad o tag clone.
Preparación para el clonado
Se toma como punto de partida que se han cumplido los siguientes requisitos:
-
Se ha establecido installation.mode a manager en el fichero all.yml.
-
Se dispone de credenciales y acceso a los repositorios de Anjana y están correctamente configurados.
-
Todas las cadenas de conexión pertenecientes a las persistencias están correctamente ajustadas. Para más información se puede seguir el apartado Cadenas de conexión.
En caso de dudas con respecto al fichero all.yml puede consultarse el apartado All.yml explicado.
Clonado de datos + configuración
Todos los datos de las persistencias y la configuración de los microservicios y plugins de Anjana serán respaldados mediante el uso del siguiente comando:
anjana -t clone
🛈NOTA: todos los ficheros resultantes serán depositados en la máquina manager en el directorio /opt/export-import, por defecto. Se generará un comprimido para que pueda ser transportado con facilidad.
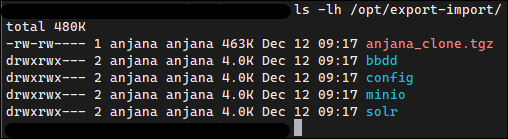
Para poder transferir los datos a la máquina destino, se lanzan los siguientes comandos:
scp -i /<user>/.ssh/<key>.pem <user>@<origen>:/opt/export-import/anjana_clone.tgz /<ruta_local>
scp -i /<user>/.ssh/<key>.pem /<ruta_local> <user>@<destino>:/tmp/anjana_clone.tgz
sudo mv /tmp/anjana_clone.tgz /opt/export-import/anjana_clone.tgz
🛈NOTA: el directorio /opt/export-import deberá existir en la máquina destino.
Restauración de los datos
Para ejecutar la restauración de los datos, tras situarse en la máquina de destino(PRO) pueden darse dos casos:
CASO 1 - Restauración en un entorno nuevo
En caso de que la restauración se ejecute en un entorno o máquina de nueva creación será necesario desplegar Anjana y todas las persistencias, sin datos, para posteriormente rellenarlas con los datos clonados.
Para ello, después de situarse en la máquina destino, habría que descargar y ajustar el kit de ansible para desplegar Anjana, mediante el comando sin tags:
anjana
CASO 2 - Restauración en un entorno existente
En caso de que la restauración tenga lugar en un entorno con un Anjana desplegado será necesario comprobar los siguientes puntos:
El entorno de destino donde se realizará la restauración tiene que tener la misma versión de Anjana que el entorno de origen de los datos. En caso de que haya discrepancias será necesario ajustar las versiones en el fichero all.yml y posteriormente actualizar con el comando:
anjana -t update
El proceso de restauración no sobrescribe ni borra los datos, por lo que es necesario realizar un borrado previo de los datos y la configuración, lanzando el siguiente comando:
anjana -t delete,delete-config
Una vez finalizadas las tareas y requisitos de acuerdo al caso en el que se encontrase el entorno, para proceder a la restauración de los datos, el comprimido .tgz generado en el proceso de clonación tiene que encontrarse en la ruta definida en el archivo de variables mencionado anteriormente, por defecto /opt/export-import/anjana_clone.tgz.
⚠️IMPORTANTE: será necesario tener en cuenta los siguientes puntos:
-
Los buckets de S3 tienen que estar creados previamente y coincidir con los nombres especificados en el all.yml en caso de que se hayan modificado.
-
El proceso de clonado y restauración de los datos no transfiere los cambios realizados en el servidor web. Si se han realizado modificaciones o personalizaciones en las configuraciones de apache2, necesitarán ser transferidas o copiadas manualmente.
Para la restauración general se lanzará el siguiente comando:
anjana -t deploy
Para la restauración individual de persistencias y/o configuración:
anjana -t deploy-s3
anjana -t deploy-bbdd
anjana -t deploy-config
Tras la restauración de los datos se recomienda reiniciar el entorno con:
anjana -t restart