Introducción
El presente documento constituye la Guía de Configuración Funcional de Anjana Data, cuyo objetivo es servir de referencia para adaptar la plataforma a los requerimientos de cada organización. A lo largo de esta guía se detallan los pasos y consideraciones necesarias para parametrizar los distintos componentes que conforman el modelo de gobierno de datos en Anjana Data.
En concreto, se abordan los siguientes aspectos de configuración:
-
Modelo operativo de gobierno: definición de roles, permisos, dominios de datos, workflows, reglas de lanzamiento de workflows y notificaciones que garantizan el funcionamiento coordinado del gobierno de datos.
-
Metamodelo: configuración del modelo entidad–relación que permite gobernar los distintos tipos de activos de datos e información gestionados por la organización.
-
Plantillas de metadatos: creación y ajuste de menús, secciones y atributos de diferentes tipologías, incluyendo validaciones y reglas de versionado para asegurar calidad y control de impactos.
-
Linaje: parametrización de las capas de linaje, especificando qué entidades y relaciones del metamodelo pertenecen a cada capa y qué relaciones deben representarse como relaciones de agregación.
-
Filtros: configuración de filtros en la pantalla del Buscador de objetos y en la pantalla de Auditoría del Portal de Datos, con el fin de optimizar la navegación y la consulta de información.
Esta guía está dirigida a perfiles responsables de la administración funcional de la plataforma. El administrador funcional no necesariamente define el modelo de configuración, pero sí es el encargado de parametrizarlo y mantenerlo actualizado dentro del Panel de configuración.
Conceptos básicos para la configuración de Anjana Data
Antes de comenzar con la configuración funcional de la plataforma, es importante que los perfiles responsables de la administración comprendan una serie de conceptos fundamentales. Estos términos son la base para interpretar correctamente los apartados de esta guía.
Para una descripción detallada de cada uno de ellos, se recomienda consultar el Glosario de términos de Anjana Data.
Principales conceptos
-
Dominio de datos / dominio funcional / dominio de negocio / unidad organizativa: estructuras que permiten organizar y segmentar los activos de datos dentro de la organización, y que sirven como base para aplicar los mecanismos de autorización que determinan qué usuarios ejercen roles de gobierno sobre dichos activos.
-
Roles de gobierno: funciones y responsabilidades asignadas a los diferentes perfiles en el modelo de gobierno de datos.
-
Permisos: autorizaciones específicas que determinan qué acciones puede realizar un usuario sobre los distintos objetos de la plataforma.
-
Workflows: flujos de trabajo configurables que soportan los procesos de validación de las acciones de gobierno, desde la creación hasta la autorización de acceso a activos de datos.
-
Notificaciones: alertas automáticas que informan a los usuarios sobre cambios, solicitudes o acciones pendientes en la plataforma.
-
Usuarios: personas con acceso a la plataforma. Cada usuario puede tener asignados uno o varios roles de gobierno, y sus permisos son aditivos, es decir, disponen de la suma de todos los permisos asociados a sus roles.
-
Metamodelo: estructura conceptual que define qué entidades y relaciones se gobiernan en la plataforma.
-
Entidad: elemento del metamodelo que representa un activo de datos o información (ej. dataset, informe, modelo de IA, tratamiento de datos…).
-
Relación: vínculo entre dos entidades que refleja dependencias, jerarquías o asociaciones.
-
Tipo de objeto: En Anjana Data, el tipo de objeto se refiere a la clasificación básica de los elementos gobernados dentro del metamodelo. Dado que el metamodelo está compuesto por entidades y relaciones, el tipo de objeto permite discriminar si se trata de una entidad (ej. dataset, informe, modelo de IA) o de una relación (ej. término de negocio relacionado, metricas del informe…).
-
Subtipo de objeto: Especifica la categoría concreta de un objeto dentro del metamodelo: por ejemplo, un dataset o un término en el caso de entidades, o una dependencia o agregación en el caso de relaciones.
-
Linaje: capacidad para trazar el recorrido y la transformación de los datos a lo largo de su ciclo de vida.
-
Capa de linaje: nivel dentro del linaje que agrupa entidades y relaciones según su función (ej. capa de técnica, capa de consumo, capa semántica…).
-
Relación de agregación: relación del metamodelo que muestra dependencias de agrupación entre entidades en una capa concreta de linaje.
-
Auditoría: módulo que registra y permite consultar todas las acciones realizadas en la plataforma o en plataformas externas.
-
Portal de datos: interfaz de negocio orientada a la consulta, solicitud de acceso a datos y colaboración sobre activos de datos.
-
Filtros: criterios configurables que facilitan la búsqueda y selección de objetos en pantallas como el Buscador de objetos o la Auditoría.
-
Claves de traducción: Permiten configurar la aplicación en varios idiomas, de modo que cada usuario visualice roles, dominios, plantillas, atributos y notificaciones en el idioma que tenga seleccionado.
Mecanismos para la configuración
Existen dos formas de configurar Anjana Data:
1. Desde el Panel de configuración (opción recomendada) (Visión administrador)
El Panel de configuración permite introducir toda la parametría necesaria para realizar la configuración funcional y gran parte de la configuración técnica.
-
Es la opción recomendada porque implementa reglas de validación y aplica de forma automática gran parte de la lógica de configuración, reduciendo el riesgo de error.
-
Para operar en el Panel de configuración, el usuario debe contar con los roles y permisos adecuados sobre el modelo de datos de la aplicación:
-
ADMIN_ANJANA: permiso de acceso al Panel de configuración y a las tablas que contienen la parametría de configuración funcional. -
CREDENTIAL_ADMIN_ANJANA: permiso de acceso a las tablas de autenticación y autorización (este permiso no da acceso al Panel de configuración). -
API_ADMIN_ALL: permiso de acceso a acciones especiales (ej. borrar cachés, cargar linaje, actualizar secuencias).
-
Nota: En ocasiones se puede aludir internamente al Portal de configuración como Portuno, ya que este es el nombre del microservicio asociado a las capacidades de configuración de la plataforma
2. Mediante acceso directo a la base de datos (Visión desarrollador)
Esta mecánica implica que toda la parametría de configuración se establece mediante queries SQL que se ejecutan contra el modelo de datos interno de Anjana Data. Para poder realizar la configuración, el usuario debe tener acceso a la base de datos mediante un gestor de base de datos (por ejemplo: Dbeaber)
Esta opción de configuración se desaconseja ya que:
-
Todo el peso de la lógica de configuración recae en el desarrollador que ejecuta queries SQL directamente sobre las tablas internas de la plataforma.
-
Incrementa el riesgo de inconsistencias, al no contar con las validaciones que ofrece el Panel de configuración.
-
Requiere ejecutar un script de actualización de secuencias en las tablas de BD tras cada operación de configuración. (Este mismo procedimiento puede realizarse desde el Panel de configuración en
Actions > Reset DQ sequences).
Configuración mediante el Panel de configuración(opción recomendada) (Visión administrador)
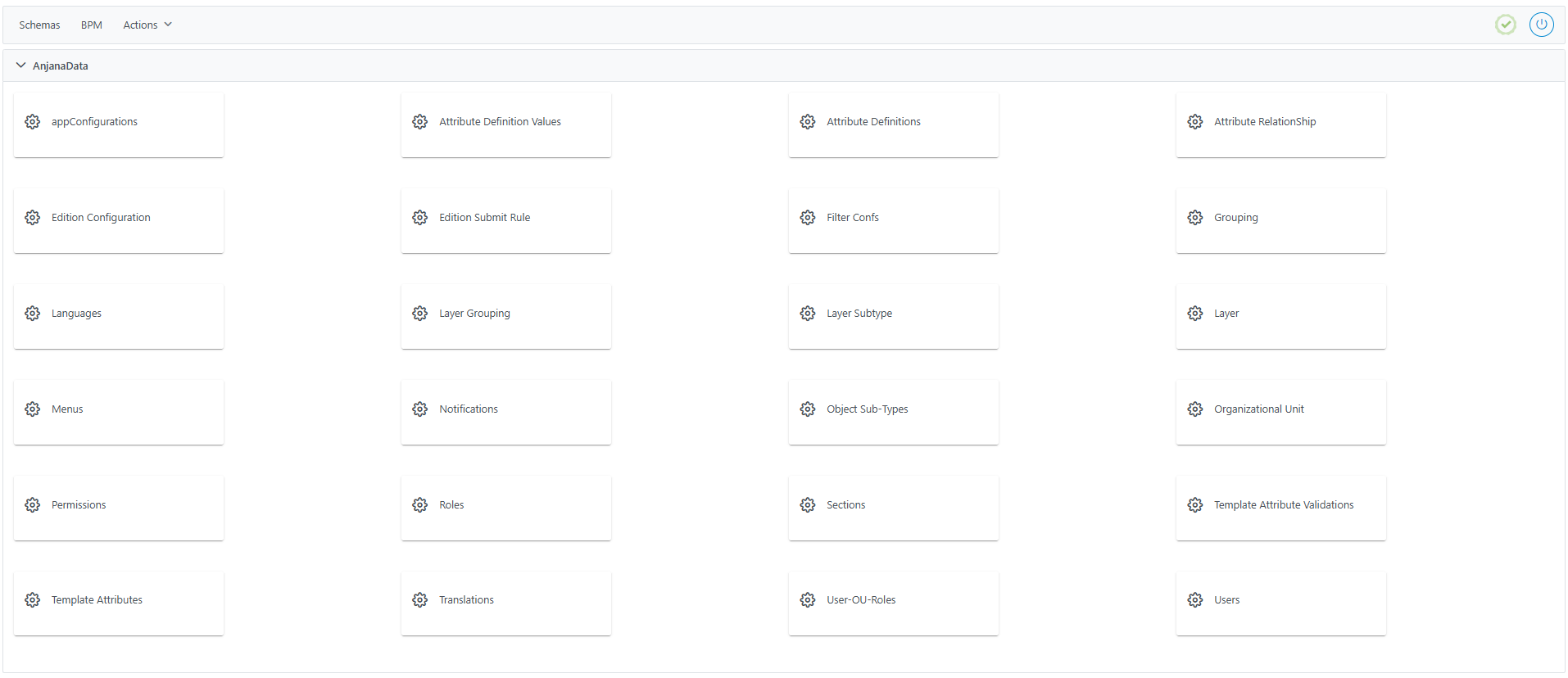
Dentro del panel de configuración, el administrador tiene acceso a los siguientes recursos y acciones:
-
Schemas: acceso al contenido de las tablas de configuración funcional de Anjana Data
-
BPM: acceso al editor de workflows (más información en la Guía de configuración de Workflows)
-
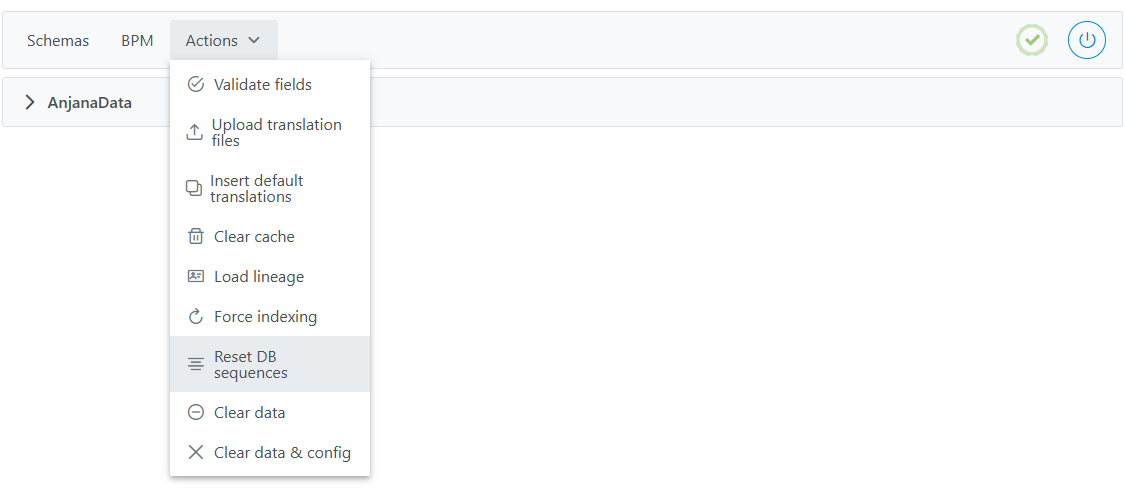
Actions: El desplegable habilita la ejecución de las siguientes acciones:
-
Validate fields (
Actions > Validate fields): acción que permite comprobar si los atributos que forman parte de la PK de los objetos tienen configuradas las validaciones de atributo requerido y no editable y que los valores configurados para los atributos de tipo taxonomía generan árboles correctos (sin ciclos, por ejemplo). Antes de lanzar esta validación es necesario limpiar la caché. -
Upload translations files(
Actions > Upload translation files): acción que actualiza los ficheros de traducciones de la aplicación para configuración del multi idioma. Los ficheros están ubicados en Minio o S3, con todo el contenido de la tabla de traducciones (Translations). Los usuarios no tendrán disponibles los cambios en el Portal de Datos hasta el siguiente que se limpien cachés (Actions > Clear cache) y se recargue pantalla. -
Insert default translations(
Actions > Insert default translations): acción que inserta las traducciones por defecto de Anjana Data faltantes. Acción exclusiva para los idiomas español (es-ES) e inglés (en-US). Esta acción no sobre escribe las traducciones existentes que hayan podido ser modificadas por el administrador. -
Clear Cache (
Actions > Clear cache): acción que permite limpiar cachés de la aplicación, recomendable ante cualquier cambio de configuración, autenticación, proveedores de identidades para autenticación, traducciones o iconografía y CSS. -
Load lineage (
Actions > Load lineage): acción que regenera el linaje total de entidades y relaciones para poder visualizarlo posteriormente en el Portal de Anjana. Esta acción está recomendada cuando se producen errores de acceso al linaje como consecuencia de errores o manualidades. -
Force indexing (
Actions > Force indexing): acción que fuerza una indexación completa de todas las entidades y relaciones. Esta acción está recomendada cuando se detecte una desincronización o inconsistencia entre los datos contenidos en base de datos (BD) y Solr o cuando se modifiquen las ponderaciones en las búsquedas del buscador de objetos del Portal de datos. -
Reset DB sequences (
Actions > Reset DB sequences): acción que actualiza las secuencias de base de datos ajustándose al mayor valor existente para cada tabla asociada a las secuencias. Esta acción está recomendada cuando se modifique el contenido del modelo de datos de Anjana Data. -
Clear data (
Actions > Clear caché): Acción que elimina los datos almacenados en las persistencias de Anjana Data, incluyendo objetos y sus atributos asociados.. ⚠️ Uso recomendado: limpiar los datos de prueba generados durante la configuración funcional, antes de comenzar el gobierno real de los casos de uso. -
Clear data & config(
Actions > Clear data & config):Acción que elimina toda la información y la configuración de la plataforma en las persistencias de base de datos de Anjana Data. Equivale a ejecutar Clear data, pero además borra la configuración (plantillas, unidades organizativas, dominios, etc.)⚠️ Uso recomendado: únicamente para restaurar un entorno a estado de fábrica
-
Estructura del Panel de configuración
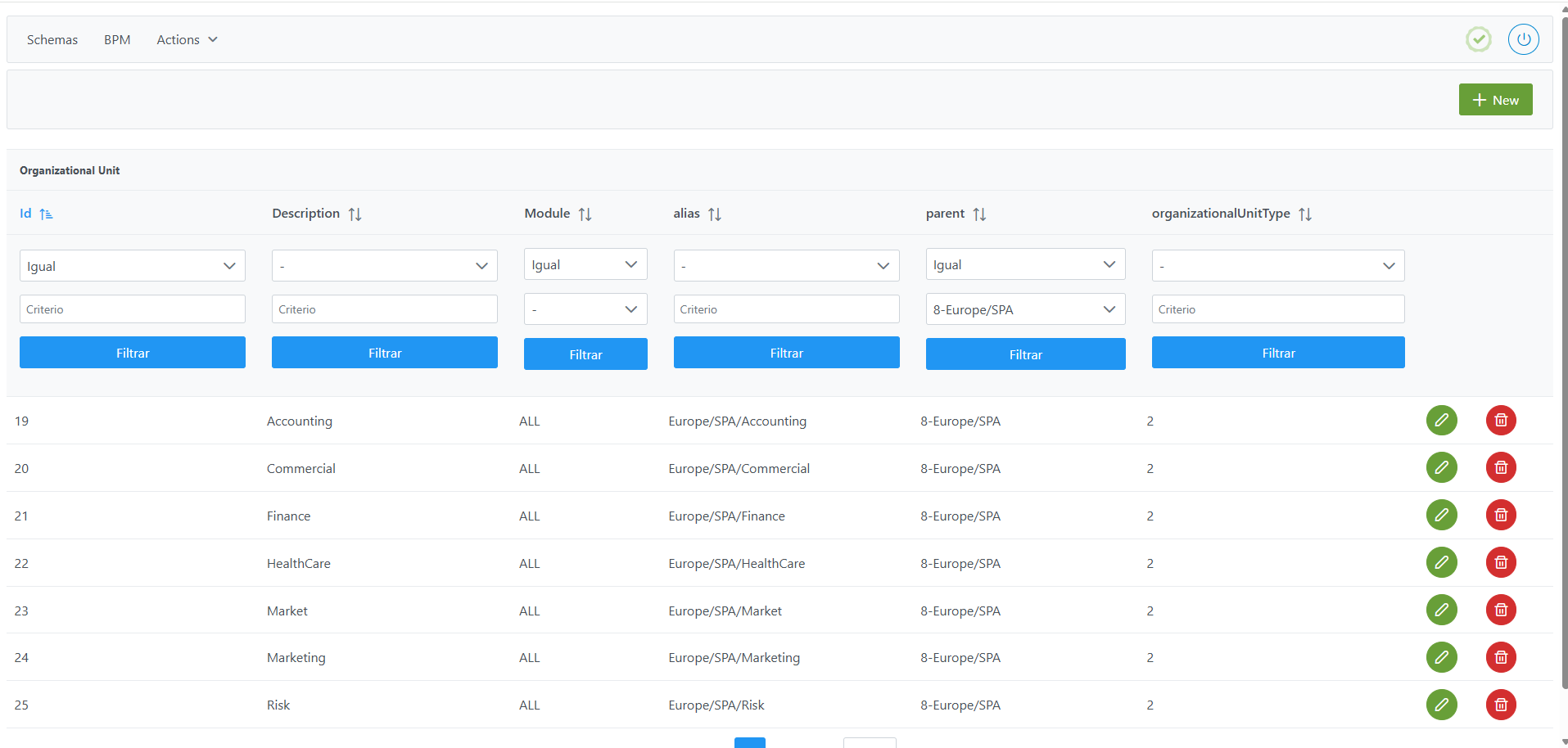
Desde la opción Schema, se accede al catálogo completo de tablas de Anjana Data, donde se almacena toda la parametría de configuración de la plataforma.
Acceso a las tablas de parametrización funcional
El usuario puede pulsar directamente sobre cada tabla para visualizar o modificar su contenido. Para cada tabla se disponen de filtros y con la posibilidad de ordenar columnas.
Aplicar filtros a las tablas de parametrización funcional
Los filtros permiten buscar registros según distintos criterios:
-
Valores iguales a, que comienzan por, que finalizan en o que contienen el texto introducido.
-
Selección de un listado de opciones posibles.
-
Filtrado por valores vacíos (nulos) o no vacíos.
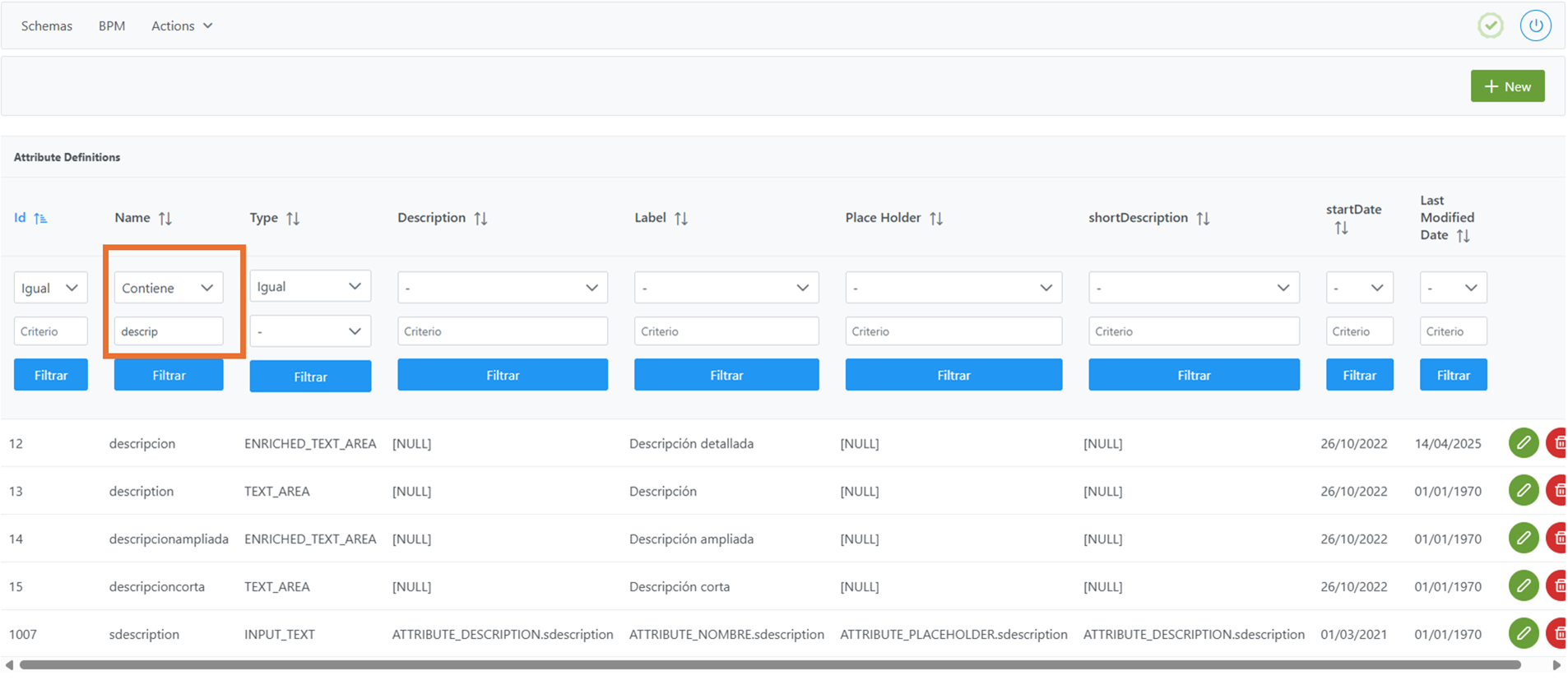
Para deshacer un filtro, basta con introducir el carácter - en uno de los campos del filtro (operador o valor) y volver a aplicarlo.
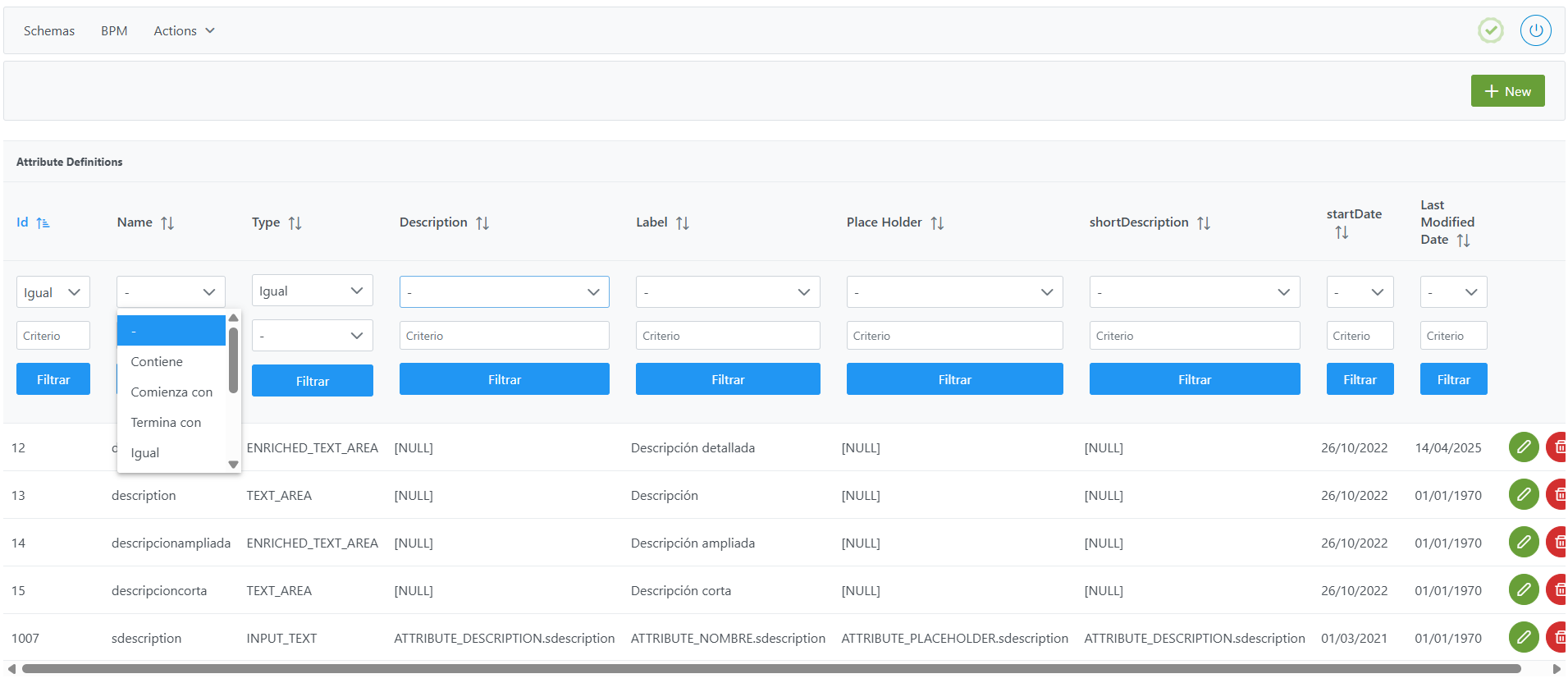
Aplicar ordenación de registros a las tablas de de parametrización funcional
Para ordenar, basta con hacer clic sobre el nombre de la columna hasta obtener la ordenación deseada (ascendente o descendente). Es posible ordenar por varias columnas a la vez pulsando la tecla Ctrl mientras se hace clic en los nombres de las columnas adicionales.