
La configuración de las tablas del esquema Anjana permite definir los distintos tipos de entidades y relaciones que se podrán declarar en Anjana Data y sus metadatos.
El modelo de base de datos se muestra en la siguiente imagen:
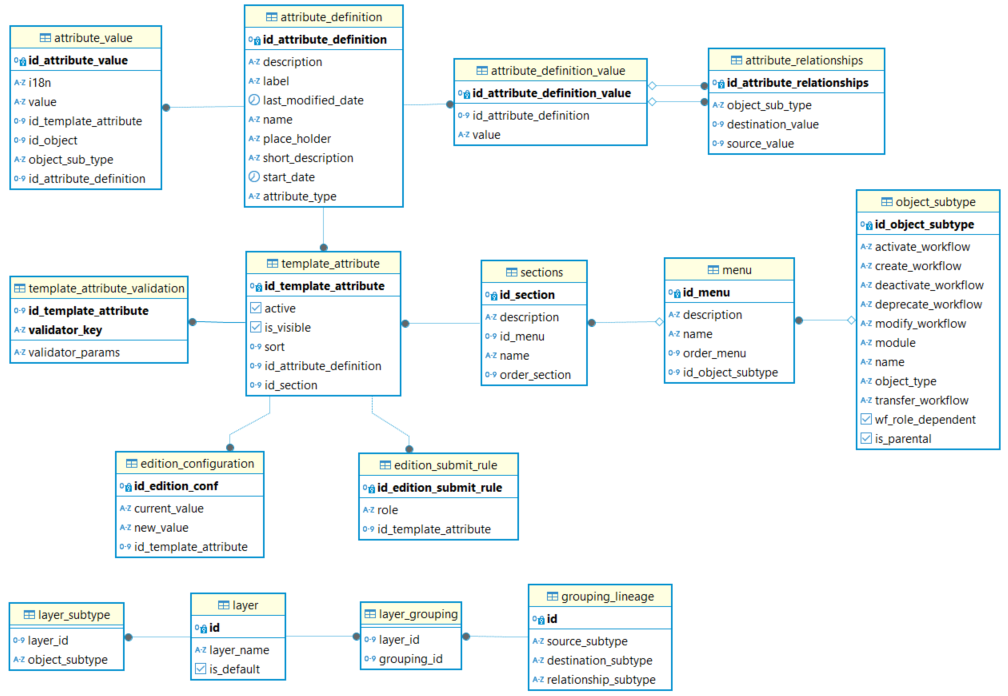
Subtipos de objetos: tipos de entidades y relaciones
Anjana Data permite gobernar diferentes tipos de entidades así como las relaciones entre ellos. Las entidades nativas del Catálogo de Datos son:
-
Dataset
-
Dataset field
-
DSA
-
Process
-
Instance
-
Solution
Y, entre estas entidades, se crean en Anjana relaciones nativas:
-
Structure: entre un dataset (origen de la relación) y sus dataset fields (destino)
-
DSA_content: entre un DSA (origen de la relación) y las entidades que contenga (destino)
-
Adherence: entre un DSA (origen de la relación) y un User (destino)
-
Instance_process: pertenencia de una instancia (destino de la relación) a su proceso (origen)
-
Instance_dataset_in: entre una instancia (destino de la relación) y los datasets que lee de los que lee (origen)
-
Instance_dataset_out: entre una instancia (origen de la relación) y los datasets en los que escribe (destino)
-
Solution_related_instance: entre solución (origen) y sus instancias relacionadas (destino)
-
Solution_owned_instance: pertenencia de una instancia (destino) a su solución propietaria (origen)
No obstante, el metamodelo de Anjana es flexible y permite añadir al catálogo citado entidades y relaciones no nativas.
De esta forma se puede definir, sin restricciones, cualquier activo funcional o técnico siempre indicando si pertenece al Glosario de Negocio o al Catálogo de Datos para garantizar el buen funcionamiento de los filtros, por ejemplo:
-
Term: Términos de negocio (Glosario de Negocio)
-
Report: Informes, reportes y Cuadros de Mandos (Glosario de Negocio o Catálogo de datos, según perspectiva de cada organización)
-
KPI: Indicadores y métricas (Glosario de Negocio)
-
Dimension: Dimensiones (Glosario de Negocio)
-
DQ Rule: Reglas de calidad de datos (Glosario de Negocio)
-
Policy: Políticas (Glosario de Negocio)
-
Data base: Bases de datos (Catálogo de datos)
-
View: Vistas (Catálogo de datos)
Las entidades se asocian entre sí mediante relaciones. Es posible dar de alta cualquier relación que resulte de utilidad, de esta forma, tendríamos relaciones tipadas como por ejemplo:
-
Término - dataset
-
Policy - DSA
-
Report - KPI
-
Report - dimension
-
Dimension - dataset
-
Report - DQ Rule
-
DQ Rule - dataset
-
…
Las entidades o relaciones se configuran en Anjana en la tabla de object_subtype y se visualizan en los wizard de creación en función de los permisos del usuario:
Estructura de la tabla
Cada subtipo de objeto registrado se caracteriza por los siguientes elementos:
-
id_object_subtype: identificador único de la tabla.
-
name: nombre del subtipo de objeto.
-
module: módulo al que pertenece, indicar “BG” para Business Glossary (Glosario de Negocio), “DC” para Data Catalog (Catálogo de Datos).
-
object_type: indica si se trata de una entidad “ENTITY” o una relación “RELATIONSHIP”.
-
activate_workflow: nombre del workflow de activación de entidades no nativas y relaciones
-
create_workflow: nombre del workflow de creación.
-
deactivate_workflow: nombre del workflow de desactivación de entidades no nativas y relaciones.
-
modify_workflow: nombre del workflow de edición.
-
transfer_workflow: nombre del workflow de transferencia (cambio de unidad organizativa) de entidades.
-
deprecate_workflow: nombre del workflow de deprecación de entidades nativas del catálogo de datos.
-
wf_role_dependent: indica si hay configurados distintos workflows en función del rol del usuario que lance el workflow.
Es decir, el flag permite indicar si existe un workflow en caso de que sea un data_owner quien envíe a validar un objeto distinto al workflow que se lanza cuando quien envía el mismo objeto es un data_steward.
is_parental: indica, en caso de ser una relación, si ésta es de parentesco y, por tanto, en el linaje se mostrará como una relación de padre-hijo (arriba y abajo). En caso contrario, la relación será de input-output (izquierda y derecha).
Visión de Administrador
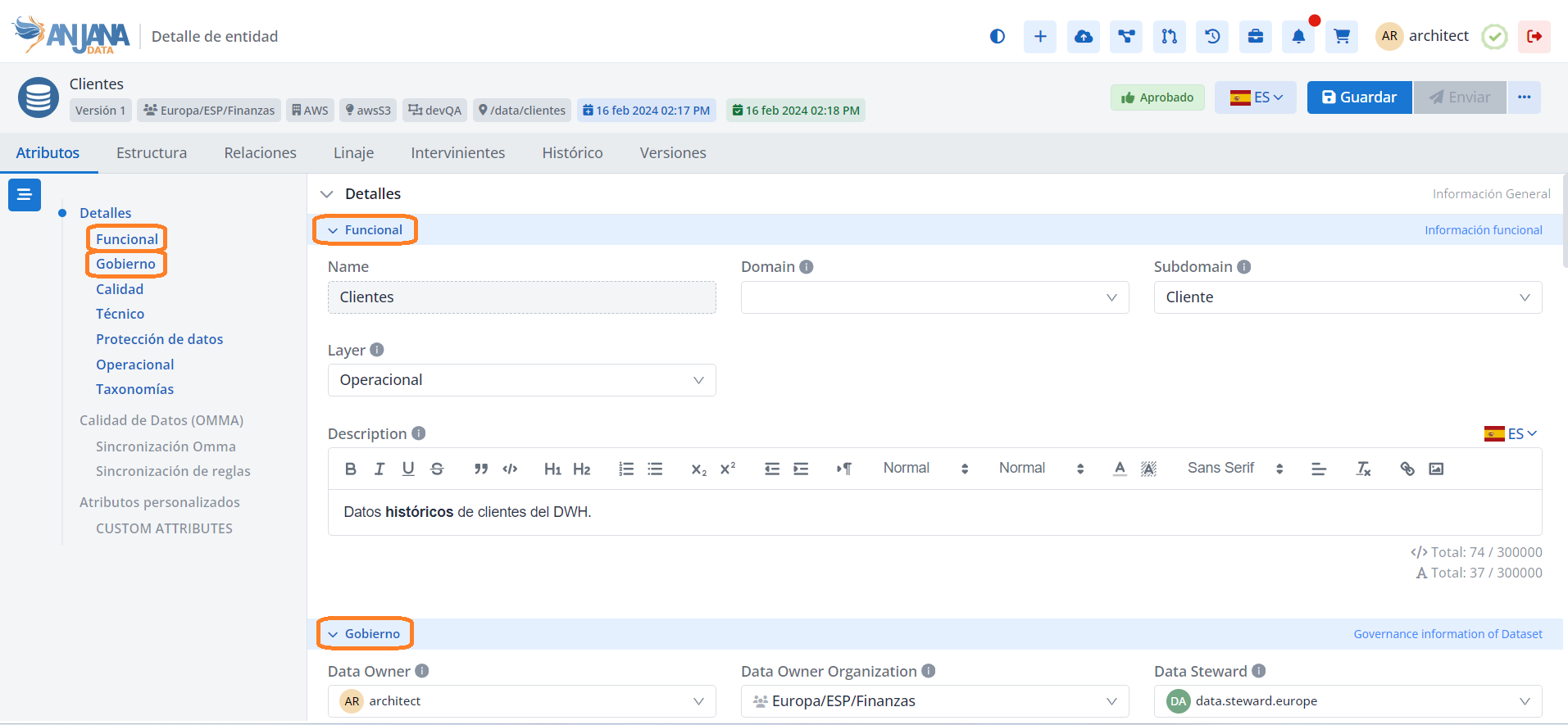
El alta de entidades o relaciones mediante el Panel de Administrador de Anjana Data se realiza en la tabla Object Sub-types:

Al acceder, se muestra una tabla que contiene todas las entidades y relaciones existentes en la configuración actual.
La creación de un nuevo tipo de entidad/relación se realiza mediante el botón New:

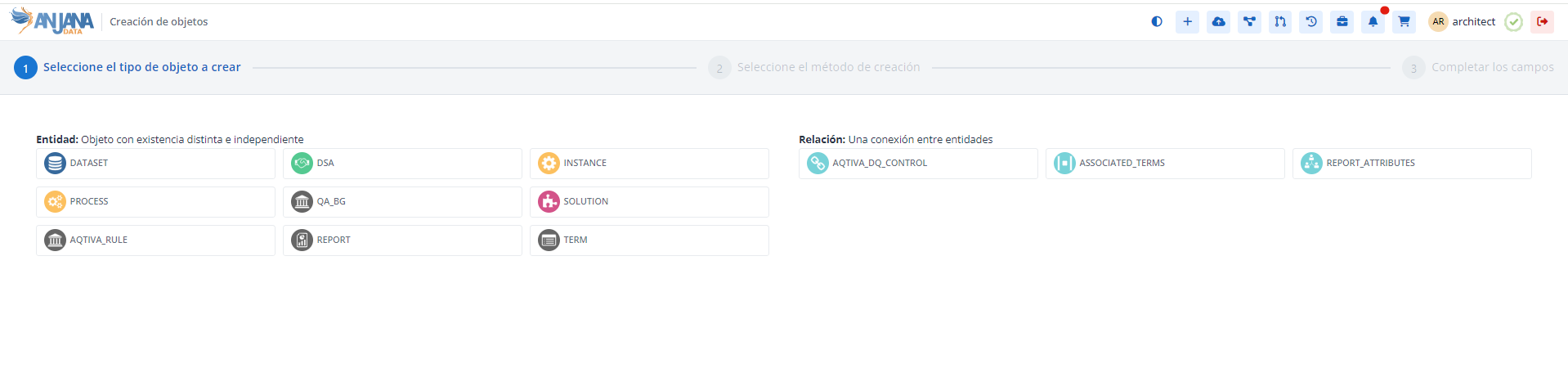
Mediante el wizard de creación se elige el módulo al que pertenece el objeto, el tipo y el nombre que se desea crear. A continuación, se muestra cómo crear una nueva entidad en el Data Catalog ('DC') de nombre DOCUMENT:
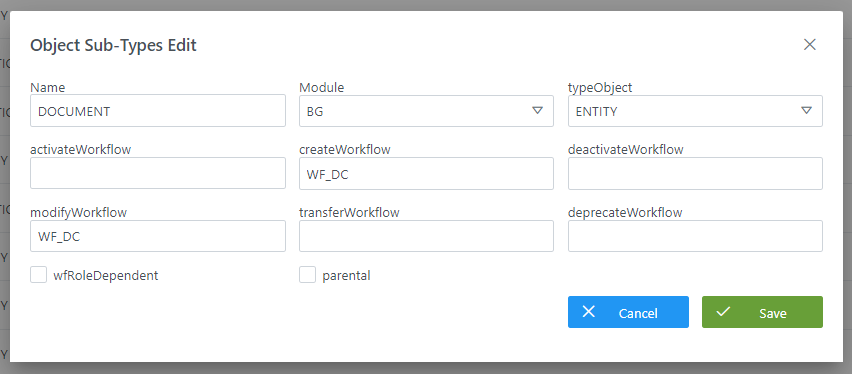
Junto con la definición de la nueva entidad o relación, se definen los nombres de los workflows que se lanzarán cuando un usuario solicite la aprobación o rechazo de algunas de las diferentes acciones que se pueden llevar a cabo dentro de Anjana Data sobre esa nueva entidad o relación.
Visión de Desarrollador
Para catalogar los distintos activos de Anjana y el nombre de sus workflows hay que configurar la tabla object_subtype del esquema Anjana. Para ello, hay que rellenar un sql como el siguiente:
INSERT INTO anjana.object_subtype
(id_object_subtype, activate_workflow, create_workflow, deactivate_workflow, deprecate_workflow, modify_workflow, "module", "name", object_type, transfer_workflow, wf_role_dependent, is_parental) VALUES
(1, 'WF_BG', 'WF_BG', 'WF_BG', NULL, 'WF_BG', 'BG', 'TERM', 'ENTITY', 'WF_BG', false, false),
(3, 'WF_BG', 'WF_DC', 'WF_BG', 'WF_DC', 'WF_DC', 'DC', 'DATASET', 'ENTITY', 'WF_BG', false, true),
(4, NULL, NULL, NULL, NULL, '', 'DC', 'DATASET_FIELD', 'ENTITY', NULL, false, false),
(5, 'WF_BG', 'WF_DC', 'WF_BG', 'WF_DC', 'WF_DC', 'DC', 'DSA', 'ENTITY', 'WF_BG', false, true),
(6, 'WF_BG', 'WF_EXAMEN_CERTI', 'WF_BG', 'WF_EXAMEN_CERTI', 'WF_EXAMEN_CERTI', 'DC', 'PROCESS', 'ENTITY', 'WF_BG', false, false),
(7, 'WF_BG', 'WF_DC', 'WF_BG', 'WF_DC', 'WF_DC', 'DC', 'INSTANCE', 'ENTITY', 'WF_BG', false, false),
(8, 'WF_BG', 'WF_DC', 'WF_BG', 'WF_DC', 'WF_DC', 'DC', 'SOLUTION', 'ENTITY', 'WF_BG', false, false),
(9, NULL, 'ADHERENCE', NULL, NULL, NULL, 'DC', 'ADHERENCE', 'RELATIONSHIP', NULL, false, false),
(13, 'WF_BG', 'WF_BG', 'WF_BG', NULL, 'WF_BG', 'BG', 'KPI', 'ENTITY', 'WF_BG', false, false),
(20, 'WF_BG', 'WF_BG', 'WF_BG', NULL, 'WF_BG', 'BG', 'RELATED_REPORTS', 'RELATIONSHIP', NULL, false, false),
(21, 'WF_BG', 'WF_BG', 'WF_BG', NULL, 'WF_BG', 'BG', 'RELATED_DATASET', 'RELATIONSHIP', NULL, false, false);
-
El nombre de los subtipos debe no contener ‘:’, ‘#’, ‘(‘, ‘)’ o espacios para no interferir con los identificadores internos de Anjana y deben estar escritos en mayúsculas.
-
No puede haber dos subtipos con el mismo nombre, ni siquiera en diferentes tipos de objetos.
-
El nombre de los subtipos no tiene traducción.
-
El nombre de los subtipos no debe cambiar si ya existen objetos para ese subtipo en Anjana.
-
No se deben incluir en la tabla los subtipos de relaciones nativas que Anjana, internamente, crea entre entidades, salvo ADHERENCE. No obstante, aunque no estén configuradas, no se debe crear ningún subtipo cuyo nombre coincida con alguna de ellas:
-
STRUCTURE
-
DSA_CONTENT
-
INSTANCE_PROCESS
-
INSTANCE_DATASET_IN
-
INSTANCE_DATASET_OUT
-
SOLUTION_RELATED_INSTANCE
-
SOLUTION_OWNED_INSTANCE
-
-
La relación ADHERENCE, nativa, debe ser configurada en object_subtype para poder informar del workflow a lanzar cuando un usuario solicite adherencia a un DSA.
En esta relación sólo es necesario configurar el workflow de creación (create_workflow) quedando los demás vacíos.
Cuando se añade un subtipo de objeto nuevo es necesario configurar las capas donde se desea visualizar en la tabla layer_subtype.
Menús de las plantillas
Los menús son los bloques de mayor nivel de los formularios dinámicos de Anjana Data. Estos se registran en la tabla menu, son totalmente configurables y es posible añadir cuantos menús se desee en cada plantilla de los diferentes tipos de objeto (entidad o relación).
Los menús son los contenedores de las distintas secciones y estas, a su vez, son las que contienen los atributos de metadatos de cada objeto.

Estructura de la tabla
Cada menú se caracteriza por los siguientes elementos:
-
id_menu: identificador único de la tabla.
-
name: nombre del menú.
En caso de querer visualizarlo en los distintos idiomas de la aplicación debe usarse el campo name como clave de traducción en la tabla de portuno de translations.
description: descripción del menú. Es una buena práctica indicar a qué objeto corresponde.
En caso de querer visualizarlo en los distintos idiomas de la aplicación debe usarse el campo description como clave de traducción en la tabla de portuno de translations.
Este campo permite definir la descripción que saldrá en el formulario.

-
order_menu: indica el orden en que se muestran los distintos menús para un mismo objeto.
-
id_object_subtype: indica el subtipo de objeto para el cual se define el menú.
Visión de Administrador
El alta de un nuevo menú en el panel de administración de Anjana Data se realiza en Menus:

Al acceder se muestra una tabla que contiene todos los menús existentes en la configuración actual.
La creación de un nuevo objeto se realiza mediante el botón New:
Mediante el wizard de creación se asignan valores a los elementos anteriormente descritos y se selecciona mediante el combo el subtipo de objeto (template) para el cual se define el menú.
A continuación, se muestra cómo crear un menú para el objeto DOCUMENT creado con anterioridad:
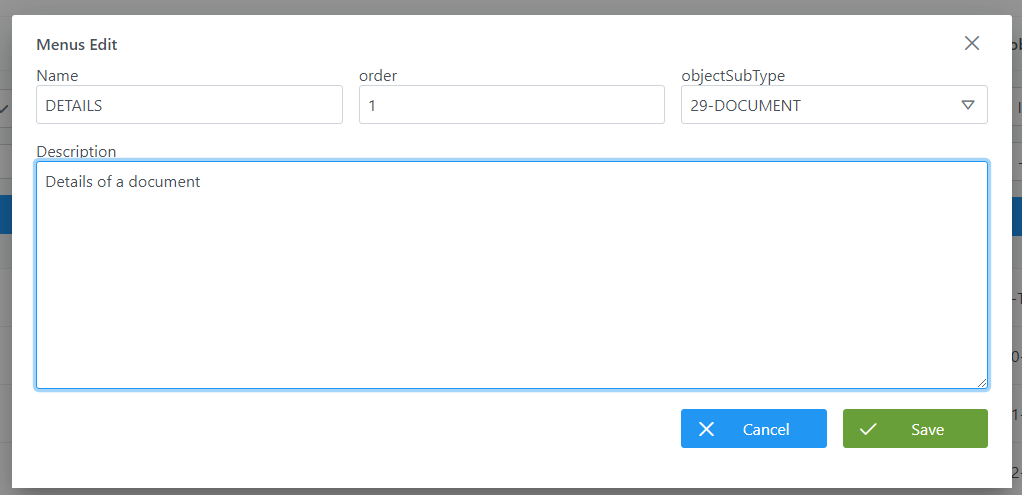
Visión de Desarrollador
Para definir los distintos menús hay que configurar la tabla menu del esquema Anjana. Para ello, hay que rellenar un sql como el siguiente:
INSERT INTO anjana.menu (id_menu, description, "name", order_menu, id_object_subtype)
VALUES
(1, 'General information of Business Term (Functional,Technical,operational)', 'DETAILS', 1, 1),
(2, 'General information of Reports (Functional,Technical,operational)', 'DETAILS', 1, 10),
(8, 'General information of Relationships (Functional,Technical,operational)', 'DETAILS', 1, 16),
(16, 'General information of DSA (Functional,Technical,operational)', 'DETAILS', 1, 5),
(27, 'Licensing Terms of DSA', 'LICENSING TERMS', 2, 5);
-
No se puede definir un menú para un subtipo de objeto que no ha sido creado aún.
-
Una plantilla de subtipo de objeto debe contener, al menos, un menú.
-
El nombre y la descripción de los menús pueden ser traducibles a los idiomas de la aplicación en caso de que se utilice el nombre y la descripción como clave en la tabla de portuno.translations.
-
A continuación de los menús configurados para los distintos subtipos de objetos siempre se añade el menú “Atributos personalizados”. Para ello, la ordenación de los menús configurados se respeta añadiendo, posteriormente, este nuevo menú a cada plantilla. En este menú se podrán dar de alta atributos específicos de cada objeto en particular.
-
Aunque ADHERENCE no tiene vista propia, es necesario definir un menú para esta relación para poder añadir los atributos necesarios que debe contener.
-
No se pueden crear dos menús iguales para el mismo subtipo.
Secciones de las plantillas
Los atributos de metadatos se agrupan bajo secciones que permiten clasificar el conjunto de metadatos que se va a visualizar. Las secciones son totalmente configurables para cada tipo de objeto y deben estar contenidas dentro de un menú. Estas se registran en la tabla sections.
Estructura de la tabla
Cada sección se caracteriza por los siguientes elementos:
-
id_section: identificador único de la tabla.
-
name: nombre de la sección en Anjana Data.
En caso de querer visualizarlo en los distintos idiomas de la aplicación debe usarse el campo name como clave de traducción en la tabla de portuno de translations.
description: descripción de la sección. Es una buena práctica indicar a qué objeto corresponde.
En caso de querer visualizarlo en los distintos idiomas de la aplicación debe usarse el campo description como clave de traducción en la tabla de portuno de translations.
Este campo permite definir la descripción que saldrá en el formulario.
-
order_section: indica el orden en que se muestran las distintas secciones dentro de un menú
-
id_menu: indica el menú para el cual se define la sección.
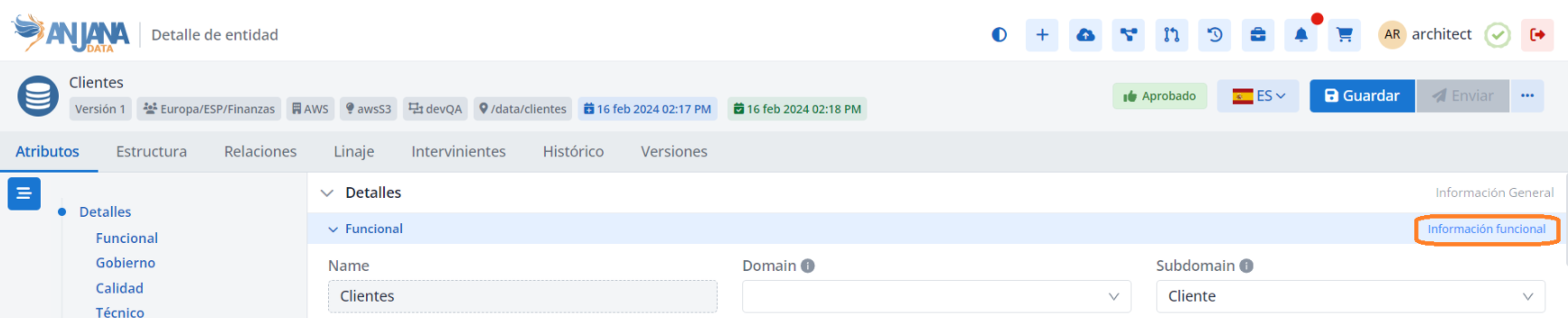
Visión de Administrador
El alta de una nueva sección en el panel de administración de Anjana Data se realiza en Sections:

Al acceder se muestra una tabla que contiene todas las secciones existentes en la configuración actual.
La creación de un nueva sección se realiza mediante el botón New:

Mediante el wizard de creación se asignan valores a los elementos name, order y description, y mediante el combo de menu se selecciona uno de los menús existentes para el cual se define la sección.
A continuación, se muestra cómo crear una sección llamada PROPERTIES para el menú de DETAILS del objeto DOCUMENT creado con anterioridad:
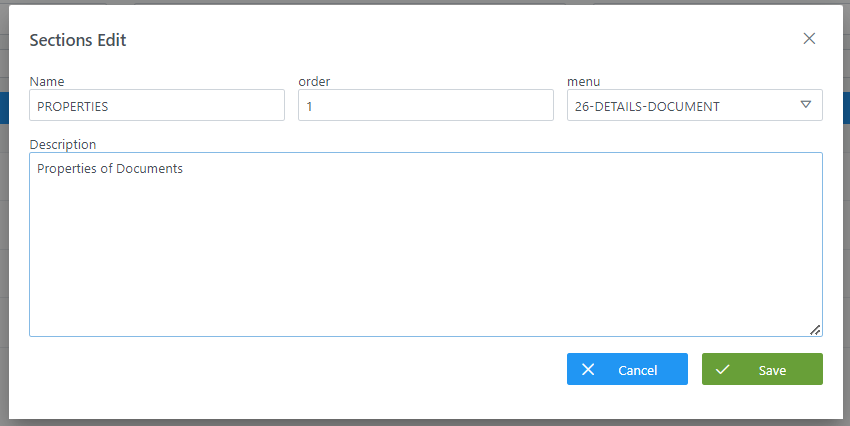
Visión de Desarrollador
Para definir las secciones hay que configurar la tabla sections del esquema Anjana. Para ello, hay que rellenar un sql como el siguiente:
INSERT INTO anjana.sections (id_section, description, id_menu, "name", order_section)
VALUES
(1, 'Properties of Business Terms', 1, 'PROPERTIES', 1),
(2, 'Operational information of Business Terms', 1, 'OPERATIONAL', 2),
(3, 'Security information of Business Terms', 1, 'SECURITY', 3),
(4, 'Quality information of Business Terms', 1, 'QUALITY', 4),
(5, 'Social information of Business Terms', 1, 'SOCIAL', 5),
(55, 'Functional information of DSA', 16, 'FUNCTIONAL', 1),
(56, 'Governance information of DSA', 16, 'GOVERNANCE', 2),
(57, 'Operational information of DSA', 16, 'OPERATIONAL', 3),
(58, 'Taxonomies information of DSA', 16, 'TAXONOMIES', 4),
(59, 'Terms of use information of DSA', 27, 'TERMS OF USE', 1);
-
No se puede definir una sección para un menú que no ha sido creado aún.
-
No se pueden crear dos secciones con el mismo nombre para el mismo menú.
-
El nombre y la descripción de las secciones pueden ser traducibles a los idiomas de la aplicación en caso de que se utilice el nombre y la descripción como clave en la tabla de portuno.translations.
-
Aunque ADHERENCE no tiene vista propia, es necesario definir una sección para esta relación para poder añadir los atributos necesarios que debe contener.
Atributos de metadatos
Los atributos de metadatos son datos que hablan de los objetos (entidades y relaciones) que representan los datos. Estos se configuran en la tabla attribute_definition:
En Anjana Data los distintos tipos de atributos de metadatos soportados son los siguientes:
-
Array de boolean: atributo para indicar uno o varios valores ‘true’ o ‘false’
-
Array de date: atributo para indicar uno o varias fechas
-
Array de decimal: atributo para indicar uno o varios números decimales
-
Array de entities: atributo para elegir una o varias entidades aprobadas en Anjana
-
Array de file: atributo para adjuntar uno o varios ficheros
-
Array de number: atributo para indicar uno o varios números enteros
-
Array de Organizational Unit: atributo para seleccionar una o varias unidades organizativas del listado de todas ellas
-
Array de text: atributo para introducir uno o varios textos cortos de hasta 255 caracteres
-
Array de URL: atributo para introducir uno o varios links a URLs navegables
-
Array de users: atributo para elegir uno o varios usuario de la lista completa de usuarios de la aplicación
-
Boolean: ‘true’ o ‘false’
-
Date: fecha (año, mes, día, hora y minutos)
-
Decimal: número con decimales
-
Enriched Text Area: atributo para introducir un texto largo de hasta 300 mil caracteres enriquecido con formato (negrita, subrayados, cursivas etc)
-
Entity Container: atributo para elegir una entidad aprobada en Anjana Data y generar relaciones nativas entre entidades. Sólo es posible utilizar este atributo en las entidades DSA, instancia y solución
-
Entity Search: atributo para elegir una entidad aprobada en Anjana Data
-
File: fichero que se almacena internamente en Anjana Data. También se permite descargar el fichero si se tiene permisos de lectura
-
International Text: cuadro de texto normal disponible para los distintos tipos de idiomas disponibles de la aplicación
-
International Text Editor: atributo para introducir un texto largo de hasta 300 mil caracteres enriquecido con formato (negrita, subrayados, cursivas etc) disponible para los distintos tipos de idiomas disponibles de la aplicación
-
International Textarea: atributo para introducir un texto largo de hasta 300 mil caracteres en los distintos idiomas disponibles para la aplicación
-
MultiSelect: atributo para seleccionar uno o varios valores de una lista preconfigurada en la pestaña Reference Metadata
-
MultiSelect con iconos: atributo para seleccionar uno o varios iconos de una lista preconfigurada en la pestaña Reference Metadata
-
MultiSelect con iconos y texto: atributo para seleccionar uno o varios valores (icono+texto) de una lista preconfigurada en la pestaña Reference Metadata
-
Number: atributo para indicar un número entero
-
Number range: selector de número entero entre un mínimo y un máximo definidos
-
Organizational Unit: atributo para seleccionar una unidad organizativa del listado de todas ellas
-
Reference Metadata: lista de valores posibles que se tiene que definir para el atributo
-
Selector con icono: lista de iconos posibles que se tiene que definir para el atributo
-
Selector con icono y texto: lista de valores (icono+texto) posibles que se tiene que definir para el atributo
-
Taxonomía única: árbol de taxonomía
-
Taxonomía de selección múltiple: árbol de taxonomías donde se pueden seleccionar uno o varios valores
-
Text: cuadro de texto normal
-
Text Area: atributo para introducir un texto largo de hasta 300 mil caracteres
-
URL: texto considerado como una URL para que el usuario pueda clicar sobre el atributo y se abra una nueva pestaña con esa URL
-
User: lista completa de usuarios de Anjana Data
Estructura de la tabla
Cada atributo registrado se caracteriza por los siguientes elementos:
-
id_attribute_definition: identificador único de la tabla.
-
name: nombre interno del atributo.
-
attribute_type: indica el tipo de atributo. A continuación se muestran las tablas de equivalencias entre los tipos de atributos soportados y el valor en el campo Type.
-
description: clave para la traducción de la descripción. Este campo permite definir la descripción que saldrá en el formulario en el icono de
-
label: clave para la traducción de la etiqueta del atributo en el idioma configurado para el usuario. Este texto debe coincidir con la clave de la traducción en portuno.translations.
-
place_holder: clave para la traducción del texto de relleno si no tiene valor. Este campo puede no completarse.
-
short_description: descripción detallada del atributo y su contenido. Este campo puede no completarse.
-
start_date: fecha de creación del atributo (sólo informativo).
-
last_modified_date: fecha de última modificación del atributo (sólo informativo).
A continuación se presenta la equivalencia entre los tipos de atributos y los valores a rellenar en el campo attribute_type de la tabla:
|
Tipo de campo |
Valor campo attribute_type |
|
Array de booleanos |
ARRAY_BOOLEAN |
|
Array de decimales |
ARRAY_DECIMAL |
|
Array de enteros |
ARRAY_NUMBER |
|
Array de entidades |
ARRAY_ENTITY |
|
Array de fechas |
ARRAY_DATE |
|
Array de ficheros |
ARRAY_UPLOAD_FILE |
|
Array de metadatos de referencia |
MULTI_SELECT |
|
Array de metadatos de referencia con iconos |
MULTI_SELECT_IMG |
|
Array de metadatos de referencia con iconos y texto |
MULTI_SELECT_IMG_TXT |
|
Array de textos |
ARRAY_ALPHANUMERICAL |
|
Array de Unidades Organizativas |
MULTI_ORGANIZATIONAL_UNIT |
|
Array de URLs |
ARRAY_UPLOAD_URL |
|
Array de usuarios |
MULTI_USERS |
|
Booleano |
INPUT_CHECKBOX |
|
Decimal |
INPUT_DECIMAL |
|
Entero |
INPUT_NUMBER |
|
Entidad |
ENTITY_SEARCH |
|
Entidades contenidas |
ENTITY_CONTAINER |
|
Fecha |
INPUT_DATE |
|
Fichero |
UPLOAD_FILE |
|
Metadato de referencia |
SELECT |
|
Metadato de referencia con icono |
SELECT_IMG |
|
Metadato de referencia con icono y texto |
SELECT_IMG_TXT |
|
Rango de enteros |
INPUT_RANGE |
|
Taxonomía de selección múltiple |
TREE_MULTISELECT |
|
Taxonomía de selección única |
TREE_SELECT |
|
Texto corto |
INPUT_TEXT |
|
Texto corto internacional |
INPUT_TEXT_INTERNATIONAL |
|
Texto enriquecido |
ENRICHED_TEXT_AREA |
|
Texto enriquecido internacional |
ENRICHED_TEXT_AREA_INTERNATIONAL |
|
Texto largo |
TEXT_AREA |
|
Texto largo internacional |
TEXT_AREA_INTERNATIONAL |
|
Unidad Organizativa |
SELECT_ORGANIZATIONAL_UNIT |
|
URL |
UPLOAD_URL |
|
Usuario |
SELECT_USERS |
Visión de Administrador
El alta de un nuevo atributo en el panel de administración de Anjana Data se realiza en la tabla Attribute Definitions.

Al acceder se muestra una tabla que contiene todos los atributos existentes en la configuración actual.
La creación de un nuevo atributo se realiza mediante el botón New:

Mediante el wizard de creación se asignan valores a los elementos anteriormente descritos.
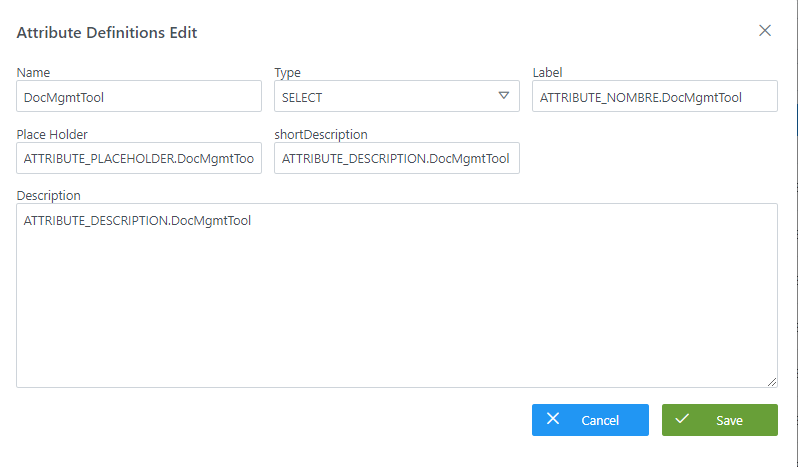
A continuación, se muestra cómo crear un atributo llamado DocMgmtTool de tipo metadatos de referencia que se utilizará en la plantilla del objeto DOCUMENT creado con anterioridad:
Visión de Desarrollador
Para definir los atributos hay que configurar la tabla attribute_definition del esquema Anjana. Para ello, hay que rellenar un sql como el siguiente:
INSERT INTO anjana.attribute_definition (id_attribute_definition,description, label,last_modified_date,name,place_holder,short_description,start_date,attribute_type) VALUES
(100,'Name of object','ATTRIBUTE_NOMBRE.name',NULL,'name','ATTRIBUTE_PLACEHOLDER.name',NULL,'2021-03-16 16:36:30.875','INPUT_TEXT'),
(102,'Term type','ATTRIBUTE_NOMBRE.termType',NULL,'termType','ATTRIBUTE_PLACEHOLDER.termType',NULL,'2021-03-16 16:36:30.875','SELECT'),
(103,'Domain','ATTRIBUTE_NOMBRE.domain',NULL,'domain','ATTRIBUTE_PLACEHOLDER.domain',NULL,'2021-03-16 16:36:30.875','SELECT'),
(104,'Subdomain','ATTRIBUTE_NOMBRE.subdomain',NULL,'subdomain','ATTRIBUTE_PLACEHOLDER.subdomain',NULL,'2021-03-16 16:36:30.875','SELECT'),
(105,'Geography','ATTRIBUTE_NOMBRE.geography',NULL,'geography','ATTRIBUTE_PLACEHOLDER.geography',NULL,'2021-03-16 16:36:30.875','SELECT');
-
El campo name de attribute_definition debe no contener espacios, '(', ')', '/', ‘:’ ni ‘#’.
-
No pueden crearse dos attribute_definition con el mismo nombre, sin importar si tienen mayúsculas o minúsculas.
-
Los label y los place_holder deben definirse en la tabla anjana.translations incluyendo un registro para cada idioma configurado en la aplicación. Es necesario que un label y sus traducciones no sean igual para dos atributos distintos, al menos si estos están en la misma plantilla.
-
Es recomendable no cambiar el tipo de ningún atributo:
-
es posible que se hayan generado validaciones para el atributo en las plantillas en las que se encuentre y que éstas no sean compatibles con el nuevo tipo (por ejemplo: que el tipo anterior fuera numérico y haya validaciones de máximo valor y ahora el tipo cambie a alfanumérico, donde la validación de máximo carece de sentido)
-
si se han creado objetos cuyo metadato contenga al atributo, cambiar el tipo puede ocasionar errores en la indexación con Solr si los tipos original y nuevo son incompatibles (por ej: si un atributo se declara numérico y, posteriormente, se cambia el atributo a alfanumérico ya que Solr tendrá indexado el atributo de tipo numérico y será imposible automatizar el cambio de campo).
-
en caso de ser necesario, leer el procedimiento a seguir en las Preguntas Frecuentes.
-
-
Para los atributos con tipo SELECT, SELECT_IMG, SELECT_IMG_TXT, TREE_SELECT, MULTI_SELECT, MULTI_SELECT_IMG, MULTI_SELECT_IMG_TXT o TREE_MULTISELECT se deben definir los posibles valores del combo de selección en la tabla attribute_definition_value (ver apartado Definir y configurar los posibles valores de los atributos).
-
Los atributos de tipo INPUT_RANGE necesitan tener validación de mínimo y máximo para poder identificar el rango de valores a elegir. En caso de no configurar estas validaciones, por defecto el valor mínimo será MIN_RANGE y el máximo MAX_RANGE, configurados en la tabla de Portuno app_configuration (ver apartado Variables del sistema de Esquema Portuno de BD)
-
Los atributos de tipo ENRICHED_TEXT_AREA o ENRICHED_TEXT_AREA_INTERNATIONAL admiten subida de ficheros con extensión gif, png o jpg.
Atributos de clave primaria
A continuación se detalla una lista de atributos que forman parte de la clave primaria (primary key) de cada uno de los objetos del Catálogo de Datos o del Glosario de Negocio. La funcionalidad y el tipado de alguno de estos datos se especificará en el siguiente punto (atributos obligatorios):
-
Para dataset: name, infrastructure, path, technology y zone.
-
Para dataset field: name, infrastructure, path, technology y zone.
-
Para DSA: name.
-
Para proceso: name, infrastructure, path, technology y zone.
-
Para instancia de proceso: name, processAri y solutionAri.
-
Para solución: name.
-
Para otras entidades no nativas predefinidas por cliente: name.
-
Para las relaciones: name, source y destination.
Atributos obligatorios
Debido a que algunos de los atributos se visualizan en el Portal de Datos o Anjana tiene cierta lógica interna sobre alguno de ellos, es obligatorio que, para esos atributos, el campo name de la tabla attribute_definition tenga un nombre particular y así como el attribute_type sea de un tipo particular. De esta forma, Anjana Data podrá identificar estos atributos y funcionar correctamente.
Además, es importante que estos atributos sean utilizados exclusivamente en los objetos que a continuación se detallan, ya que añadirlos en otros casos puede ocasionar errores de la aplicación.
Atributos para entidades
A continuación se detalla cada uno de los atributos obligatorios para las entidades, a qué subtipo de entidad aplica, el tipo que debe tener en su definición y su funcionalidad.
|
Valor en campo name |
Aplica a |
||||||
|
Entidad nativa |
Entidad no nativa |
||||||
|
DATASET |
DATASET_FIELD |
DSA |
PROCESO |
INSTANCIA |
SOLUCIÓN |
||
|
description |
X |
X |
X |
X |
X |
X |
X |
|
name |
X |
X |
X |
X |
X |
X |
X |
|
expirationDate |
X |
|
X |
X |
X |
X |
|
|
infrastructure |
X |
|
|
X |
|
|
X |
|
isGoverned |
X |
|
|
|
|
|
X |
|
path |
X |
|
|
X |
|
|
X |
|
physicalName |
X |
|
|
|
|
|
X |
|
technology |
X |
|
|
X |
|
|
X |
|
zone |
X |
|
|
X |
|
|
X |
|
data_format |
X |
|
|
|
|
|
|
|
pi |
X |
X |
X |
|
|
|
|
|
sampleData |
X |
|
|
|
|
|
|
|
datasetFields |
X |
|
|
|
|
|
|
|
fieldDataType |
|
X |
|
|
|
|
|
|
position |
|
X |
|
|
|
|
|
|
termCondFile |
|
|
X |
|
|
|
|
|
dsaContent |
|
|
X |
|
|
|
|
|
isEngine |
|
|
|
X |
|
|
|
|
instanceInDataset |
|
|
|
|
X |
|
|
|
instanceOutDataset |
|
|
|
|
X |
|
|
|
solutionRelatedInstance |
|
|
|
|
|
X |
|
Detalle de cada atributo obligatorio en las plantillas de entidades
|
Valor en campo name |
Valor en columna attribute_type |
Finalidad del atributo
|
|
description |
TEXT_AREA |
Permite introducir una descripción extensa del objeto. |
|
name |
INPUT_TEXT |
Almacena el nombre lógico de la entidad. |
|
expirationDate |
INPUT_DATE |
Almacena la fecha en la que el objeto expira. |
|
infrastructure |
SELECT |
Indica del entorno donde se encuentra localizado el objeto, usado con technology y zone para identificar un plugin en caso de gobierno activo. Sólo es necesario en caso de que la entidad vaya a tener conexión con la fuente/tecnología para extracción, sample, gob de permisos… |
|
isGoverned |
INPUT_CHECKBOX |
Indica si hay gobierno activo sobre el objeto. Sólo es necesario en caso de que la entidad vaya a tener conexión con la fuente/tecnología para extracción, sample, gob de permisos… |
|
path |
INPUT_TEXT |
Indica la localización del objeto. |
|
physicalName |
INPUT_TEXT |
Indica el nombre físico de la entidad de cara al gobierno activo de éste. Sólo es necesario en caso de que la entidad vaya a tener conexión con la fuente/tecnología para extracción, sample, gob de permisos… |
|
technology |
SELECT |
Indica la tecnología en la que está depositado el objeto, usado con infrastructure y zone para identificar un plugin en caso de gobierno activo. Sólo es necesario en caso de que la entidad vaya a tener conexión con la fuente/tecnología para extracción, sample, gob de permisos… |
|
zone |
SELECT |
Indica la zona donde se encuentra el objeto, usado con infrastructure y technology para identificar un plugin en caso de gobierno activo. Sólo es necesario en caso de que la entidad vaya a tener conexión con la fuente/tecnología para extracción, sample, gob de permisos… |
|
data_format |
INPUT_TEXT |
Indica el formato de los datos del dataset. |
|
pi |
INPUT_CHECKBOX |
Indica si el objeto contiene información personal. |
|
sampleData |
INPUT_CHECKBOX |
Indica si se puede ver una muestra de los datos del dataset en Anjana. |
|
datasetFields |
INPUT_TEXT |
Indica si los cambios en los dataset_fields afectan al propio dataset. Este atributo debe configurarse oculto en la plantilla (template_attribute) ya que sólo es necesario para poder versionar datasets o no lanzar workflows en caso de modificación de los dataset_fields de un dataset. |
|
fieldDataType |
INPUT_TEXT |
Permite seleccionar el tipo del dato que contiene el field. |
|
position |
INPUT_NUMBER |
Permite indicar el orden del field en un dataset. |
|
termCondFile |
UPLOAD_FILE o UPLOAD_URL |
Permite incluir el fichero o la ruta para acceder a los términos de licencia de un DSA. |
|
dsaContent |
ENTITY_CONTAINER |
Almacena el conjunto de entidades a las que se da acceso a los usuarios por medio del DSA. |
|
isEngine |
INPUT_CHECKBOX |
Permite indicar si el proceso es motor y por tanto puede tener múltiples instancias o si no lo es, pudiendo crear sólo una. |
|
instanceInDataset |
ENTITY_CONTAINER |
Almacena el conjunto de datasets que lee la instancia para su procesamiento. |
|
instanceOutDataset |
ENTITY_CONTAINER |
Almacena el conjunto de datasets que escribe la instancia tras su procesamiento. |
|
solutionRelatedInstance |
ENTITY_CONTAINER |
Almacena el conjunto de instancias relacionadas en la solución. |
NOTAS:
-
El atributo pi es obligatorio porque se muestra en el Portal de Anjana en caso de estar informado en los objetos. Es necesario que este atributo esté definido (attribute_definition) incluso en caso de no desear incluirlo en ninguna plantilla.
Atributos para relaciones
A continuación se detalla cada uno de los atributos obligatorios para las relaciones, a qué subtipo de relación aplica, el tipo que debe tener en su definición y su funcionalidad.
|
Valor en campo name |
Valor en columna attribute_type |
Finalidad del atributo |
Aplica a |
|
|
ADHERENCE |
Relación no nativa |
|||
|
description |
TEXT_AREA |
Permite introducir una descripción extensa del objeto. |
|
X |
|
name |
INPUT_TEXT |
Almacena el nombre lógico de la entidad. |
X |
X |
|
expirationDate |
INPUT_DATE |
Almacena la fecha en la que el objeto expira. |
X |
|
|
source |
ENTITY_SEARCH |
Permite indicar el origen de una relación o uno de sus extremos. |
|
X |
|
destination |
ENTITY_SEARCH |
Permite indicar el destino de una relación o uno de sus extremos. |
|
X |
|
pae |
INPUT_TEXT |
Permite asociar internamente la adherencia con la solicitud enviada por el usuario. |
X |
|
|
requestReason |
INPUT_TEXT |
Permite almacenar el motivo de la solicitud de adherencia. |
X |
|
NOTAS:
-
Para poder completar la información de las adherencias, es necesario definir plantilla, menú, sección y atributos para ella, aunque no sea accesible esta información por medio de un formulario como ocurre con cualquier otra entidad en Anjana.
Atributos obligatorios no incluidos en plantillas
Anjana necesita que estos atributos estén definidos (attribute_definition) para su correcto funcionamiento a pesar de no estar incluidos en ninguna plantilla de objeto (template_attribute).
|
Valor en campo name |
Valor en columna attribute_type |
Finalidad del atributo
|
|
organizationalUnit |
SELECT_ORGANIZATIONAL_UNIT |
Permite indicar la OU de la entidad. Este atributo no debe añadirse a ninguna plantilla ya que sólo es necesario para poder importar entidades por medio de fichero excel. |
|
processAri |
INPUT_TEXT |
Permite indicar el proceso de la instancia. Este atributo no debe añadirse a ninguna plantilla ya que sólo es necesario para poder importar instancias por medio de fichero excel. |
|
solutionAri |
INPUT_TEXT |
Permite indicar la solución propietaria de la instancia. Este atributo no debe añadirse a ninguna plantilla ya que sólo es necesario para poder importar instancias por medio de fichero excel. |
|
source |
ENTITY_SEARCH |
Permite indicar el origen de una relación o uno de sus extremos. En caso de existir alguna plantilla de relación no nativa, se debe incluir en la plantilla. Si no existe, tan solo es necesario definir el atributo. |
|
destination |
ENTITY_SEARCH |
Permite indicar el destino de una relación o uno de sus extremos. En caso de existir alguna plantilla de relación no nativa, se debe incluir en la plantilla. Si no existe, tan solo es necesario definir el atributo. |
Valores de los atributos
Para aquellos atributos de tipo selección de valores (atributos con attribute_type SELECT, SELECT_IMG, SELECT_IMG_TXT, TREE_SELECT, MULTI_SELECT, MULTI_SELECT_IMG, MULTI_SELECT_IMG_TXT o TREE_MULTISELECT) hay que definir los metadatos de referencia de entre los cuales el usuario puede seleccionar el o los que convengan.
Esta configuración se lleva a cabo en la tabla attribute_definition_value.
Estructura de la tabla
Cada valor registrado se caracteriza por los siguientes elementos:
-
id_attribute_definition_value: identificador único de la tabla.
-
value: valor del atributo.
En caso de querer visualizarlo en los distintos idiomas de la aplicación debe usarse el value como clave de traducción en la tabla de portuno de translations.
Si el atributo es de imagen o de imagen y texto (SELECT_IMG, SELECT_IMG_TXT, MULTI_SELECT_IMG o MULTI_SELECT_IMG_TXT) el icono a utilizar debe estar localizado en Minio o S3 y se llamará <nombreAtributo><valor>.svg (siendo nombreAtributo el name de attribute_definition y valor el value de attribute_definition_value). Más detalle en el documento ‘Anjana Data - CONF - Iconografía y CSS’.
id_attribute_definition: Atributo de metadatos para el cual se despliega el combo de selección.
Visión de Administrador
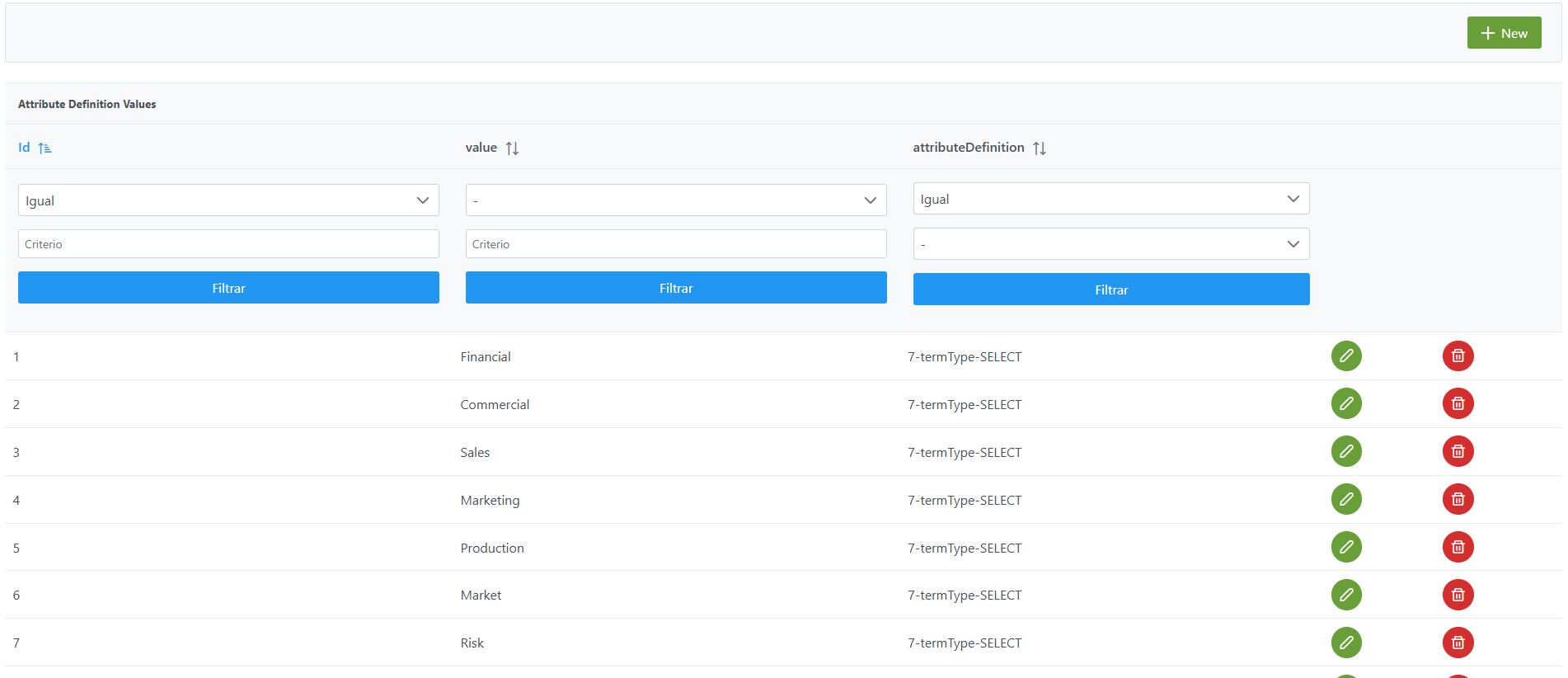
El alta de un nuevo atributo en el panel de administración de Anjana Data se realiza en Attribute Definition Values:
Al acceder se muestra una tabla que contiene todos los atributos existentes en la configuración actual.
La creación de un nuevo metadato de referencia se realiza mediante el botón New:
Mediante el wizard de creación se asignan valores a los elementos anteriormente descritos.
A continuación, se muestra cómo crear atributos de referencia para un atributo:
Visión de Desarrollador
Para definir los metadatos de referencia hay que configurar la tabla attribute_definition_value del esquema Anjana. Para ello, hay que rellenar un sql como el siguiente:
INSERT INTO anjana.attribute_definition_value
(id_attribute_definition_value, id_attribute_definition, value) VALUES
(1,2,'Financial')
,(2,2,'Commercial')
,(3,2,'Sales')
,(4,2,'Marketing')
,(5,2,'Production')
,(6,2,'Marketing')
,(7,2,'Risk')
,(8,3,'Finances')
,(9,3,'Marketing')
,(10,3,'Operations')
,(11,3,'Human Resources')
,(12,3,'Legal');
-
En el caso de los atributos infraestructure, technology y zone se debe usar como value (y, por tanto, como clave en portuno.translations) exactamente el mismo nombre que se usa para esos campos en las tripletas para los plugins de Tot.
-
No deben existir dos valores iguales con las mismas traducciones para el mismo atributo en la tabla attribute_definition_value.
Atributos de plantilla
Configurar las plantillas de metadatos supone definir en qué menú y sección aparecerán los metadatos de entre los definidos en la tabla attribute_definition. Esta asociación de atributos a plantillas se configura en la tabla template_attribute.
Estructura de la tabla
Cada atributo de plantilla registrado se caracteriza por los siguientes elementos:
-
id_template_attribute: identificador único de la tabla.
-
active: flag que indica si el atributo está activo o no en el formulario.
En caso de querer eliminar un atributo de una plantilla, éste debe tener active=false para no estar disponible en edición o visualización. Los objetos que tuvieran anteriormente este atributo informado siguen manteniéndolo pero no es visible en el formulario así que no puede modificarse. Si más adelante se desea volver a incluir el atributo en la plantilla, active=’true’ permitirá que vuelva a estar disponible y se podrá ver y editar el valor del atributo en todos los objetos.
Si el atributo pertenece a la plantilla de ADHERENCE, se debe rellenar con 'false' debido a que no existe una pantalla específica del objeto adherencia.
is_visible: flag que indica si un atributo de los dataset_fields es visible en la tabla Structure de la pantalla de su dataset.
En caso de tratarse de un atributo perteneciente a la plantilla de ADHERENCE, se debe rellenar con 'false' puesto que no existe una pantalla específica del objeto adherencia.
Si el atributo pertenece a una plantilla distinta de la de dataset_field y adherencia se debe rellenar con 'true'.
-
sort: orden en el que aparece en el atributo en la sección donde queda asignado.
-
id_attibute_definition: atributo que se desea introducir en la plantilla.
-
id_section: sección en la que se desea introducir el atributo.
Visión de Administrador
El alta de los atributos dentro de una plantilla se realiza en el panel de administración de Anjana Data en Template Attributes:

Al acceder se muestra una tabla que contiene todos los atributos de plantilla existentes en la configuración actual.
La creación de un nuevo registro en esta tabla se realiza mediante el botón New:
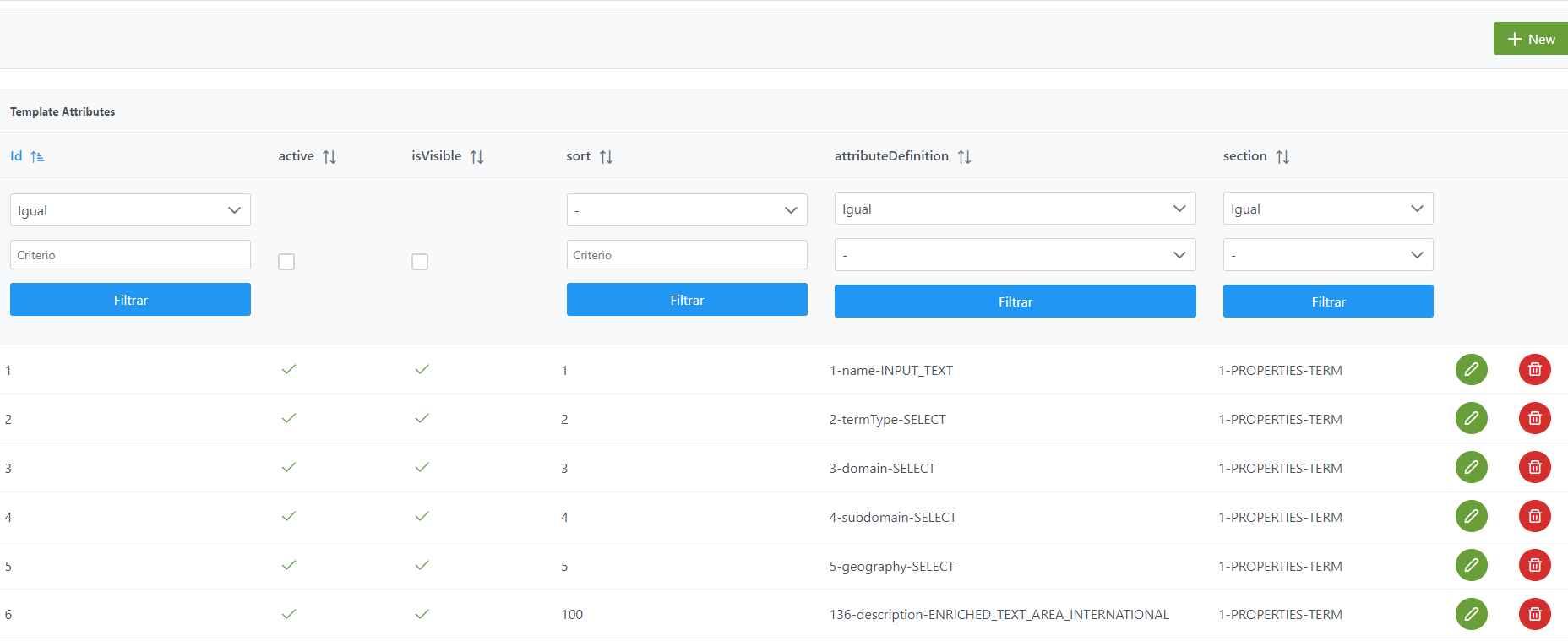
Mediante el wizard de creación se asignan valores a los elementos anteriormente descritos:
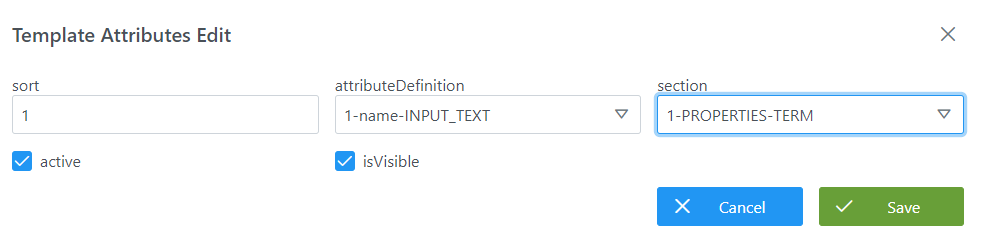
Visión de Desarrollador
Para definir los atributos dentro de un template hay que configurar la tabla template_attribute del esquema Anjana. Para ello, hay que rellenar un sql como el siguiente:
INSERT INTO anjana.template_attribute
(id_template_attribute, active, is_visible, sort, id_attribute_definition, id_section)
VALUES
(1, true, true, 1, 1, 1),
(2, true, true, 2, 2, 1),
(3, true, true, 3, 3, 1),
(4, true, true, 4, 4, 1),
(5, true, true, 5, 5, 1),
(6, true, true, 6, 136, 1),
(7, true, true, 7, 7, 1);
-
Es obligatorio que los atributos marcados como obligatorios se incluyan en las plantillas de los subtipos de objetos a los que aplican.
-
Aunque ADHERENCE no tiene vista propia, es necesario añadir registros en template_attribute para esta relación para poder añadir los atributos necesarios que debe contener. Como se especifica anteriormente, los campos active e is_visible de estos atributos deben marcarse a 'false'.
-
No puede incluirse dos veces un mismo atributo en la misma sección.
Validaciones de los atributos
Existe la posibilidad de definir un conjunto de validaciones para asegurar la correcta entrada de los atributos de metadatos. Estas validaciones se configuran en la tabla template_attribute_validation.

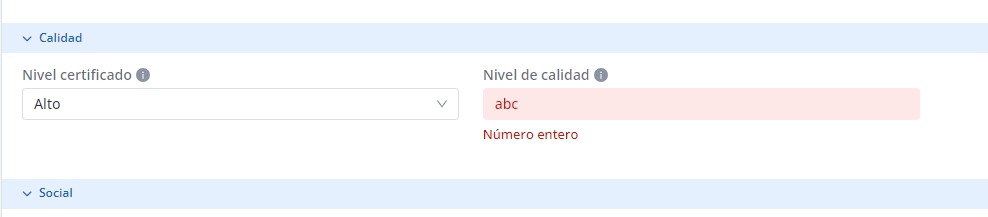
Estas validaciones pueden ser:
Atributos obligatorios (REQUIRED)
Esta regla permite identificar los atributos que obligatoriamente deben ser informados en una plantilla.
Atributos no modificables (NOT EDITABLE)
Esta regla permite identificar los atributos que no pueden ser editados.
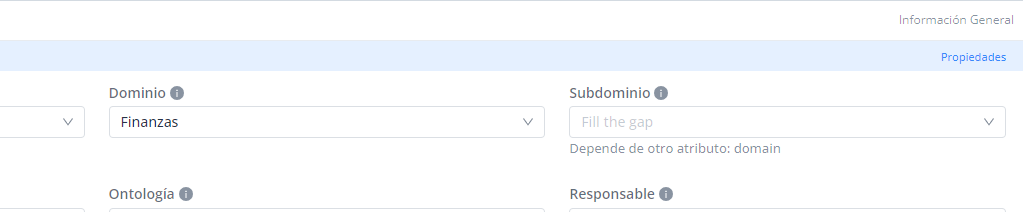
Dependencia entre valores de referencia (DEPENDS ON)
Esta regla permite hacer que el conjunto de valores válido para un atributo de tipo selector de valores (select, select con imágenes, select con imágenes y texto o los array de estos tipos) dependa del valor escogido en otro atributo de este mismo tipo
Heredable (HERITABLE)
Esta regla permite identificar un atributo booleano no editable y cuyo valor se calcula en función de los valores que adquiera ese mismo atributo en la plantilla de otros objetos.
La herencia sólo puede darse entre entidades que tengan un parentesco según el metamodelo nativo de Anjana, es decir, los siguientes casos:
-
El dataset hereda de sus dataset_fields
-
El DSA hereda de las entidades incluidas en el atributo dsaContent
-
La instancia hereda de sus datasets input o output
Longitud máxima y mínima para valores alfanuméricos (MIN/MAX LENGTH)
Esta regla permite establecer unas dimensiones mínimas y máximas de contenido en los campos de texto.
En el caso de los atributos de texto enriquecido las etiquetas html generadas computan para esta validación.
Mínimo y Máximo para los valores en los campos enteros, decimales, arrays de los mismos y rangos de valores (MIN/MAX)
Esta regla permite definir un rango de valores, con mínimo y máximo respectivamente, para atributos numéricos.
Longitud máxima y mínima de la parte decimal de campos y arrays de decimales (MAX/MIN DECIMAL PRECISION)
Esta regla permite establecer un mínimo y máximo de dígitos para la parte decimal.
Longitud máxima y mínima de valores en el conjunto (MAX/MIN LENGTH ARRAY)
Esta regla permite establecer el número mínimo y máximo de valores seleccionados en un conjunto.
Restricción de subtipos en atributos de tipo entidad o array de entidades (SUBTYPE_FILTER)
Esta regla permite limitar el subtipo de las entidades en los atributos de tipo ENTITY_CONTAINER, ENTITY_SEARCH y ARRAY_ENTITY, como los atributos source y destination de una relación. Puede pasarse una lista separada por ‘_-’ (y sin espacios) para permitir varios subtipos. Si no se configura ninguna lista, los extremos podrán contener cualquier subtipo de Entidad.
Tipo de relación creada (RELATIONSHIP_TYPE)
Esta regla identifica la relación que se creará con los atributos de tipo ENTITY_CONTAINER entre la entidad que tiene en su plantilla el atributo y aquellas entidades con las que se completa. Solo se debe aplicar en los siguientes atributos:
-
Para el atributo dsaContent la relación debe ser DSA_CONTENT.
-
Para el atributo instanceInDataset la relación debe ser INSTANCE_DATASET_IN.
-
Para el atributo instanceOutDataset la relación debe ser INSTANCE_DATASET_OUT.
-
Para el atributo solutionRelatedInstance la relación debe ser SOLUTION_RELATED_INSTANCE.
Validaciones para cada tipo de atributo:
|
Tipo de atributo numérico |
Validaciones |
|||||||
|
MIN |
MAX |
MAX DECIMAL PRECISION |
MIN DECIMAL PRECISION |
MAX LENGTH ARRAY |
MIN LENGTH ARRAY |
REQUIRED |
NOT EDITABLE |
|
|
ARRAY DECIMAL |
x |
x |
x |
x |
x |
x |
x |
x |
|
ARRAY NUMBER |
x |
x |
|
|
x |
x |
x |
x |
|
INPUT DECIMAL |
x |
x |
x |
x |
|
|
x |
x |
|
INPUT NUMBER |
x |
x |
|
|
|
|
x |
x |
|
INPUT RANGE |
x |
x |
|
|
|
|
x |
x |
|
Tipo de atributo alfanumérico |
Validaciones |
|||||
|
MAX LENGTH |
MIN LENGTH |
MAX LENGTH ARRAY |
MIN LENGTH ARRAY |
REQUIRED |
NOT EDITABLE |
|
|
ARRAY ALPHANUMERICAL |
x |
x |
x |
x |
x |
x |
|
ARRAY UPLOAD URL |
|
|
x |
x |
x |
x |
|
ENRICHED TEXT AREA |
x |
x |
|
|
x |
x |
|
INPUT TEXT INTERNATIONAL |
x |
x |
|
|
x |
x |
|
ENRICHED TEXT AREA INTERNATIONAL |
x |
x |
|
|
x |
x |
|
TEXT AREA INTERNATIONAL |
x |
x |
|
|
x |
x |
|
INPUT TEXT |
x |
x |
|
|
x |
x |
|
TEXT AREA |
x |
x |
|
|
x |
x |
|
UPLOAD URL |
|
|
|
|
x |
x |
|
Tipo de atributo de selección de valores |
Validaciones |
||||||
|
DEPENDS ON |
MAX LENGTH ARRAY |
MIN LENGTH ARRAY |
REQUIRED |
NOT EDITABLE |
SUBTYPE FILTER |
RELATIONSHIP TYPE |
|
|
ARRAY ENTITY |
|
x |
x |
x |
x |
x |
|
|
MULTI ORGANIZATIONAL UNIT |
|
x |
x |
x |
x |
|
|
|
MULTI USERS |
|
x |
x |
x |
x |
|
|
|
ENTITY CONTAINER |
|
x |
x |
x |
x |
x |
x |
|
ENTITY SEARCH |
|
|
|
x |
x |
x |
|
|
MULTI SELECT |
x |
x |
x |
x |
x |
|
|
|
MULTI SELECT IMG |
x |
x |
x |
x |
x |
|
|
|
MULTI SELECT IMG TXT |
x |
x |
x |
x |
x |
|
|
|
SELECT ORGANIZATIONAL UNIT |
|
|
|
x |
x |
|
|
|
SELECT |
x |
|
|
x |
x |
|
|
|
SELECT IMG |
x |
|
|
x |
x |
|
|
|
SELECT IMG TXT |
x |
|
|
x |
x |
|
|
|
TREE SELECT |
|
|
|
x |
x |
|
|
|
TREE MULTISELECT |
|
x |
x |
x |
x |
|
|
|
SELECT USERS |
|
|
|
x |
x |
|
|
|
Otros tipos de atributos |
Validaciones |
||||
|
HERITABLE |
MAX LENGTH ARRAY |
MIN LENGTH ARRAY |
REQUIRED |
NOT EDITABLE |
|
|
ARRAY BOOLEAN |
|
x |
x |
x |
x |
|
ARRAY DATE |
|
x |
x |
x |
x |
|
ARRAY UPLOAD FILE |
|
x |
x |
x |
x |
|
INPUT CHECKBOX |
x |
|
|
|
x |
|
INPUT DATE |
|
|
|
x |
x |
|
UPLOAD FILE |
|
|
|
x |
x |
Estructura de la tabla
Cada validación registrada se caracteriza por los siguientes elementos:
-
id_template_attribute: atributo de plantilla para el que se define la validación.
-
validator_key: clave de la validación:
-
DEPENDS_ON: dependencia con otro atributo del template
-
HERITABLE: en el caso de que su valor se herede de otro metadato
-
MAX: número máximo
-
MAX_DECIMAL_PRECISION: número máximo de precisión para valores decimales.
-
MAX_LENGTH: longitud máxima
-
MAX_LENGTH_ARRAY: cantidad máxima de elementos de array
-
MIN: número mínimo
-
MIN_DECIMAL_PRECISION: número mínimo de precisión para valores decimales.
-
MIN_LENGTH: longitud mínima
-
MIN_LENGTH_ARRAY: cantidad mínima de elementos de array
-
NOT_EDITABLE: no modificable
-
RELATIONSHIP_TYPE: subtipo de relación que se crea
-
REQUIRED: atributo obligatorio
-
SUBTYPE_FILTER: subtipo de entidad permitida
-
-
validator_params: parámetros a completar en función del validator_key:
|
validator_key |
validator_params |
|
DEPENDS_ON |
nombre del atributo del que depende (name de la tabla attribute_definition) |
|
MAX MAX_DECIMAL_PRECISION MAX_LENGHT MAX_LENGHT_ARRAY MIN MIN_DECIMAL_PRECISION MIN_LENGHT MIN_LENGHT_ARRAY |
valor numérico |
|
REQUIRED NOT_EDITABLE |
true |
|
HERITABLE |
‘HIGH’ en caso de que el valor heredado tenga que ser 'true' si al menos uno de los elementos de los que se hereda tiene 'true' ‘LOW’ en caso de que el valor heredado tenga que ser 'false' si al menos uno de los elementos de los que se hereda tiene 'false' |
|
RELATIONSHIP_TYPE |
nombre del subtipo de relación (name de la tabla object_subtype) |
|
SUBTYPE_FILTER |
nombres de los subtipos de entidad (name de la tabla object_subtype) separados por ‘_-’ (y sin espacios) |
Visión de Administrador
El alta de validaciones de este tipo dentro de un template se realiza en el panel de administración de Anjana Data en Template Attribute Validations:
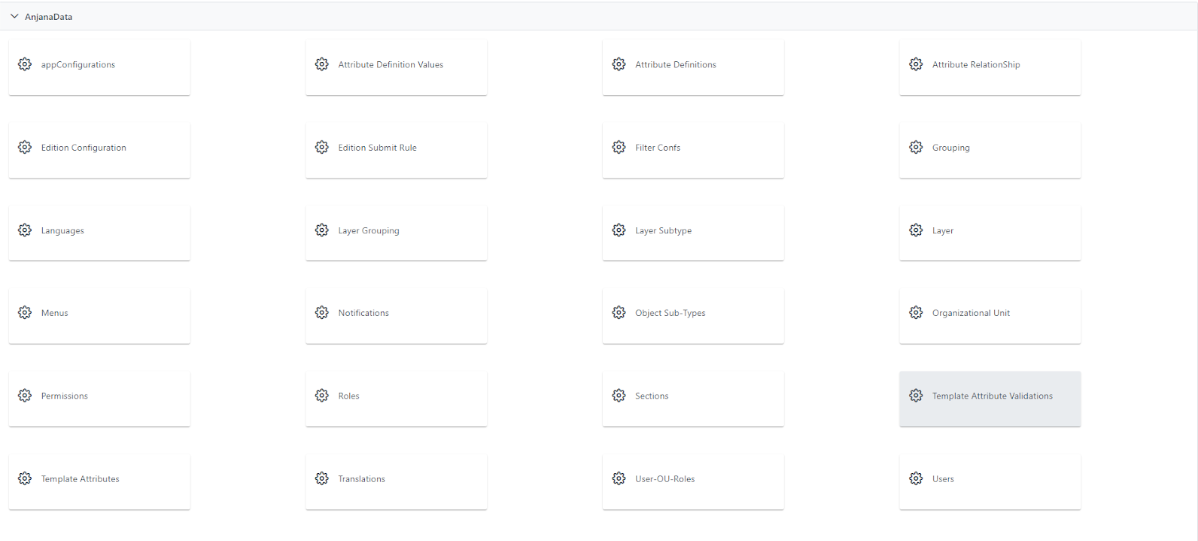
Al acceder se muestra una tabla que contiene todas las validaciones existentes en la configuración actual.
La creación de una nueva validación se realiza mediante el botón New:
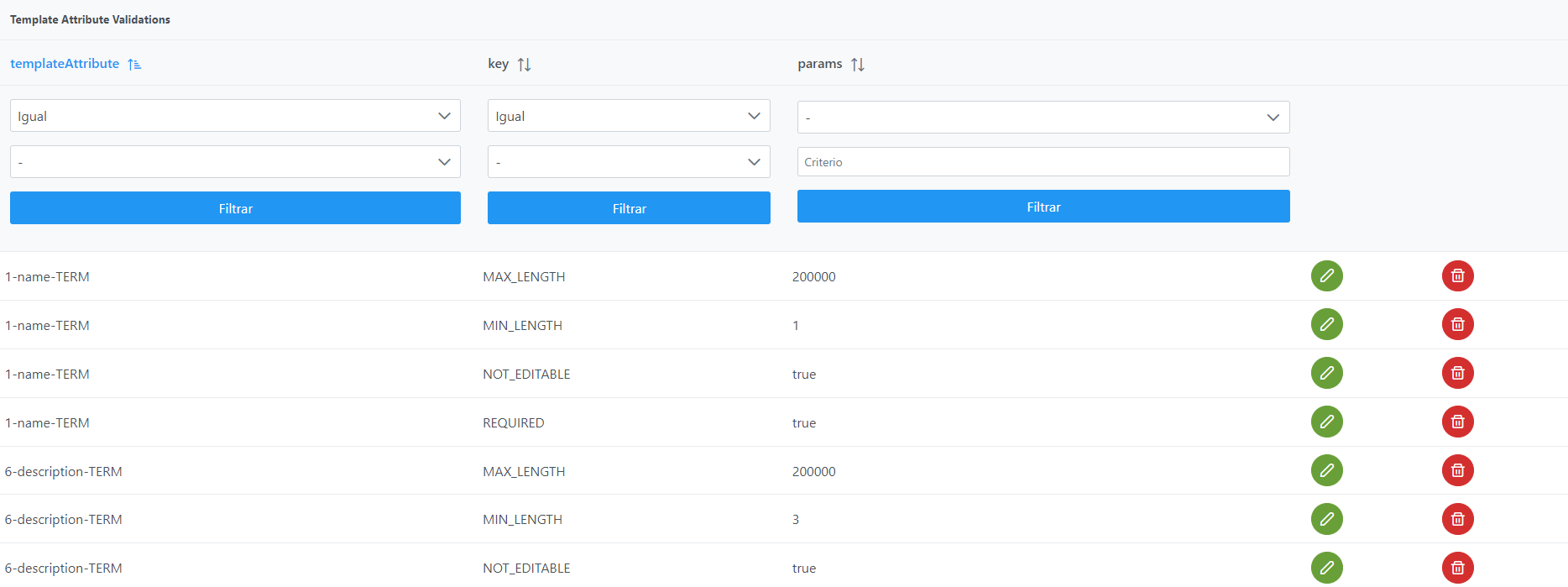
Mediante el wizard de creación se asignan valores a los elementos anteriormente descritos:
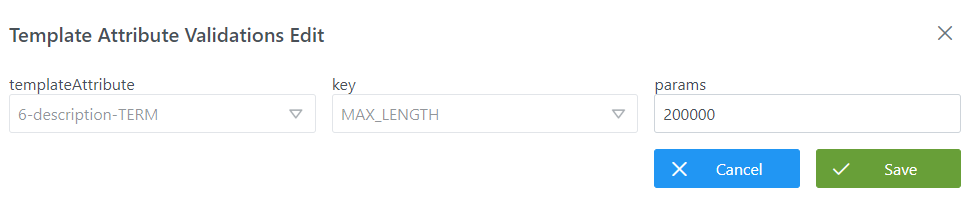
Visión de Desarrollador
Para definir validaciones rápidas de atributos dentro de un template hay que configurar la tabla template_attibute_validation del esquema Anjana. Para ello, hay que rellenar un sql como el siguiente:
INSERT INTO anjana.template_attribute_validation
(id_template_attribute, validator_key, validator_params) VALUES
(1, 'REQUIRED', 'true'),
(1, 'MAX_LENGTH', '300000'),
(1, 'MIN_LENGTH', '1'),
(1, 'NOT_EDITABLE', 'true'),
(4, 'DEPENDS_ON', 'domain'),
(375, 'SUBTYPE_FILTER', 'TERM'),
(470, 'HERITABLE', 'HIGH');
NOTAS:
Los atributos que componen la PK de los objetos (name, source, destination, infrastructure, technology, zone, path, processAri y solutionAri) deben tener la validación de obligatoriedad y no ser editables (REQUIRED y NOT_EDITABLE) para que siempre estén completos.
En caso contrario, la validación de la configuración efectuada desde la acción específica de Portuno saldrá errónea o la descarga del excel con la plantilla del objeto fallará.
-
Adicionalmente, el atributo physicalName contenido en las plantillas de aquellos subtipos de entidad que puedan ser extraídos por medio de descubrimiento automático debe tener también la validación de no editable para que siempre mantenga el valor original de la fuente. No es necesario que tenga la validación de requerido.
-
Los atributos de tipo INPUT_RANGE necesitan tener validación de mínimo y máximo para poder identificar el rango de valores a elegir.
En caso de no configurarla, por defecto los valores mínimo y máximo vendrán determinados por MIN_INTEGER y MAX_INTEGER de la tabla de app_configurations.
-
En caso de no configurar validaciones de MIN y MAX en los atributos de tipo numérico (INPUT_NUMBER, ARRAY_NUMBER, INPUT_DECIMAL, ARRAY_DECIMAL), se aplican los valores MIN_INTEGER y MAX_INTEGER de la tabla de app_configurations.
-
En caso de no configurar validaciones de MIN_DECIMAL_PRECISION y MAX_DECIMAL_PRECISION en los atributos de tipo decimal (INPUT_DECIMAL, ARRAY_DECIMAL), se aplican los valores MIN_INTEGER, MAX_INTEGER, de la tabla de app_configurations.
-
En caso de no configurar validaciones de MIN_LENGTH y MAX_LENGTH en los atributos de tipo texto largo (ENRICHED_TEXT_AREA, INPUT_TEXT_INTERNATIONAL, ENRICHED_TEXT_AREA_INTERNATIONAL, TEXT_AREA_INTERNATIONAL y TEXT_AREA ) se aplican los valores MAX_LENGTH_TEXT_EDITOR y MIN_LENGTH_TEXT_EDITOR de la tabla de app_configurations.
-
En caso de no configurar validaciones de MIN_LENGTH y MAX_LENGTH en los atributos de tipo texto corto (INPUT_TEXT y ARRAY_ALPHANUMERICAL ) se aplican los valores MAX_LENGTH_TEXT_BD y MIN_LENGTH_TEXT_EDITOR de la tabla de app_configurations.
-
La validación para indicar el tipo de relación (RELATIONSHIP_TYPE) que se crea con cada atributo ENTITY_CONTAINER de la aplicación es obligatoria y no debe ser modificada.
En caso de una instalación en vacío (sin configuración previa), tras la configuración de las plantillas de los objetos, se deben dar de alta las validaciones especificadas al inicio del apartado.
-
Los atributos de tipo booleano no pueden representar un estado “no definido” o “vacío” puesto que no hay forma de distinguir entre “no seleccionado” y “seleccionado como false". Es por ello por lo que la validación de REQUIRED en estos atributos carece de sentido.
-
Para poder completar la dependencia entre los valores de los atributos de tipo SELECT es necesario que se configuren las relaciones entre ellos (ver en apartado attribute_relationships).
-
No es posible configurar la misma validación dos veces para el mismo atributo de plantilla.
Relaciones entre valores de reference metadata o taxonomías
Es posible relacionar entre sí metadatos de referencia de forma que el valor que se seleccione en un combo filtre los resultados que se muestran en el siguiente combo como resultado de una lógica existente en el ecosistema de datos de su organización.
Esta configuración está disponible tanto para los atributos infraestructura, tecnología y zona elegidos en el wizard de creación de objetos como para el resto de atributos de las plantillas de tipo Metadatos de Referencia (o listados de valores predeterminados).
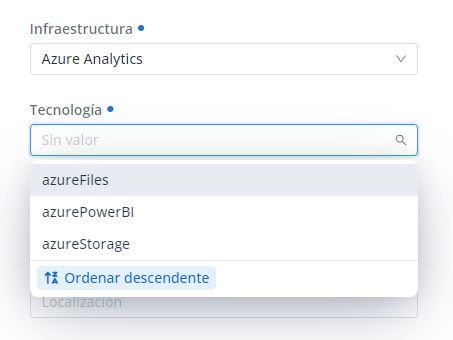
Por ejemplo, si se hablara de comunidades autónomas y ciudades, si se eligiera la CA de Madrid, en el combo de ciudades sólo se visualizarán aquellas ciudades propias de dicha comunidad y no las de toda España.
Para todos estos casos en los que los valores de un atributo dependen de la selección hecha en otro atributo, es necesario que se configure la validación de dependencia (“depends_on” en template_attribute_validation) entre estos atributos identificando cuál de los dos depende del otro, siendo ambos de la misma plantilla.
Otra configuración con la que se relacionan valores de atributos es la que se establece para la taxonomía de selección única o múltiple. En estos casos, los valores forman un árbol de dependencias en el que debe detallarse qué nodo del árbol es padre de qué otro nodo.
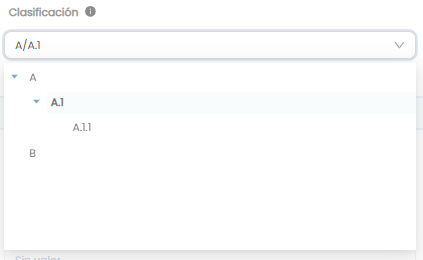
Para este ejemplo, cada uno de los nodos raíz (A y B) deben tener configurada una relación cuyo padre es <null> para que Anjana interprete ese nodo como inicio de una rama. En cualquiera de los atributos de tipo taxonomía de selección única o múltiple es necesario tener, al menos, un nodo raíz.
Estas relaciones entre valores de atributos se definen en la tabla attribute_relationships.
Estructura de la tabla
Cada relación registrada se caracteriza por los siguientes elementos:
-
id_attribute_relationships: identificador único de la tabla.
-
destination_value: valor del atributo que depende del otro.
-
source_value: valor del atributo original del que depende el destinationValue.
-
object_sub_type: plantilla a la que se asocia el atributo (null si es a cualquier plantilla donde esté el atributo)
Visión de Administrador
El alta de dependencias de este tipo se realiza en el panel de administración de Anjana Data en Attribute Relationship:
Al acceder se muestra una tabla que contiene todas las relaciones entre atributos y plantillas existentes en la configuración actual.
La creación de una nueva relación se realiza mediante el botón New:
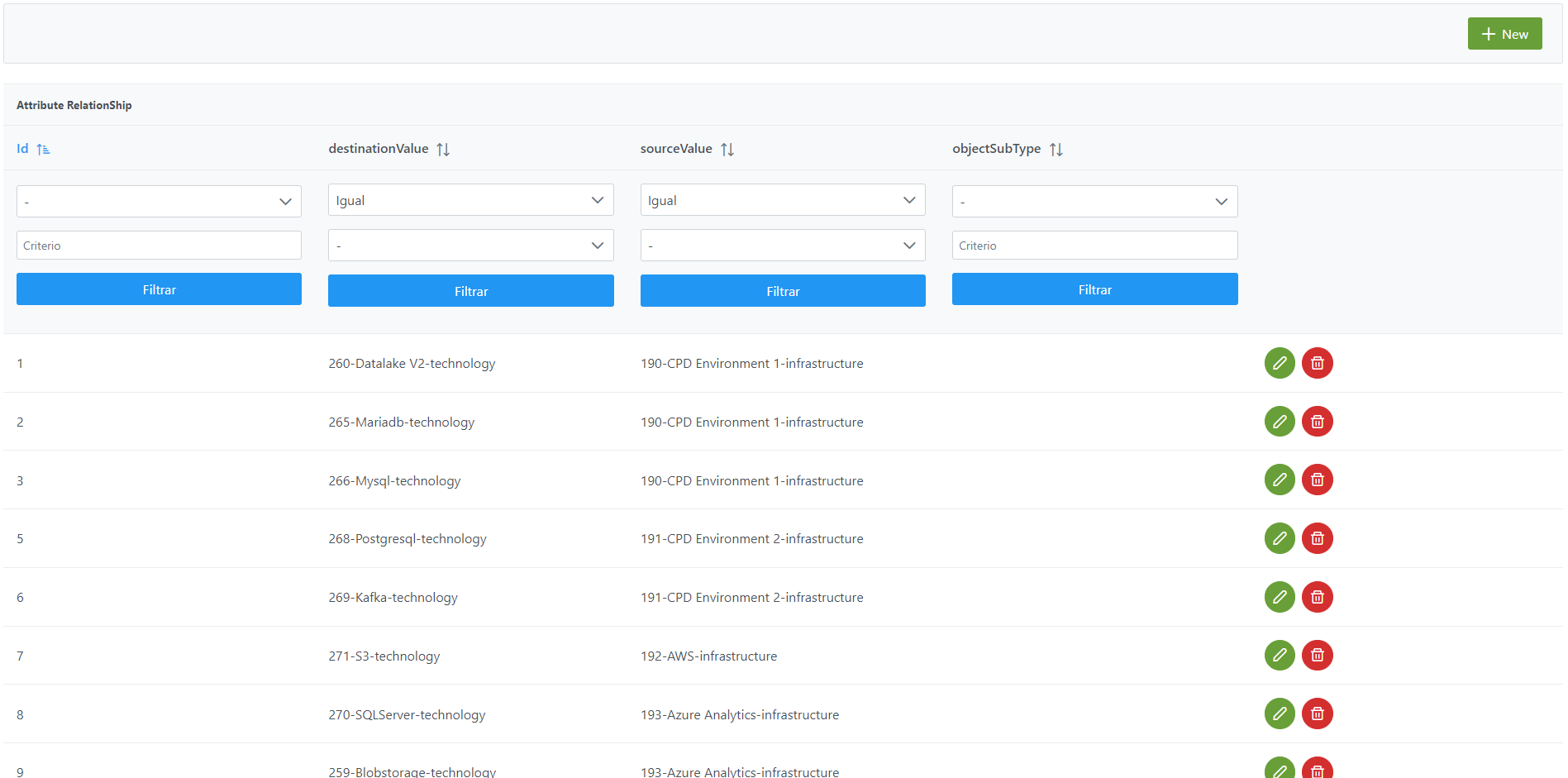
Mediante el wizard de creación se asignan valores a los elementos anteriormente descritos:
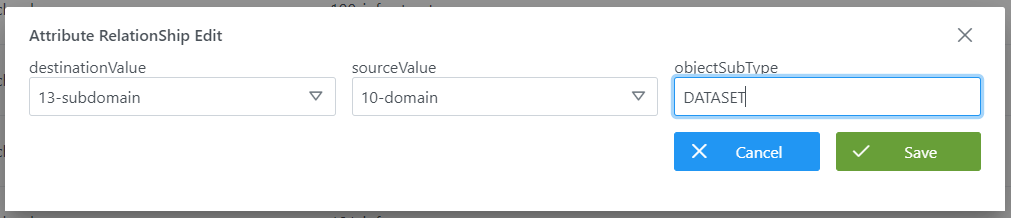
Visión de Desarrollador
Para definir las relaciones entre atributos hay que configurar la tabla attribute_relationships del esquema Anjana. Para ello, hay que rellenar un sql como el siguiente:
insert into anjana.attribute_relationships
(id_attribute_relationships, source_value, destination_value, object_sub_type) values
(1,190,260, null)
,(2,190, 265, null)
,(3,190, 266, null)
,(4,191, 267, null)
,(5,191,268, null)
,(6,191,269, null);
NOTA:
Puesto que los valores de las taxonomías pueden ser distintos en función del subtipo de objeto, siempre es necesario que exista un nodo raíz en el árbol de valores.
Reglas de versionado
En Anjana es posible configurar qué cambios generan un versionado en los objetos mediante las reglas de versionado. Estas reglas permiten identificar los atributos de los objetos que, al ser editados, son suficientemente relevantes como para versionar el objeto y deprecar la versión original.
Las reglas se definen en la tabla edition_configuration y sólo pueden ser configuradas para las entidades nativas del Catálogo de Datos: dataset, dataset_field, DSA, proceso, instancia de proceso y solución.
Estructura de la tabla
Cada regla de versionado registrada se caracteriza por los siguientes elementos:
-
id_edition_configuration: identificador único de la tabla.
-
current_value: valor original del atributo en caso de que sea booleano. Si se desea que haya versionado independientemente del valor inicial, introducir null.
Este valor (excepto null) debe ser el configurado en value de la tabla attribute_definition_value.
new_value: valor nuevo del atributo. Si se desea que haya versionado independientemente del valor nuevo, introducir null.
Este valor (excepto null) debe ser el configurado en value de la tabla attribute_definition_value.
id_template_attribute: atributo de una plantilla concreta al que aplica la regla.
Visión de Administrador
El alta de las reglas de versionado se realiza en el panel de administración de Anjana Data en Edition Configuration:
Al acceder se muestra una tabla que contiene todas las reglas de versionado existentes en la configuración actual.
La creación de una nueva regla se realiza mediante el botón New:

Mediante el wizard de creación se asignan valores a los elementos anteriormente descritos:
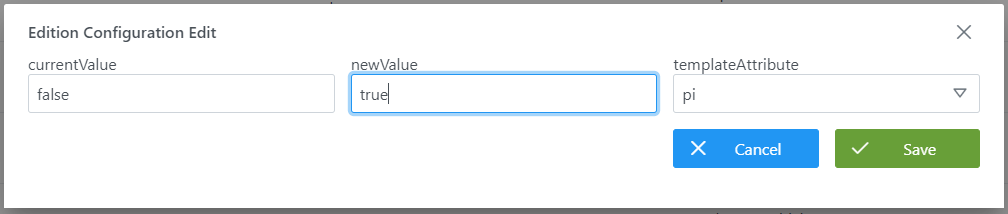
Visión de Desarrollador
Las reglas de versionado se configuran en la tabla edition_configuration del esquema Anjana. Para ello, hay que rellenar un sql como el siguiente:
INSERT INTO anjana.edition_configuration
(id_edition_conf, current_value, new_value, id_template_attribute) VALUES
(1, false, true, 258)
,(2, false, true, 455)
,(5, null, null, 21)
,(6, null, null, 46)
,(30, null, null, 472)
,(31, null, null, 328);
NOTAS:
Si se desea versionar un dataset en caso de que se modifiquen sus dataset_fields, es necesario añadir una regla de versionado para el atributo datasetFields del dataset. De esta forma, se comprobarán los cambios ocurridos en los dataset_fields y se versionará el dataset si alguno de esos cambios coincide con alguna regla de versionado para los atributos de dataset_fields.
Reglas de lanzamiento de workflow en modificación y versionado
Es posible configurar qué cambios no provocan el lanzamiento de workflows de modificación y/o versionado en los objetos de Anjana Data mediante las reglas de edición. Estas reglas permiten identificar los atributos de los objetos que, al ser editados y enviados a validar por determinados roles, no generan workflow de aprobación quedando el objeto validado automáticamente.
Esta configuración se lleva a cabo en la tabla edition_submit_rule.
Estructura de la tabla
Cada regla de lanzamiento de workflow registrada se caracteriza por los siguientes elementos:
-
id_edition_submit_rule: identificador único de la tabla.
-
id_template_attribute: atributo de plantilla al que aplica la regla.
-
role: nombre del rol que no lanza un workflow si se edita el atributo definido en templateAttribute (debe coincidir con el campo name de la tabla role).
Visión de Administrador
El alta de las reglas de lanzamiento de workflow en ediciones y versionado se realiza en el panel de administración de Anjana Data en Edition Submit Rule:
Al acceder se muestra una tabla que contiene todas las reglas que se usan para decidir si se lanza un workflow o no cuando se edita o versiona un objeto.
La creación de una nueva regla se realiza mediante el botón New:
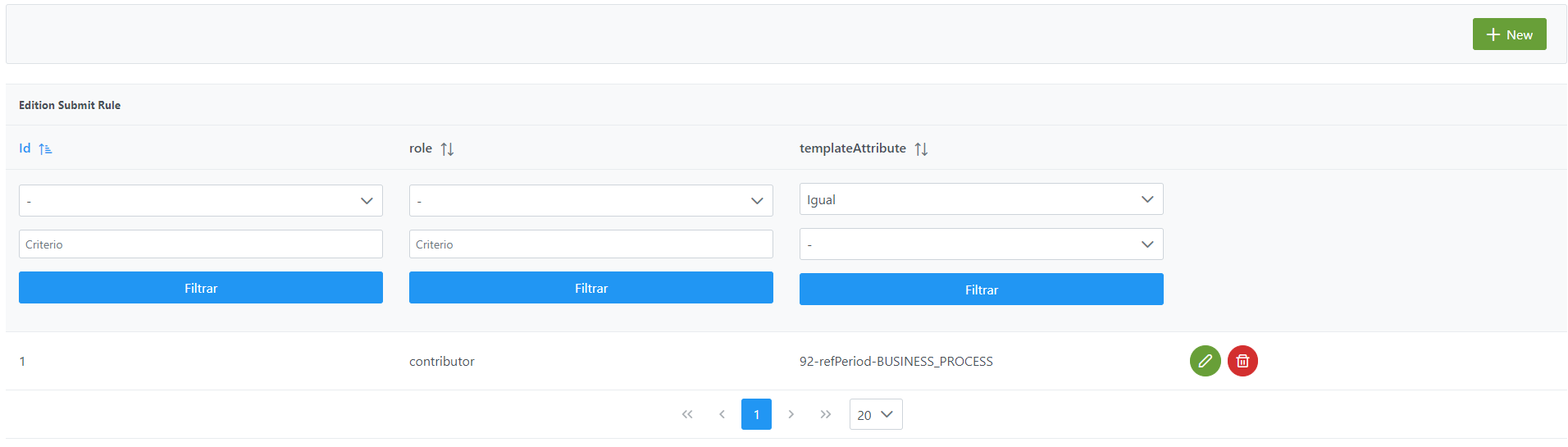
Mediante el wizard de creación se asignan valores a los elementos anteriormente descritos:
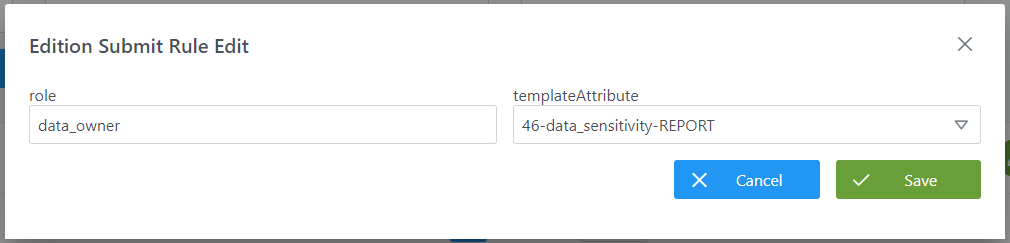
Visión de Desarrollador
Las reglas de lanzamiento de workflow en ediciones y versionado se configuran en la tabla edition_submit_rule del esquema Anjana. Para ello, hay que rellenar un sql como el siguiente:
INSERT INTO anjana.edition_submit_rule
(id_edition_submit_rule, "role", id_template_attribute) VALUES
(1,'contributor',92),
(3,'data_owner',46);
NOTAS:
Si se desea no lanzar workflow de validación en caso de que se modifiquen los dataset_fields de un dataset, es necesario añadir una regla para el atributo datasetFields del dataset.
Con esta regla, se comprobarán los cambios ocurridos en los dataset_fields y, si los cambios coinciden con las reglas configuradas, no se lanzará workflow de validación del dataset.
Esta regla, además, permite no lanzar workflow de validación en caso de que se haya añadido o eliminado algún dataset_field del dataset.
Capas del linaje
Es posible visualizar el linaje de Anjana desde distintas perspectivas. Estas perspectivas se configuran como capas de visualización que facilitan al usuario la navegación filtrando en función de la configuración entidades o relaciones por capas.
Estas capas se definen en la tabla layer.
Estructura de la tabla
Cada capa registrada se caracteriza por los siguientes elementos:
-
id: identificador único de la tabla.
-
layer_name: nombre de la capa.
En caso de querer visualizarlo en los distintos idiomas de la aplicación debe usarse el campo layer_name como clave de traducción en la tabla de portuno de translations.
is_default: flag que determina si la capa se muestra por defecto cuando los usuarios acceden al linaje. Se debe marcar sólo una capa con is_default = 'true'.
Visión de Administrador
El alta de las capas del linaje se realiza en el panel de administración de Anjana Data en Layer:
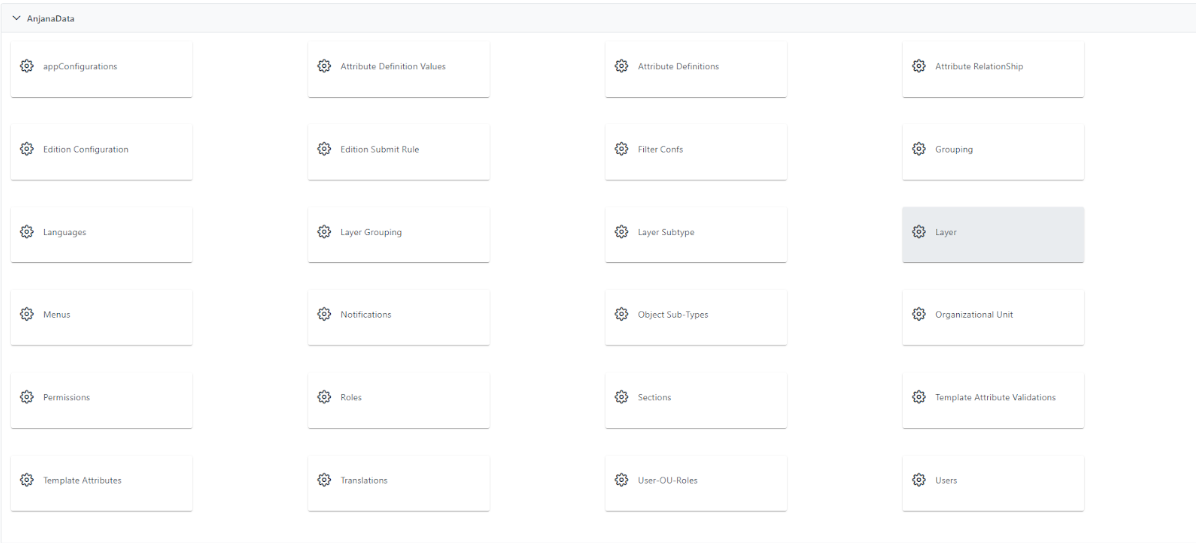
Al acceder se muestra una tabla que contiene todas las capas definidas para las pantallas de linaje.
La creación de una nueva capa se realiza mediante el botón New:
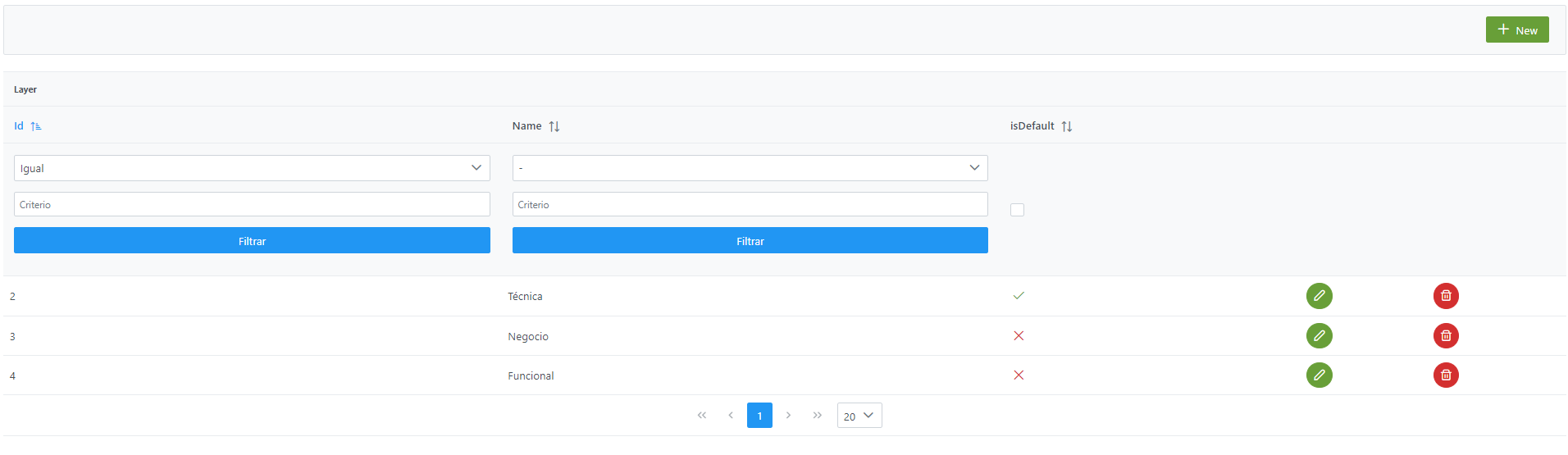
Mediante el wizard de creación se asignan valores a los elementos anteriormente descritos:
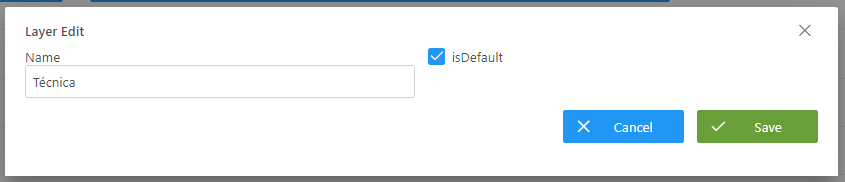
Visión de Desarrollador
Las capas del linaje se configuran en la tabla layer del esquema Anjana. Para ello, hay que rellenar un sql como el siguiente:
INSERT INTO anjana.layer (id, layer_name, is_default) VALUES
(2, 'Técnica', true),
(3, 'Negocio', false),
(4, 'Funcional', false);
NOTAS:
No puede haber dos capas con el mismo nombre.
Subtipos de las capas del linaje
Es posible, en las capas del linaje, determinar qué entidades o relaciones pueden ser mostradas configurando los subtipos de cada una de ellas.
De esta forma, se configuran capas específicas para usuarios técnicos evitando entidades del Glosario de Negocio distintas de las capas necesarias para usuarios de negocio en las que se pueden obviar entidades del Catálogo de Datos.
En este caso, en la capa Tratamiento de datos se visualizan unos nodos que no se ven en la Capa de consumo:
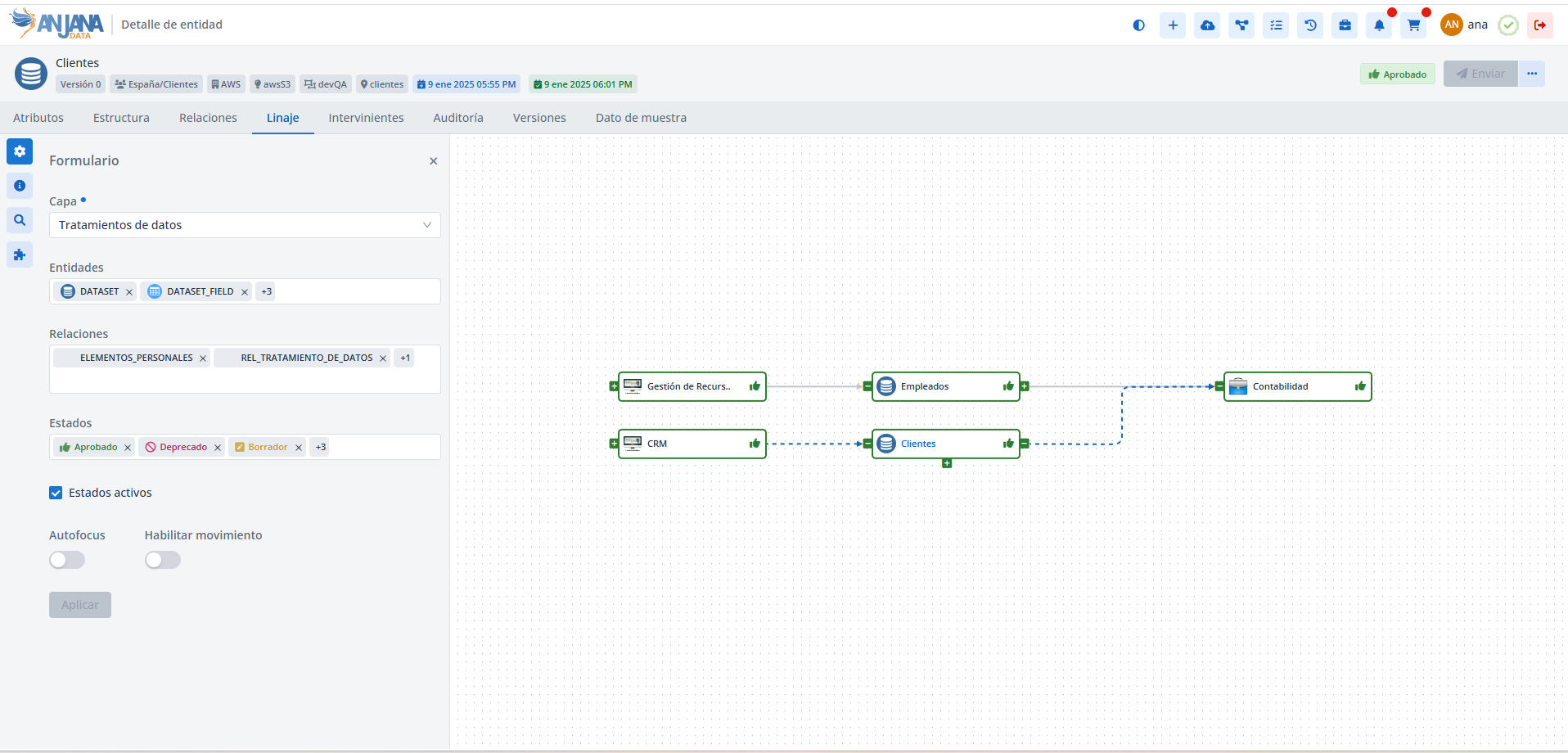
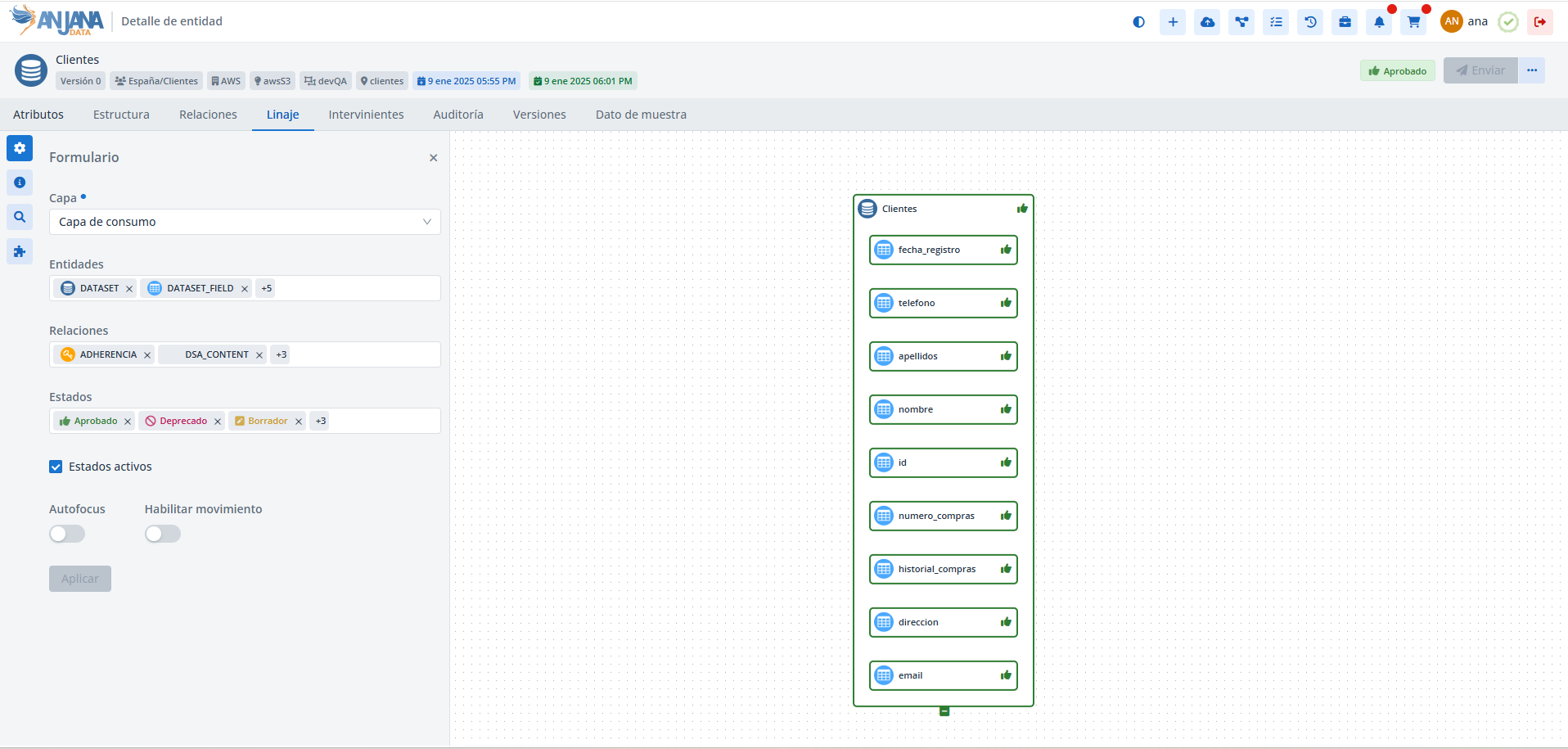
El conjunto de entidades o relaciones que se va a presentar en cada capa se configura en la tabla layer_subtype.
Estructura de la tabla
Cada subtipo elegido por capa definido se caracteriza por los siguientes elementos:
-
layer_id: identificador de la capa en la tabla layer.
-
object_subtype: subtipo de objeto que aparece en la capa (campo name de la tabla object_subtype).
Visión de Administrador
El alta del conjunto de subtipos de objeto que aparecen en cada capa se realiza en el panel de administración de Anjana Data en Layer Subtype:
Al acceder se muestra una tabla que contiene los subtipos por capa definidos para las pantallas de linaje.
La creación de un nuevo subtipo para una capa se realiza mediante el botón New:
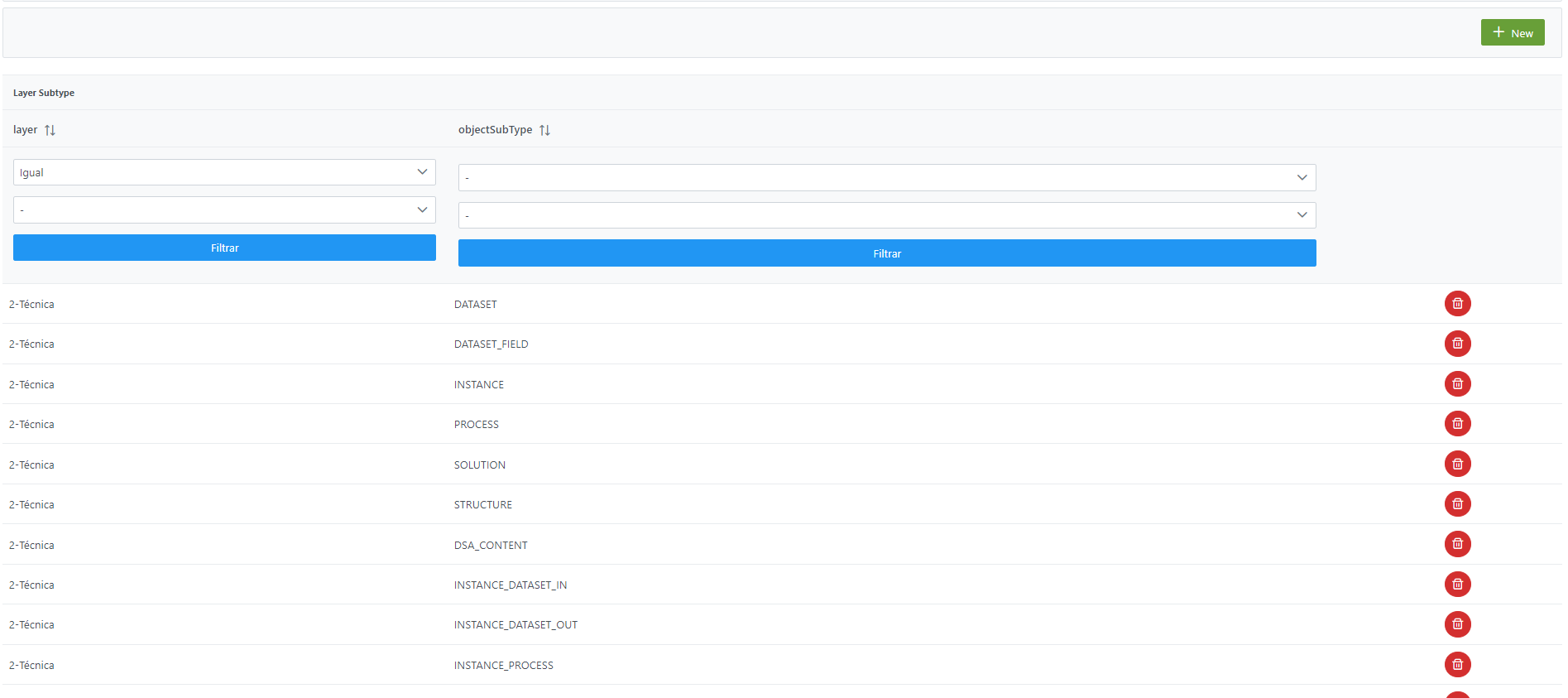
Mediante el wizard de creación se asignan valores a los elementos anteriormente descritos:
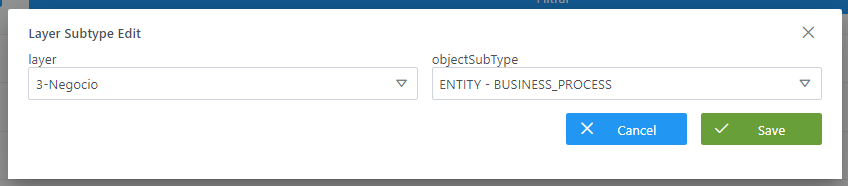
Visión de Desarrollador
Los subtipos por capa del linaje se configuran en la tabla layer_subtype del esquema Anjana. Para ello, hay que rellenar un sql como el siguiente:
INSERT INTO anjana.layer_subtype (layer_id, object_subtype) VALUES
(2, 'DATASET'),
(2, 'DATASET_FIELD'),
(2, 'INSTANCE'),
(2, 'PROCESS'),
(2, 'SOLUTION'),
(2, 'STRUCTURE'),
(2, 'DSA_CONTENT'),
(2, 'INSTANCE_DATASET_IN'),
(2, 'INSTANCE_DATASET_OUT'),
(2, 'INSTANCE_PROCESS'),
(2, 'SOLUTION_OWNED_INSTANCE'),
(2, 'SOLUTION_RELATED_INSTANCE'),
(3, 'BUSINESS_PROCESS');
Agregaciones para el linaje
En el linaje de Anjana es posible representar determinadas relaciones entre entidades como una relación de agregación donde una entidad contiene a otras.
Por defecto una relación en el linaje se mostrará como una línea entre los dos nodos que representan sus entidades origen y destino.
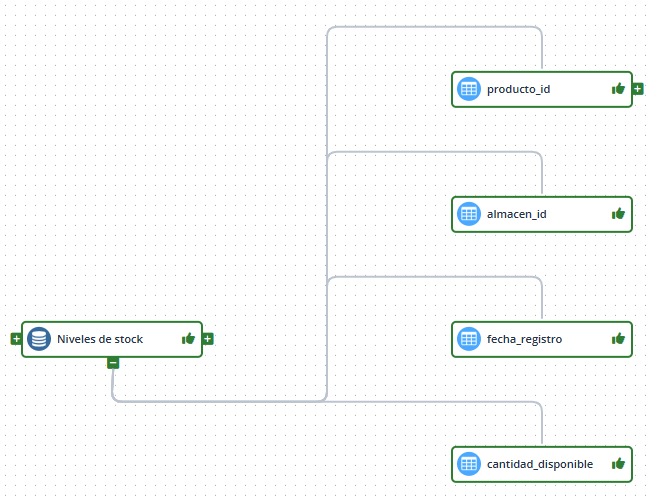
Pero, si está configurada una agregación para esa relación, esa relación pasará a mostrarse como de contenido.
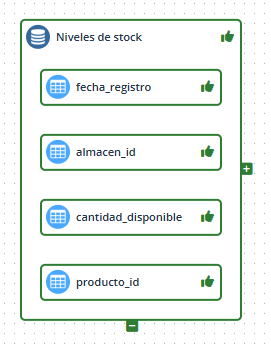
Estas agregaciones se definen en la tabla grouping_lineage.
Estructura de la tabla
Cada agregación registrada se caracteriza por los siguientes elementos:
-
id: identificador único de la tabla.
-
source_subtype: subtipo de objeto que agrega (name de la tabla object_subtype).
-
destination_subtype: subtipo de objeto que aparece en el linaje contenido en entidades de tipo source_subtype (name de la tabla object_subtype).
-
relationship_subtype: subtipo de relación que hay entre source_subtype y destination_subtype y que se representa como una relación de contenido (name de la tabla object_subtype).
Visión de Administrador
El alta de las agregaciones del linaje se realiza en el panel de administración de Anjana Data en Grouping:
Al acceder se muestra una tabla que contiene todas las agregaciones definidas para las pantallas de linaje.
La creación de una nueva agregación se realiza mediante el botón New:
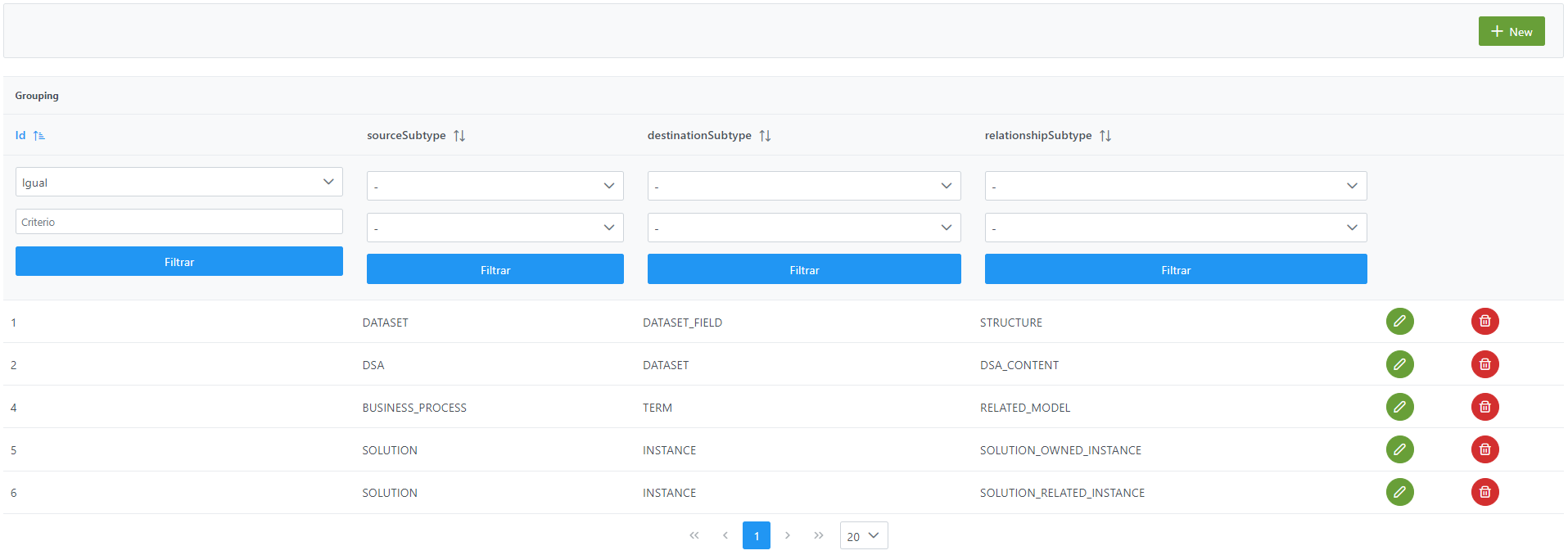
Mediante el wizard de creación se asignan valores a los elementos anteriormente descritos:
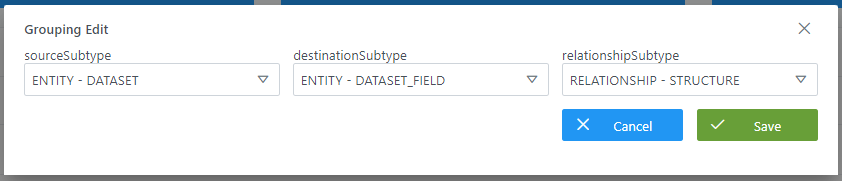
Visión de Desarrollador
Las agregaciones de entidades para el linaje se configuran en la tabla grouping_lineage del esquema Anjana. Para ello, hay que rellenar un sql como el siguiente:
|
INSERT INTO anjana.grouping_lineage (id, source_subtype, destination_subtype, relationship_subtype) VALUES (1, 'DATASET', 'DATASET_FIELD', 'STRUCTURE'), (2, 'DSA', 'DATASET', 'DSA_CONTENT'); |
Agregaciones en las capas del linaje
En las capas del linaje, así como se definen las entidades o relaciones que se cargan en cada una, también se puede configurar qué relaciones de agregación se desea que apliquen. En caso de que no se configure una agregación para una capa, la relación se mostrará como una línea entre los dos nodos correspondientes a las entidades origen y destino de la relación.
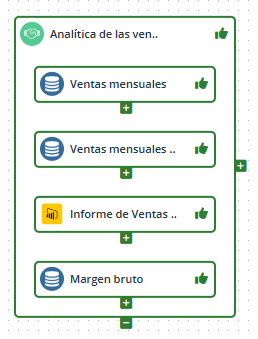
En este caso, en esta capa el DSA no agrega ninguna de las entidades que contiene:
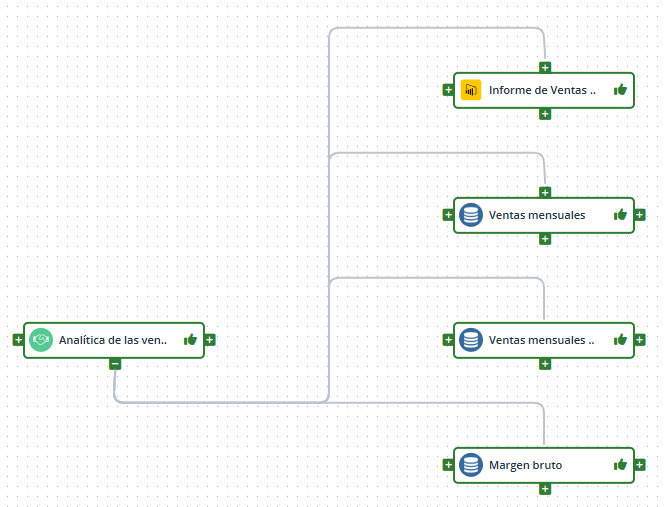
En esta agrega solo a los datasets y no al informe:
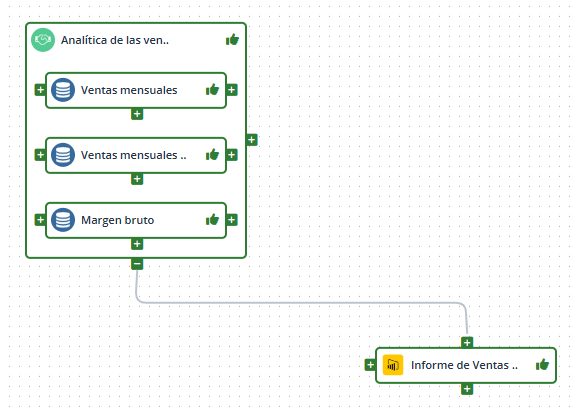
Y en esta agrega a todas las entidades:
Estructura de la tabla
Cada agregación por capa definida se caracteriza por los siguientes elementos:
-
layer_id: identificador de la capa en la tabla layer.
-
grouping_id: identificador de la agregación en la tabla grouping_lineage.
Visión de Administrador
El alta de las agregaciones para cada capa se realiza en el panel de administración de Anjana Data en Layer Grouping:
Unknown Attachment
Al acceder se muestra una tabla que contiene las agregaciones por capa definidas para las pantallas de linaje.
La creación de un nuevo subtipo para una capa se realiza mediante el botón New:
Mediante el wizard de creación se asignan valores a los elementos anteriormente descritos:
Visión de Desarrollador
Las agregaciones por capa del linaje se configuran en la tabla layer_grouping del esquema Anjana. Para ello, hay que rellenar un sql como el siguiente:
|
INSERT INTO anjana.layer_grouping (layer_id, grouping_id) VALUES (2, 1), (4, 2), (4, 1); |
Esquema Hermes de BD
Notificaciones del sistema
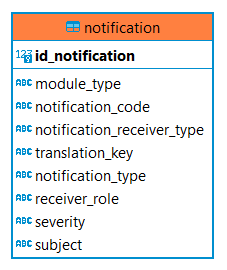
La tabla notification es la tabla que contiene los cuerpos de las diferentes notificaciones que emite el sistema.
Estructura de la tabla
Cada notificación se caracteriza por los siguientes elementos:
-
id_notification: identificador único de la tabla.
-
module_type: módulo al que aplica la notificación, indicar “BG” para Business Glossary, “DC” para Data Catalog o “ALL” si aplica a todo.
-
notification_code: código alfanumérico para poder enviar notificaciones desde las funcionalidades propias de Anjana.
-
notification_receiver_type: indica si la notificación será recibida por un único usuario nominal (‘USER’) o por todos los usuarios que tengan asignado un rol (‘ROLE’).
-
translation_key: clave de traducción correspondiente a la tabla de portuno.translations con el mensaje de la notificación con variables que serán sustituidas en el momento de la creación de la notificación a enviar.
-
notification_type: indica si la notificación es alerta (‘ALERT’), aviso (‘NOTICE’) o alerta de administración (‘ADMIN_ALERT’).
-
receiver_role: rol que recibe la notificación en caso de que notification_receiver_type sea ‘ROLE’.
-
severity: criticidad de la notificación.
-
subject: clave de traducción con el asunto de la notificación.
A continuación se especifican los notification_code para los que deben existir notificaciones en la tabla con el fin de conseguir un correcto funcionamiento de la aplicación:
|
Notification code |
Utilidad |
|
ADHERENCE_FAIL |
Indica el motivo por el que ha fallado la adherencia. |
|
CHECK_CONFIGURATION_IN_PROVIDER |
Error al recuperar la información de un usuario en el provider indicado. |
|
COMPLETED_AUTOMATIC_METADATA |
Indica que ha terminado la importación de metadatos automática. |
|
DATASET_EXPIRATION_TOT_FAIL |
Fallo en el borrado de permisos al expirar un dataset. |
|
DATASET_FAIL |
Fallo en la creación de dataset en sistemas de terceros. |
|
DEACTIVATION |
Aviso de la desactivación a los roles y usuario correspondientes |
|
DELETE_ENTITY |
Avisa del borrado de una entidad. |
|
DELETE_RELATIONSHIP |
Avisa del borrado de una relación. |
|
DEPRECATION |
Avisa a todos los usuarios de un rol que el objeto va a ser deprecado. |
|
DEPRECATION_ADHERED |
Avisa al usuario que el objeto al que estaba adherido (dataset o DSA) va a ser deprecado. |
|
DISADHERENCE |
Se indica que se ha realizado correctamente la desadherencia. |
|
DISADHERENCE_FAIL |
Fallo en la desadherencia indicando el motivo. |
|
DISADHERENCE_LIST |
Informa de los detalles del resultado del proceso de desadherencia. |
|
DISADHERENCE_LIST_OK |
Se indica que la lista de objetos en los que ha tenido éxito la desadherencia. |
|
DSA_FAIL |
La creación de un DSA ha fallado indicando el motivo. |
|
DSA_TRANSFER_FAIL |
Se le indica al administrador que no se ha podido hacer el cambio de unidad organizativa del DSA. |
|
ERROR_AUTOMATIC_METADATA |
Se produce un fallo en la importación de metadatos. |
|
EXCEL_IMPORT |
Notificación con el aviso de error en una creación/edición por Excel |
|
EXCEL_PREPROCESSING |
Aviso de finalización del preprocesamiento de un Excel de edición |
|
EXPIRATION |
El objeto está expirando. |
|
EXPIRATION_OBJECT_FAIL |
Avisa de un fallo en la expiración de un objeto y el motivo |
|
EXPIRATION_ADHERED |
El objeto al que se está adherido ha expirado. |
|
EXPIRATION_WARNING |
Aviso que se envía a los propietarios del objeto debido a que está próxima su expiración. |
|
EXPIRATION_WARNING_ADHERED |
Aviso que se envía a los usuarios adheridos al objeto que indica que está próxima su expiración. |
|
FORM_FAIL |
Errores encontrados en el formulario del objeto. |
|
INDEX_FAIL |
Se ha producido un error en la indexación. |
|
INDEX_RELATIONSHIP_FAIL |
Error de indexación en relaciones. |
|
LICENSE_EXPIRED |
La licencia ha expirado. |
|
LICENSE_EXPIRING |
Aviso de que la licencia, aunque aún es válida, está cerca de expirar. |
|
MUST_DELETE_RELATIONSHIPS_FIRST |
Aviso de la necesidad de un borrado previo de relaciones antes de borrar una entidad |
|
NEW_DSA |
Cuando el usuario solicita la creación de un nuevo DSA. |
|
PENDING_WF_FAIL_ADHERENCE |
Indica el fallo en la creación de un workflow |
|
POLICY_MODIFICATION |
Avisa de la modificación de políticas en un objeto. |
|
REQUIRED_FIELDS |
Avisa de errores en la configuración de las plantillas. |
|
TAXONOMY_BAD_CONFIGURED |
Avisa de algún error en la configuración de la taxonomía de algún subtipo de objeto. |
|
TRANSLATION_FILE_UPLOAD_FAIL |
Avisa de que ha habido un error subiendo el fichero de traducciones a Minio o S3. |
|
USER_CROSS_ROLE_FAIL |
Indica los usuarios que no han sido configurados como cross. |
|
WORKFLOW_DELETE_FAIL |
No se ha podido borrar un workflow. |
|
WORKFLOW_INFO_FAIL |
Error en el workflow debido a que no tenía un workflow info asociado, mediante la api administrativa se pueden ejecutar los últimos pasos del workflow para que no queden en mal estado si sucede este error. |
|
WORKFLOW_OK |
El workflow ha sido creado. |
|
WORKFLOW_FAIL |
Indica el motivo por el que ha fallado la creación de un workflow. |
|
WORKFLOW_TASK_FAIL |
Fallo en la validación de un paso de workflow |
Adicionalmente, los textos correspondientes a las translation_keys en la tabla de traducciones pueden incluir variables entre ## con el fin de que éstas sean sustituidas por los valores correspondientes a la notificación enviada. Un ejemplo de un mensaje con variables sería:
“Ocurrió un error en el borrado del workflow con id #OBJECT_ID#”.
Si alguna de estas variables se usa en una notificación de workflow en la que no le corresponde tener valor, se sustituye por el valor “N/A”.
Las distintas variables que permite Anjana son:
|
Variable |
Utilidad |
|
ACTION |
Acción realizada |
|
EXPIRATION_DAYS |
Días hasta la expiración de un objeto (es un número negativo en caso de que sea una fecha pasada). Sólo se permite en las notificaciones de aviso de expiración cercana y deprecación |
|
OBJECT_ID |
Identificador del objeto |
|
OBJECT_LIST |
Lista de objetos, se usa en notificaciones como las de solicitud de creación de un nuevo DSA |
|
OBJECT_NAME |
Nombre del objeto |
|
OBJECT_SUB_TYPE |
Subtipo del objeto |
|
ORGANIZATIONAL_UNIT |
Unidad organizativa del objeto |
|
ORGANIZATIONAL_UNIT_CHANGED |
Unidad de destino del objeto en una transferencia de OU |
|
REASON |
Motivo de aprobación/rechazo del workflow |
|
REQUEST_REASON |
Motivo de la solicitud de la acción (para las notificaciones de solicitud de creación de dsa o de solicitud de adherencia, por ejemplo) |
|
RESULT |
Resultado de la acción |
|
ROLE |
Rol del usuario que debe realizar la acción o recibe la notificación |
|
TYPE_OBJECT |
Tipo del objeto |
|
USER_NAME |
Usuario que ha realizado la acción |
|
VERSION |
Número de versión del objeto |
|
WORKFLOW_TYPE |
Tipo del workflow lanzado |
Visión de Administrador
El alta de una nueva notificación panel de administración de Anjana Data se realiza en Notifications:
Al acceder se muestra una tabla que contiene el catálogo de notificaciones existentes en la configuración actual.
La creación de una nueva notificación se realiza mediante el botón New:
A continuación, se muestra cómo crear una notificación :
Visión de Desarrollador
Para añadir las notificaciones hay que configurar la tabla notifications del esquema Hermes. Para ello, hay que rellenar un sql como el siguiente:
|
INSERT INTO hermes.notification (id_notification, module_type, notification_code, notification_receiver_type, translation_key, notification_type, receiver_role, severity, subject) VALUES (1,'BG',NULL,'ROLE','NOTIFICATION.1.BG.ROLE','ALERT',NULL,'HIGH','Test'), (3,'BG',NULL,'ROLE','NOTIFICATION.3.BG.ROLE','NOTICE',NULL,'LOW','Test'), (12,'BG','NEW_DSA','ROLE','NOTIFICATION.NEW_DSA','NOTICE','architect','LOW','Test'). (13,'BG','EXPIRATION','ROLE','NOTIFICATION.EXPIRATION','NOTICE','data_owner','LOW','Expiration'), (14,'DC','ERROR_AUTOMATIC_METADATA','ROLE','NOTIFICATION.AUTOMATIC_METADATA','NOTICE','architect','LOW','METADATA'), (15,'DC','DATASET_FAIL','ROLE','NOTIFICATION.DATASET_FAIL','ADMIN_ALERT','admin','HIGH','Dataset creation failure'), (16,'DC','DSA_FAIL','ROLE','NOTIFICATION.DSA_FAIL','ADMIN_ALERT','admin','HIGH','DSA creation failure'); |