
En Anjana Data, los atributos de metadatos son las unidades básicas de información que describen a los objetos (entidades y relaciones) gobernados en la plataforma. Estos atributos permiten documentar de manera estructurada las características técnicas, funcionales y de gobierno de cada activo, facilitando la búsqueda, clasificación y control de calidad entre otros.
Los atributos se configuran en la tabla Attribute Definitions, y pueden ser reutilizados en distintas plantillas de metadatos, aunque nunca pueden aparecer más de una vez en la misma plantilla.
Gracias a esta modularidad, la organización puede crear un catálogo consistente de atributos reutilizables que soporten su modelo de gobierno.
En Anjana Data los distintos tipos de atributos de metadatos soportados son los siguientes:
-
Array de boolean: atributo para indicar uno o varios valores ‘true’ o ‘false’
-
Array de date: atributo para indicar uno o varias fechas
-
Array de decimal: atributo para indicar uno o varios números decimales
-
Array de entities: atributo para elegir una o varias entidades aprobadas en Anjana
-
Array de file: atributo para adjuntar uno o varios ficheros
-
Array de number: atributo para indicar uno o varios números enteros
-
Array de Organizational Unit: atributo para seleccionar una o varias unidades organizativas del listado de todas ellas
-
Array de text: atributo para introducir uno o varios textos cortos de hasta 255 caracteres
-
Array de URL: atributo para introducir uno o varios links a URLs navegables
-
Array de users: atributo para elegir uno o varios usuario de la lista completa de usuarios de la aplicación
-
Boolean: ‘true’ o ‘false’
-
Date: fecha (año, mes, día, hora y minutos)
-
Decimal: número con decimales
-
Enriched Text Area: atributo para introducir un texto largo de hasta 300 mil caracteres enriquecido con formato (negrita, subrayados, cursivas, etc)
-
Entity Container: atributo para elegir una entidad aprobada en Anjana Data y generar relaciones nativas entre entidades. Sólo es posible utilizar este atributo en las entidades DSA, instancia y solución
-
Entity Search: atributo para elegir una entidad aprobada en Anjana Data
-
File: fichero que se almacena internamente en Anjana Data. También se permite descargar el fichero si se tiene permisos de lectura
-
International Text: cuadro de texto normal disponible para los distintos tipos de idiomas disponibles de la aplicación
-
International Text Editor: atributo para introducir un texto largo de hasta 300 mil caracteres enriquecido con formato (negrita, subrayados, cursivas etc) disponible para los distintos tipos de idiomas disponibles de la aplicación
-
International Textarea: atributo para introducir un texto largo de hasta 300 mil caracteres en los distintos idiomas disponibles para la aplicación
-
MultiSelect: atributo para seleccionar uno o varios valores de una lista preconfigurada en la pestaña Reference Metadata
-
MultiSelect con iconos: atributo para seleccionar uno o varios iconos de una lista preconfigurada en la pestaña Reference Metadata
-
MultiSelect con iconos y texto: atributo para seleccionar uno o varios valores (icono+texto) de una lista preconfigurada en la pestaña Reference Metadata
-
Number: atributo para indicar un número entero
-
Number range: selector de número entero entre un mínimo y un máximo definidos
-
Organizational Unit: atributo para seleccionar una unidad organizativa del listado de todas ellas
-
Reference Metadata: lista de valores posibles que se tiene que definir para el atributo
-
Selector con icono: lista de iconos posibles que se tiene que definir para el atributo
-
Selector con icono y texto: lista de valores (icono+texto) posibles que se tiene que definir para el atributo
-
Taxonomía única: árbol de taxonomía
-
Taxonomía de selección múltiple: árbol de taxonomías donde se pueden seleccionar uno o varios valores
-
Text: cuadro de texto normal
-
Text Area: atributo para introducir un texto largo de hasta 300 mil caracteres
-
URL: texto considerado como una URL para que el usuario pueda clicar sobre el atributo y se abra una nueva pestaña con esa URL
-
User: lista completa de usuarios de Anjana Data
Tabla Attribute Definitions del Panel de Configuración (Visión administrador)
Las secciones se configuran en la tabla Sections del Panel de configuración. La definición de las secciones es el segundo paso, tras la creación de los menús, para estructurar las plantillas de metadatos.
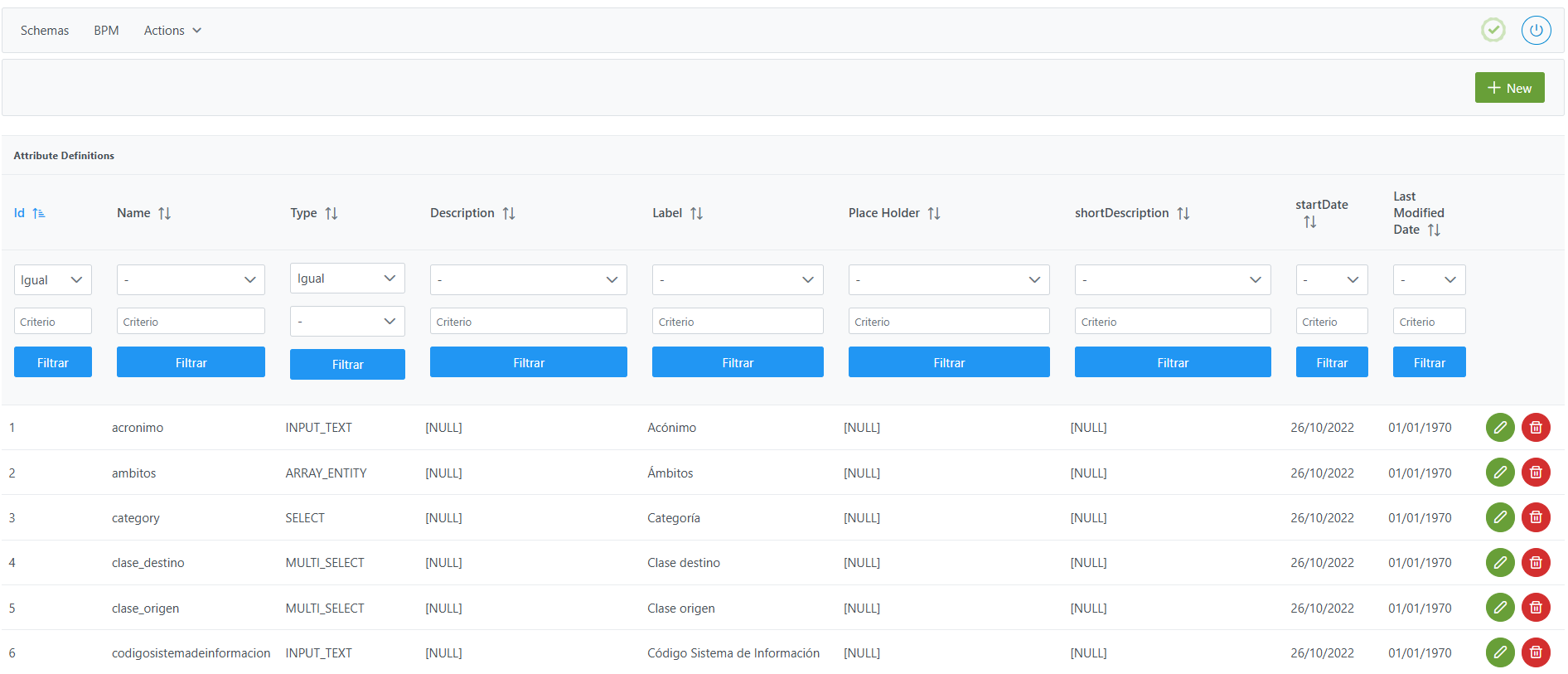
Estructura de la tabla Attribute Definitions
Cada atributo registrado se caracteriza por los siguientes campos:
-
Id: identificador único del atributo.-
Se asigna automáticamente desde el Panel de configuración.
-
-
Name: nombre interno del atributo.
Importante:
-
Debe ser único en toda la tabla, sin importar variaciones en mayúsculas o minúsculas (ej.:
DESCRIPTIONydescriptionse consideran iguales). -
No puede contener espacios ni caracteres como
#,(,),/o: -
Existen valores reservados para capacidades e integraciones nativas de Anjana Data Platform
-
Type: tipo de atributo.-
Determina la naturaleza del dato que se podrá almacenar (texto, número, fecha, usuario, unidad organizativa, fichero, taxonomía, etc.).
-
Ver tabla de equivalencias más abajo.
-
Recomendación: No cambiar el tipo de un atributo ya existente.
-
Puede provocar incompatibilidades con validaciones configuradas en las plantillas.
-
Si existen objetos creados que ya contienen valores de este atributo, el cambio de tipo puede generar errores de indexación (ejemplo: de numérico a alfanumérico).
-
En caso de ser estrictamente necesario, consultar el procedimiento en el apartado de Preguntas Frecuentes.
-
Label: etiqueta visible del atributo en los formularios de metadatos.-
Puede configurarse para internacionalización usando su valor como
config_keyen la tablatranslations, con un registro por cada idioma activo en la aplicación.
-
Nota: El Label no puede repetirse para dos atributos distintos dentro de la misma plantilla.
-
Place Holder: texto de ejemplo que se muestra cuando el campo está vacío.-
Puede configurarse para internacionalización en
translations.
-
Nota: El Place Holder no puede repetirse para dos atributos distintos dentro de la misma plantilla.
-
shortDescription: descripción breve del propósito del atributo.-
Campo opcional, pensado para ayudar a administradores y validadores en la comprensión del atributo.
-
-
Descritpion: descripción más extensa del atributo.-
Puede usarse para detallar instrucciones o contexto adicional y es visible dentro de la plantilla en la

-
Al igual que
LabelyPlace Holder, puede configurarse como clave de traducción.
-
Consideraciones especiales por tipo de atributo
-
Atributos de tipo SELECT, SELECT_IMG, SELECT_IMG_TXT, TREE_SELECT, MULTI_SELECT, MULTI_SELECT_IMG, MULTI_SELECT_IMG_TXT y TREE_MULTISELECT:
-
Requieren definir los valores posibles en la tabla
Attribute Definition Value.
Ejemplo de atributo con valores de referencia
-
-
Atributos de tipo INPUT_RANGE
-
Deben tener validaciones de mínimo y máximo configuradas para que funcione el selector de rango.
-
En ausencia de validaciones, se aplican los valores por defecto:
-
MIN_RANGE y MAX_RANGE, definidos en la tabla
appConfigurationdel Panel de Configuración.
-
-
-
Atributos de tipo ENRICHED_TEXT_AREA y ENRICHED_TEXT_AREA_INTERNATIONAL
-
Admiten subida de ficheros con extensiones:
.gif,.png,.jpgcon restricciones de tamaño.
-
Atributos de clave primaria
Algunas entidades del metamodelo requieren un conjunto mínimo de atributos que actúan como clave primaria.
-
Dataset:
name,infrastructure,path,technology,zone. -
Dataset field:
name,infrastructure,path,technology,zone. -
DSA:
name. -
Proceso:
name,infrastructure,path,technology,zone. -
Instancia de proceso:
name,processAri,solutionAri. -
Solución:
name. -
Entidades no nativas definidas por cliente:
name. -
Relaciones:
name,source,destination.
Atributos obligatorios
Algunos atributos son obligatorios para que Anjana Data funcione correctamente, ya que la plataforma tiene lógica interna asociada a ellos.
-
El campo
namedebe coincidir exactamente con los nombres esperados. -
El campo
attribute_typedebe tener un valor específico. -
Cada atributo obligatorio solo debe aplicarse en las entidades o relaciones que se detallan en la tabla de obligatoriedad.
-
Añadirlos en otros objetos puede provocar errores en la aplicación.
Atributos obligatorios para entidades
|
Valor en campo name |
Aplica a |
||||||
|---|---|---|---|---|---|---|---|
|
Entidad nativa |
Entidad no nativa |
||||||
|
DATASET |
DATASET_FIELD |
DSA |
PROCESO |
INSTANCIA |
SOLUCIÓN |
||
|
description |
X |
X |
X |
X |
X |
X |
X |
|
name |
X |
X |
X |
X |
X |
X |
X |
|
expirationDate |
X |
|
X |
X |
X |
X |
|
|
infrastructure |
X |
|
|
X |
|
|
X |
|
isGoverned |
X |
|
|
|
|
|
X |
|
path |
X |
|
|
X |
|
|
X |
|
physicalName |
X |
|
|
|
|
|
X |
|
technology |
X |
|
|
X |
|
|
X |
|
zone |
X |
|
|
X |
|
|
X |
|
data_format |
X |
|
|
|
|
|
|
|
pi |
X |
X |
X |
|
|
|
|
|
sampleData |
X |
|
|
|
|
|
|
|
datasetFields |
X |
|
|
|
|
|
|
|
fieldDataType |
|
X |
|
|
|
|
|
|
position |
|
X |
|
|
|
|
|
|
termCondFile |
|
|
X |
|
|
|
|
|
dsaContent |
|
|
X |
|
|
|
|
|
isEngine |
|
|
|
X |
|
|
|
|
instanceInDataset |
|
|
|
|
X |
|
|
|
instanceOutDataset |
|
|
|
|
X |
|
|
|
solutionRelatedInstance |
|
|
|
|
|
X |
|
En la siguiente tabla se explica la finalidad y tipología de los atributos indicados en la tabla anterior:
|
Valor en campo name |
Valor en columna attribute_type |
Finalidad del atributo
|
|
description |
TEXT_AREA |
Permite introducir una descripción extensa del objeto. |
|
name |
INPUT_TEXT |
Almacena el nombre lógico de la entidad. |
|
expirationDate |
INPUT_DATE |
Almacena la fecha en la que el objeto expira. |
|
infrastructure |
SELECT |
Indica del entorno donde se encuentra localizado el objeto, usado con technology y zone para identificar un plugin en caso de gobierno activo. Sólo es necesario en caso de que la entidad vaya a tener conexión con la fuente/tecnología para extracción, sample, gob de permisos… |
|
isGoverned |
INPUT_CHECKBOX |
Indica si hay gobierno activo sobre el objeto. Sólo es necesario en caso de que la entidad vaya a tener conexión con la fuente/tecnología para extracción, sample, gob de permisos… |
|
path |
INPUT_TEXT |
Indica la localización del objeto. |
|
physicalName |
INPUT_TEXT |
Indica el nombre físico de la entidad de cara al gobierno activo de éste. Sólo es necesario en caso de que la entidad vaya a tener conexión con la fuente/tecnología para extracción, sample, gob de permisos… |
|
technology |
SELECT |
Indica la tecnología en la que está depositado el objeto, usado con infrastructure y zone para identificar un plugin en caso de gobierno activo. Sólo es necesario en caso de que la entidad vaya a tener conexión con la fuente/tecnología para extracción, sample, gob de permisos… |
|
zone |
SELECT |
Indica la zona donde se encuentra el objeto, usado con infrastructure y technology para identificar un plugin en caso de gobierno activo. Sólo es necesario en caso de que la entidad vaya a tener conexión con la fuente/tecnología para extracción, sample, gob de permisos… |
|
data_format |
INPUT_TEXT |
Indica el formato de los datos del dataset. |
|
pi |
INPUT_CHECKBOX |
Indica si el objeto contiene información personal. Se utiliza de cara a la ofuscación de datos en la funcionalidad de muestra de datos de los datasets. |
|
sampleData |
INPUT_CHECKBOX |
Indica si se puede ver una muestra de los datos del dataset en Anjana. |
|
datasetFields |
INPUT_TEXT |
Indica si los cambios en los dataset_fields afectan al propio dataset. Este atributo debe configurarse oculto en la plantilla (template_attribute) ya que sólo es necesario para poder versionar datasets o no lanzar workflows en caso de modificación de los dataset_fields de un dataset. |
|
fieldDataType |
INPUT_TEXT |
Permite seleccionar el tipo del dato que contiene el field. |
|
position |
INPUT_NUMBER |
Permite indicar el orden del field en un dataset. |
|
termCondFile |
UPLOAD_FILE o UPLOAD_URL |
Permite incluir el fichero o la ruta para acceder a los términos de licencia de un DSA. |
|
dsaContent |
ENTITY_CONTAINER |
Almacena el conjunto de entidades a las que se da acceso a los usuarios por medio del DSA. |
|
isEngine |
INPUT_CHECKBOX |
Permite indicar si el proceso es motor y por tanto puede tener múltiples instancias o si no lo es, pudiendo crear sólo una. |
|
instanceInDataset |
ENTITY_CONTAINER |
Almacena el conjunto de datasets que lee la instancia para su procesamiento. |
|
instanceOutDataset |
ENTITY_CONTAINER |
Almacena el conjunto de datasets que escribe la instancia tras su procesamiento. |
|
solutionRelatedInstance |
ENTITY_CONTAINER |
Almacena el conjunto de instancias relacionadas en la solución. |
Notas:
-
El atributo
pies obligatorio porque se muestra en el Portal de Anjana Data en caso de estar informado en los objetos. Es necesario que este atributo esté definido en la tabla deAttribute Definitionssin importar si se incluye en alguna plantilla.
Atributos obligatorios para relaciones
|
Valor en campo name |
Valor en columna attribute_type |
Finalidad del atributo |
Aplica a |
|
|
ADHERENCE |
Relación no nativa |
|||
|
description |
TEXT_AREA |
Permite introducir una descripción extensa del objeto. |
|
X |
|
name |
INPUT_TEXT |
Almacena el nombre lógico de la entidad. |
X |
X |
|
expirationDate |
INPUT_DATE |
Almacena la fecha en la que el objeto expira. |
X |
|
|
source |
ENTITY_SEARCH |
Permite indicar el origen de una relación o uno de sus extremos. |
|
X |
|
destination |
ENTITY_SEARCH |
Permite indicar el destino de una relación o uno de sus extremos. |
|
X |
|
pae |
INPUT_TEXT |
Permite asociar internamente la adherencia con la solicitud enviada por el usuario. |
X |
|
|
requestReason |
INPUT_TEXT |
Permite almacenar el motivo de la solicitud de adherencia. |
X |
|
Notas:
-
Para poder completar la información de las adherencias, es necesario definir una plantilla con un menú, una sección y los atributos indicados en la tabla anterior.
Atributos obligatorios no referenciados en plantillas
Algunos atributos internos y de carácter reservado deben estar incluidos en Attribute Definition para el correcto funcionamiento de la plataforma.
|
Valor en campo name |
Valor en columna attribute_type |
Finalidad del atributo
|
|
organizationalUnit |
SELECT_ORGANIZATIONAL_UNIT |
Permite indicar la OU de la entidad. Este atributo no debe añadirse a ninguna plantilla ya que sólo es necesario para poder importar entidades por medio de fichero excel. |
|
processAri |
INPUT_TEXT |
Permite indicar el proceso de la instancia. Este atributo no debe añadirse a ninguna plantilla ya que sólo es necesario para poder importar instancias por medio de fichero excel. |
|
solutionAri |
INPUT_TEXT |
Permite indicar la solución propietaria de la instancia. Este atributo no debe añadirse a ninguna plantilla ya que sólo es necesario para poder importar instancias por medio de fichero excel. |
|
source |
ENTITY_SEARCH |
Permite indicar el origen de una relación o uno de sus extremos. En caso de existir alguna plantilla de relación no nativa, se debe incluir en la plantilla. Si no existe, tan solo es necesario definir el atributo. |
|
destination |
ENTITY_SEARCH |
Permite indicar el destino de una relación o uno de sus extremos. En caso de existir alguna plantilla de relación no nativa, se debe incluir en la plantilla. Si no existe, tan solo es necesario definir el atributo. |
Importante:
Eliminar cualquiera de estos atributos de la tabla Attribute Definition puede provocar errores en:
-
Descarga del excel de importación de metadatos.
-
Errores a la hora de gobernar procesos, instancias y soluciones, así como generar el linaje técnico.
-
Errores a la hora de crear relaciones entre entidades del metamodelo.
Alta de un atributo en la tabla Attribute Definitions
El alta de un nuevo atributo de metadatos implica registrar en la tabla Attribute Definitions un nuevo campo que podrá ser reutilizado en diferentes plantillas de entidades o relaciones.
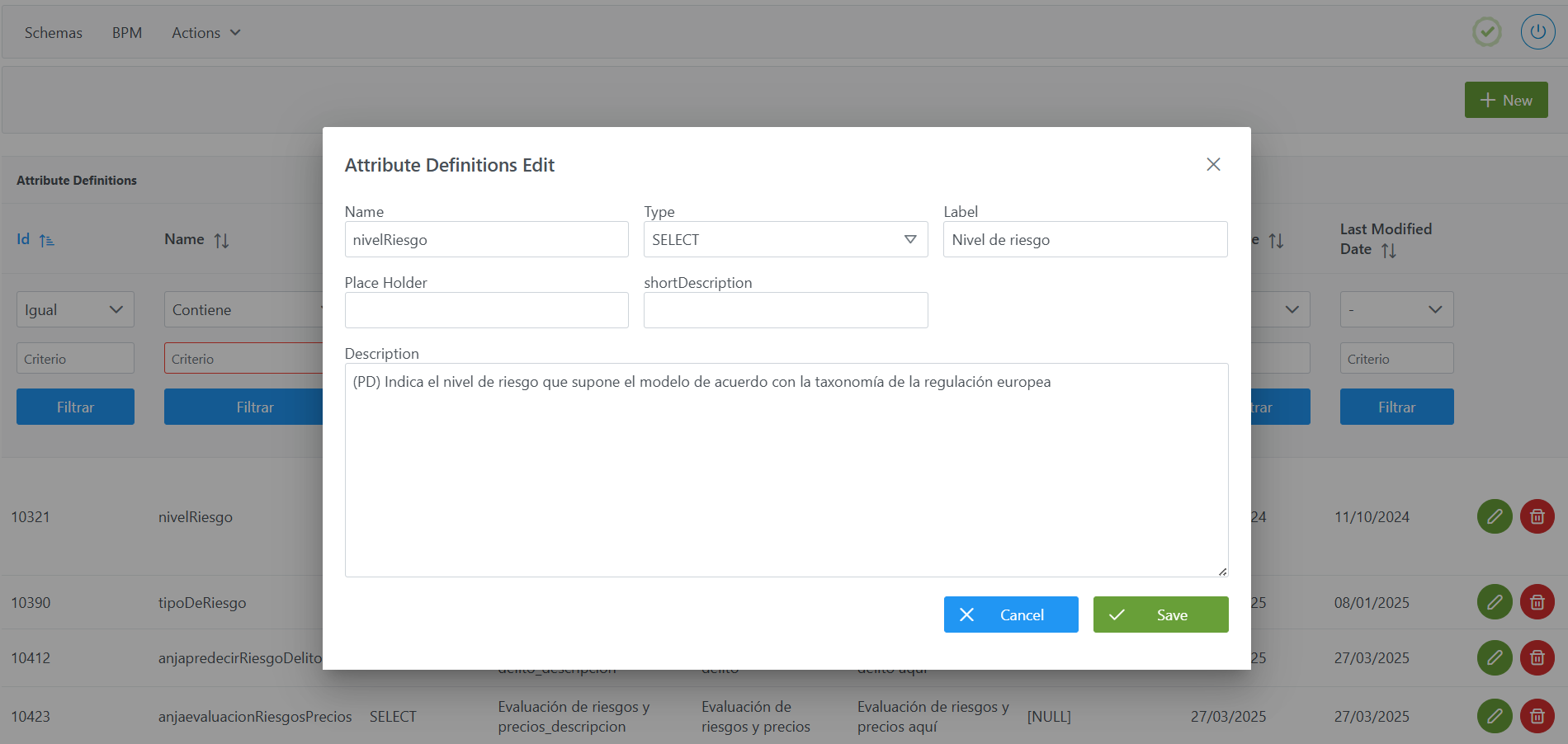
Para añadir un nuevo atributo:
-
Pulsar el botón New en la esquina superior derecha. Esto abrirá un asistente (wizard) con los campos definidos en el apartado Estructura de la tabla Attribute Definitions.
-
Completar los campos del atributo conforme a la estructura descrita:
-
Name: nombre interno del atributo (ej.:nivelRiesgo). -
Type: tipo de atributo (ej.:SELECT). -
Label: etiqueta visible en el formulario. En caso de internacionalización, se debe dar de alta también en la tablatranslationspara cada idioma. -
Place Holder: texto de ejemplo cuando el campo está vacío (opcional). En caso de internacionalización, se debe dar de alta también en la tablatranslationspara cada idioma. -
shortDescription: descripción breve del atributo (opcional). -
Description: descripción más extensa o instrucciones de uso. En caso de internacionalización, se debe dar de alta también en la tablatranslationspara cada idioma. (ej.: (PD) Indica el nivel de riesgo que supone el modelo de acuerdo con la taxonomía de la regulación europea).
-
-
Pulsar en Save para guardar el atributo o en Cancel para descartar.
Notas:
-
Tras el alta de un nuevo atributo, es necesario ejecutar la acción Clear cache desde el Panel de configuración (
Actions > Clear cache) para que los cambios sean visibles en el Portal de Datos. -
En caso de atributos de tipo selectores (ej.:
SELECT,MULTI_SELECT,TREE_SELECT…), se deben configurar posteriormente los valores posibles en la tablaAttribute Definition Values(ver apartado correspondiente). -
El alta del atributo en
Attribute Definitionsno implica su aparición en las plantillas, para ello, se debe configurarTemplate Attribute. -
Se debe prestar atención a la configuración de los atributos obligatorios, especialmente en los campos
nameyType.
Modificación de un atributo en la tabla Attribute Definitions
La modificación de un atributo en la tabla Attribute Definitions debe realizarse con especial precaución, ya que puede tener distintos impactos en las plantillas donde el atributo esté siendo utilizado y en los objetos ya creados en el Portal de Datos.
Campos que pueden modificarse sin impacto elevado:
-
Label,Place Holder,DescriptionyshortDescriptionpueden ajustarse, ya que solo se utilizan como apoyo informativo en los formularios:-
Si no se ha configurado internacionalización, los textos pueden modificarse directamente.
-
Si existe internacionalización, la modificación debe realizarse en la tabla
translations, asegurando que lasconfig_keycorrespondientes (definidas a partir del Label/Place Holder originales) siguen siendo consistentes.
-
Campos cuya modificación requiere precaución:
-
Type: no se recomienda modificar el tipo de un atributo una vez que este se encuentra en uso, ya que:-
Puede invalidar validaciones configuradas en las plantillas.
-
Puede generar inconsistencias en la indexación de Solr si el tipo nuevo no es compatible con el anterior (ejemplo: cambiar un atributo numérico a alfanumérico).
-
Si es absolutamente necesario cambiarlo, seguir las recomendaciones del apartado de FAQ.
-
-
Name: nunca debe cambiarse si el atributo ya está en uso en alguna plantilla, ya que:-
Puede generar inconsistencias en la indexación de Solr
-
Puede generar inconsistencias en la configuración de Filtros (tabla
Filter Confs) . -
Puede generar inconsistencias en la configuración de validaciones de tipo Depends On (tabla
Template Attribute validations) . -
Podrían producirse errores en workflows.
-
Si fuera imprescindible cambiarlo, sería necesario ejecutar un Clear data en el Panel de configuración (
Actions > Clear data) y reindexar toda la información.
-
Importante:
-
Después de modificar cualquier atributo, ejecutar la acción Clear cache desde el Panel de configuración (
Actions > Clear cache) para que los cambios sean efectivos en el Portal de Datos. -
La modificación de traducciones requiere ejecutar la acción de subida de traducciones desde el Panel de configuración (
Actions > Upload translation files) para que los cambios sean efectivos en el Portal de Datos.
Configuración de atributos mediante acceso directo a la base de datos (Visión desarrollador)
La parametrización de los atributos de metadatos también puede realizarse directamente sobre la base de datos, en la tabla anjana.attribute_definition. Esta tabla contiene la definición de todos los atributos reutilizables en las plantillas de entidades y relaciones del metamodelo.
|
Columna |
Tipo de dato |
Restricciones / Notas |
|---|---|---|
|
id_attribute_definition |
int4 (INTEGER) |
PRIMARY KEY. Identificador único del atributo. Se gestiona mediante secuencias de BD. |
|
description |
varchar(300000) |
Texto descriptivo del atributo. Puede utilizarse como clave de traducción para internacionalización. |
|
label |
varchar(255) |
Clave de traducción que se mostrará como etiqueta del atributo en formularios. Debe existir en la tabla |
|
last_modified_date |
timestamp |
Fecha de la última modificación del atributo (campo informativo). |
|
name |
varchar(255) |
Nombre interno del atributo. No admite espacios, |
|
place_holder |
varchar(255) |
Clave de traducción para el texto de marcador de posición (placeholder). No obligatorio. |
|
short_description |
varchar(255) |
Breve explicación del atributo, para mostrar en formularios. |
|
start_date |
timestamp |
Fecha de creación del atributo (campo informativo). |
|
attribute_type |
varchar(255) |
Tipo del atributo, según las tipologías soportadas (ejemplo: |
A continuación se muestra un script de ejemplo para configurar un atributo de tipo SELECT para catalogar el nivel de riesgo de un Sistema de IA:
INSERT INTO anjana.attribute_definition
(id_attribute_definition, description, "label", last_modified_date, "name", place_holder, short_description, start_date, attribute_type)
VALUES(10321, '(PD) Indica el nivel de riesgo que supone el modelo de acuerdo con la taxonomía de la regulación europea', 'Nivel de riesgo', '2024-10-11 11:41:09.720', 'nivelRiesgo', NULL, NULL, '2024-10-11 11:41:09.720', 'SELECT');
Importante:
-
Una vez ejecutado el insert, ejecutar la actualización de secuencias de la tabla. (Desde el Panel de configuración en
Actions > Reset DQ sequencesse pueden actualizar las secuencias de todas las tablas, incluida esta). -
Todo el peso de la lógica de configuración recae en el desarrollador que ejecuta las queries SQL directamente sobre la tablas. Se recomienda revisar cuidadosamente el apartado de Estructura de la tabla.