
The designed architecture allows ANJANA DATA to govern different technologies, clusters and environments, and also makes it independent of the product versions of each vendor: For each version there will be a microservice with the specific functions that may exist in each of them and, if needed, it can be isolated to avoid incompatibilities or security issues. With this, Anjana Data is the ideal tool to govern complex environments and architectures, such as multi-cloud, hybrid, big data, etc., and makes it ready for new technologies and/or new uses of information technologies yet to come.
In this way, ANJANA DATA offers a versatility and growth agility that allows offering new versions with expanded capabilities in very short periods of time, as well as a total customization capacity for the aforementioned functionalities.
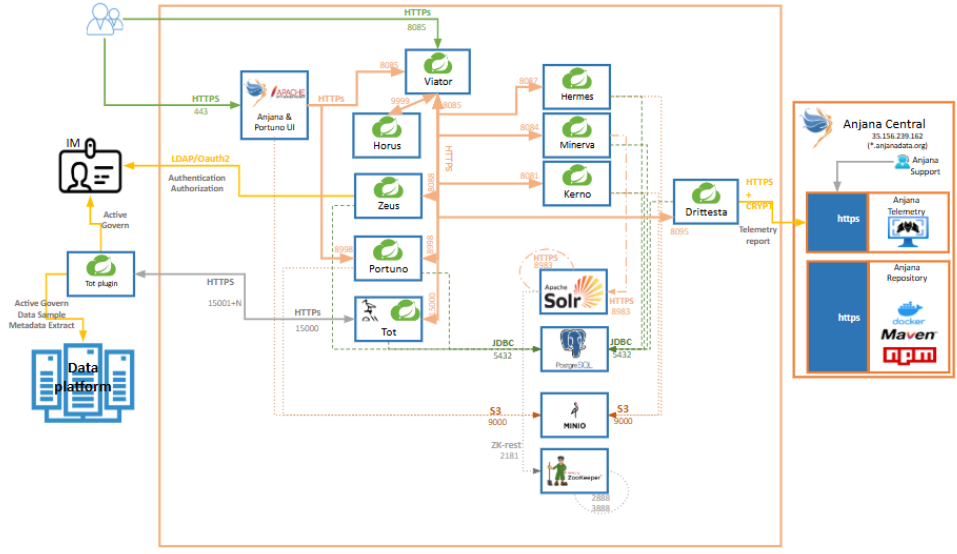
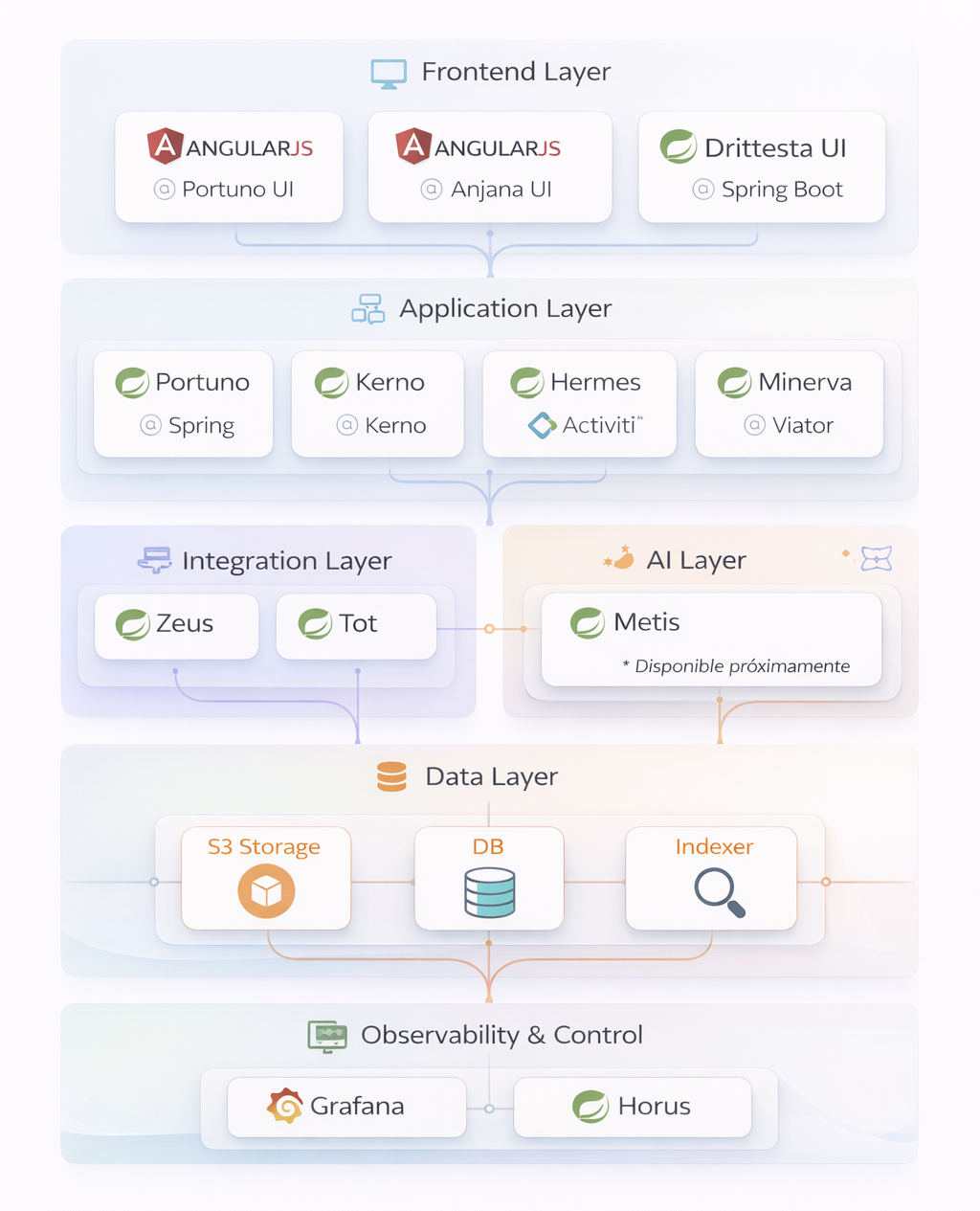
The technical architecture of ANJANA DATA uses the Spring Cloud technology stack in its most recent versions, including the corresponding product modules (Springboot, Eureka, Config, Security). In order to achieve maximum independence with respect to technology / architecture, ANJANA DATA also makes use of a repository to store files or records.
In this regard, the technology stack can be grouped into the following blocks:
Microservices based on Spring Cloud technologies

-
The Spring Cloud technologies used and the product composition make the implementation of high availability viable at all points of the platform, many of which are de facto redundant due to the technology used and the minimum platform requirements.
-
Thanks to Spring Cloud + Eureka as a registration and synchronization manager, a dynamic and redundant microservices structure is formed, allowing a complete customization layer of the system that enables the delocalization and load balancing of virtually all its modules, both internal and public.
-
Through the agnostic approach offered by Spring JPA technology and the customization part based on Spring Boot microservices, these pieces could easily be replaced by other technologies with similar functionality.
-
To monitor the microservices ecosystem, ANJANA DATA uses a Spring Boot Admin web administration panel, through which the status and detailed metrics of each service can be known, observed, easily consumed by the user or integrated into an external monitoring platform.
-
Regarding scalability, the use of highly efficient multi-thread technologies and the possibility of practically unlimited horizontal scaling in each of its critical components mean that the initial volume of concurrent users and governed data sets is very high. In figures: with the recommended configuration, a volume of 700 users and 100,000 data assets can be served without the need for queuing.
Internal traffic with API gateway

-
ANJANA DATA uses the API Gateway to redirect internal traffic in a very efficient manner. Thus, for example, the controllers responsible for performing low-level system tasks (listing tables, creating directories, etc.) are not inside the backends, but are instead invoked by the microservices.
-
This design allows the tool to evolve; if any controller becomes obsolete, the service in question can be dismounted and replaced in the most effective way.
Front-end with Angular

-
Both the portal and the administration panel present their front-end layer built in Angular
-
The use of this technology allows generating a friendly interface fully operable by both technical and business users.
-
Fully integrable with the back-end technology to offer all the functionalities that allow complete control of Anjana Data and its modules (data portal, lineage, audit, creation/modification, data marketplace, workflows, etc.)
-
Fully manageable administration portal that allows configuring Anjana without the need to write code or access databases.
Storage technologies

-
The use of well-established open-source technologies reduces costs while achieving high reliability, interoperability and evolution. ANJANA DATA uses PostgreSQL for the data persistence layer and Apache SolR as a search engine.
-
Bulk storage of records, being performed in SolR (in later versions ElasticSearch will be incorporated), a specific technology based on redundancy and scalability, is practically unlimited and easily configurable.
-
Document management, configuration and translation files stored in MinIO or AWS S3, a storage server that allows storing various types of structured and unstructured data.
-
The coordination of distributed processes is carried out in an agile and reliable manner thanks to Apache Zookeeper technology.
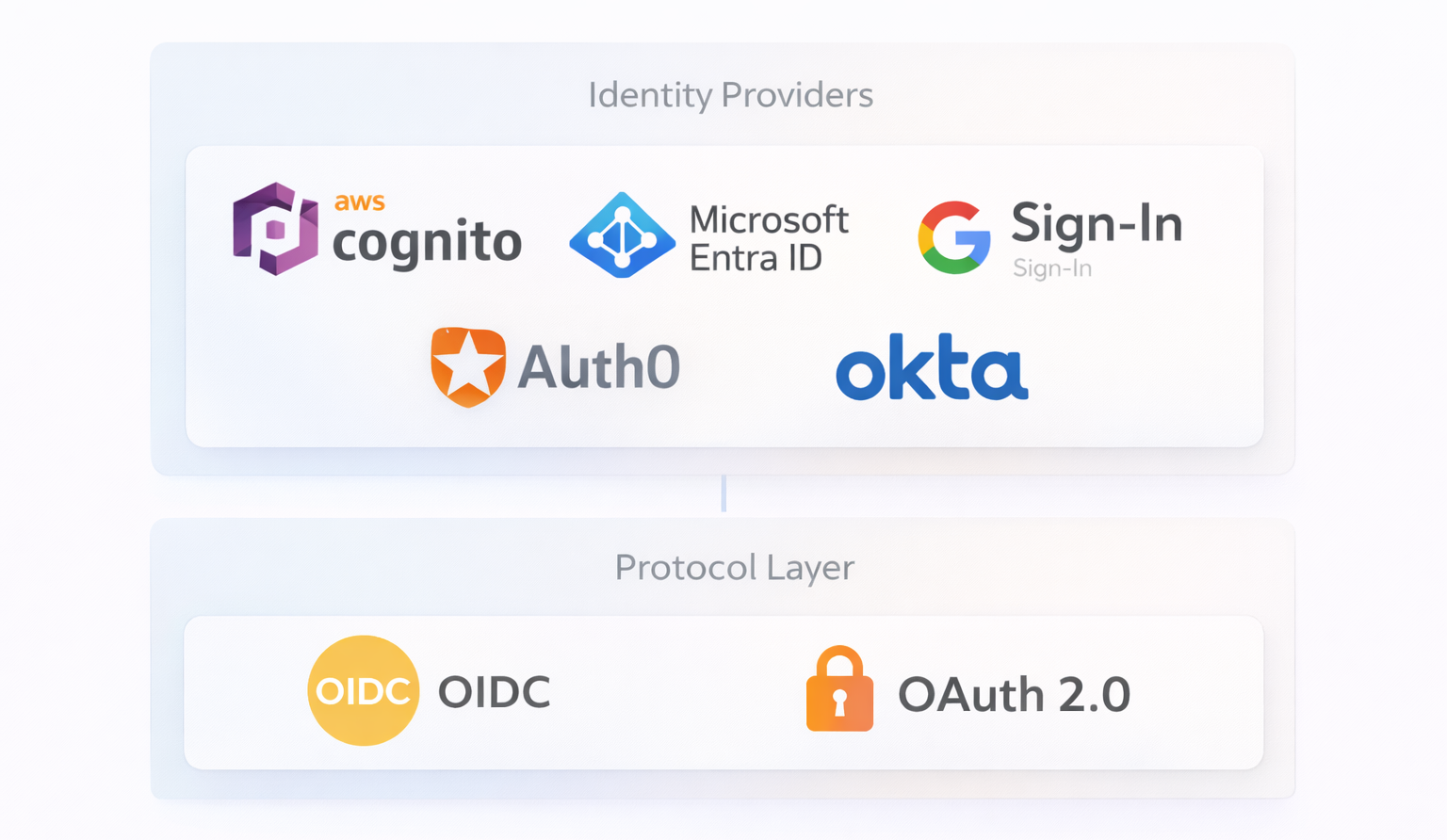
Authentication and authorization
-
Anjana Data is designed so that the user can choose which provider they want to authenticate against and authorization is done with the internal configuration in the database, configurable from Portuno.
-
LDAP Protocol: The Zeus module is compatible with the LDAP service, whether with OpenLdap or Active Directory schemas.
-
Oauth2 Protocol (OIDC Azure/AWS/GCP/Auth0): The Oauth2 protocol is an authentication protocol; authorization must be carried out through another circuit which varies in each of the Cloud providers: Bpm under BPMN 2.0 standard
|
CLOUD |
Authentication |

|
Oauth2 circuit via OIDC Azure client |

|
Oauth2 circuit via OIDC AWS client |

|
Oauth2 circuit via OIDC GCP client |

|
Oauth2 circuit via OIDC Okta-Auth0 client |

Anjana Data incorporates Activiti as an open-source BPM fully integrated into the solution, supporting the BPMN2.0 standard, through which fully customized validation workflows can be designed and implemented:
-
The workflows are based on the configured roles, organizational units and permissions model and are also integrated with the alerts, messages and notifications module to foster collaboration among participants.
-
In Anjana Data, predefined workflows are available, but additional workflows can also be created to validate the different actions performed in Anjana Data (by object type, by action type, by role type, by business area, ...).
-
For each workflow, all validation steps (order and role/roles that validate) can be configured, as well as customizing the notifications sent to the different participants for each step, or even adding specific actions supported by the standard (script execution, launching another action, sending email, API calls, ...).
-
Additionally, complex workflows based on the values of the metadata attributes of an object can be configured (e.g. different workflows for assets that include personal data).
-
All workflows with all their information (workflow steps, status, actions, users involved, etc.) are traced and can be viewed through the Anjana Data UI, where they can also be filtered to display only the workflows of interest and access the detail of each workflow.
Integration and interoperability mechanisms
Regarding integration with various technologies, ANJANA DATA is fully integrable and interoperable, being able to connect with any technology through the following methods:
-
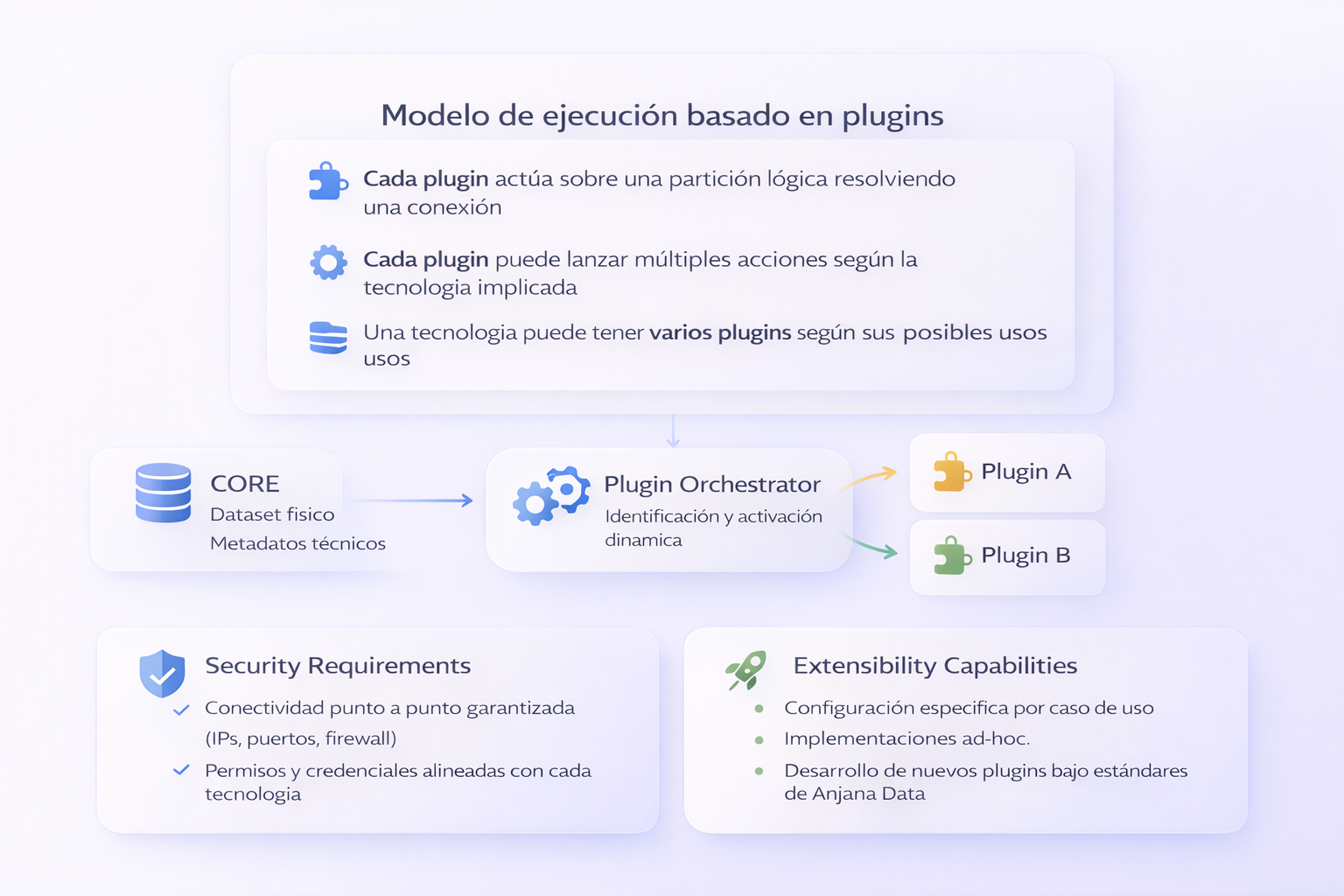
Plugins and Agents developed by the Anjana Data Product team, which offer native integrations for various technologies, covering different operating modes and configuration options (see details in integrations Zone).
-
Ad-hoc developed plugins and connectors: An SDK (software development kit) is provided that allows both customers and partners to autonomously develop their own connectors to implement specific required functionalities and uses without the need to alter the product.
-
Using the different API layers provided by Anjana Data, both for importing and exporting the desired information as well as for executing specific actions in the application. In this sense, Anjana Data has 3 API layers: public, administrative and configuration; each with a specific purpose and aimed at different profiles.
In addition, the ability to execute custom actions in the application as well as to launch external scripts is added, thanks to the following alternatives:
-
Using an internal interceptor and its corresponding SDK, which is provided with Anjana Data
-
Through the use of the BPM module, based on Activiti, following the BPMN 2.0 standard, from which any type of workflow can be defined, and in whose steps the launch of said actions and/or scripts can be defined.
-
Using the different API layers provided by Anjana Data, in the same way as indicated above. In this sense, the use of APIs can be orchestrated by an internal scheduler or executed from triggers.
Regarding the Plugins, these allow Anjana Data to execute both actions on the governed systems and to retrieve metadata and incorporate it into Anjana Data, enabling assisted and automatic metadata import.
RESTful API with Swagger
Finally, to ensure that Anjana Data is 100% interoperable, the entire solution is fully API-enabled with a RESTful API with Swagger. Thus, Anjana Data has three API layers that serve different purposes:
-
Public: The public API layer offers user functionalities to interact with Anjana; from this API layer the various modules offered by the tool can be accessed, such as: Creation/modification of objects, lineage, history, audit, alerts and notifications, and data marketplace.
-
Administrative: Through the administrative API layer, the metamodel can be managed in administrator mode, meaning that modifications to the metamodel (creation/modification of objects) can be made without the need to go through the validations defined for users.
-
Configuration: This API configuration layer allows managing the tool configuration in all its dimensions:
-
Management of Organizational Units, Roles and permissions.
-
User Management.
-
Management of Objects, validation workflows and attribute templates
-
Management of attributes and validations on attributes.
-
Search filter management
-
Language management
-
Dashboarding

Regarding reporting capabilities, Anjana Data incorporates Grafana as open-source self-service and reporting tools fully integrated into its architecture stack.
Dashboarding: The Anjana Data data model is open; in this way, the information contained in the tool can be extracted for use in any Dashboarding tool, such as Grafana, Azure PowerBI, Google Looker or Amazon QuickSight, among others.
Dashboarding with Grafana: Anjana Data offers, in its native integration with Grafana, the possibility of building custom reports and dashboards autonomously and dynamically without the need for programming, using functions such as clicks and drag & drops. Additionally, Grafana provides the ability to perform time series analysis and configure real-time alerts that facilitate the monitoring and management of the data governance implementation as well as data quality.
Cloud-first
Anjana Data works as a common layer for technology-agnostic data governance thanks to its metadata-centric approach, while offering extended native bidirectional integrations with the most common data platform technologies.
As mentioned earlier, this vision makes it ideal for governing complex environments and architectures, such as multi-cloud, hybrid, big data, etc., and also makes it ready for new technologies and/or new uses of information technologies yet to come.
In any case, despite this vision, given that the vast majority of organizations are evolving toward a Cloud-first approach and the major cloud providers are setting the direction for data platforms and their technology architectures, Anjana Data leverages in this regard cloud-native technologies and approaches while extending its capabilities through the native integration of the solution into the most common data platform architectures.
Thus, Anjana Data complements and extends the capabilities of native cloud data catalogs (AWS Glue Catalog, Azure Purview, GCP Data Catalog, ...) to offer advanced features for the implementation of effective and efficient proactive and preventive data governance through the automation of common technical processes.

In particular, for this type of ecosystem, the following aspects stand out:
-
Agnostic, modular and flexible architecture, but integrated into cloud ecosystems thanks to its native integrations with technologies and native services from the various Cloud providers.
-
Cloud-first approach for unlimited scalability and elasticity through the use of cloud managed services that also facilitate service deployment, as well as infrastructure provisioning, management and operation.
-
Data governance adapted to the organization's needs thanks to its customization capabilities and flexibility.
-
No vendor lock-in, no black boxes, and with an API-first approach that offers full interoperability, as well as extensibility tools that facilitate the development of new integrations autonomously.
-
Internal brokerage system for identity management federation and the delegation of authentication and authorization to cloud-native identity and access management systems.
-
Accelerates the adoption of next-generation data architectures such as Data Lakehouse, DataOps, Data Fabric, Data Mesh and Data Marketplace.
-
Strategic alliances and partnerships with Microsoft, AWS, Google and Cloud expert integrator partners, working jointly with the architecture teams of the various providers to leverage the evolution of their native technologies.