
Introduction
This document aims to describe the technical solution of the ANJANA DATA tool. Throughout the document, each piece that makes up the technological ecosystem of the solution is described both at a general level and for each individual component.
Anjana Data is built on a state-of-the-art modular microservices architecture, natively Big Data and Cloud, API-first, with no vendor lock-in or black boxes, in a flexible, open and extensible ecosystem offering full scalability and interoperability through the use of consolidated state-of-the-art open-source technologies as well as managed services.
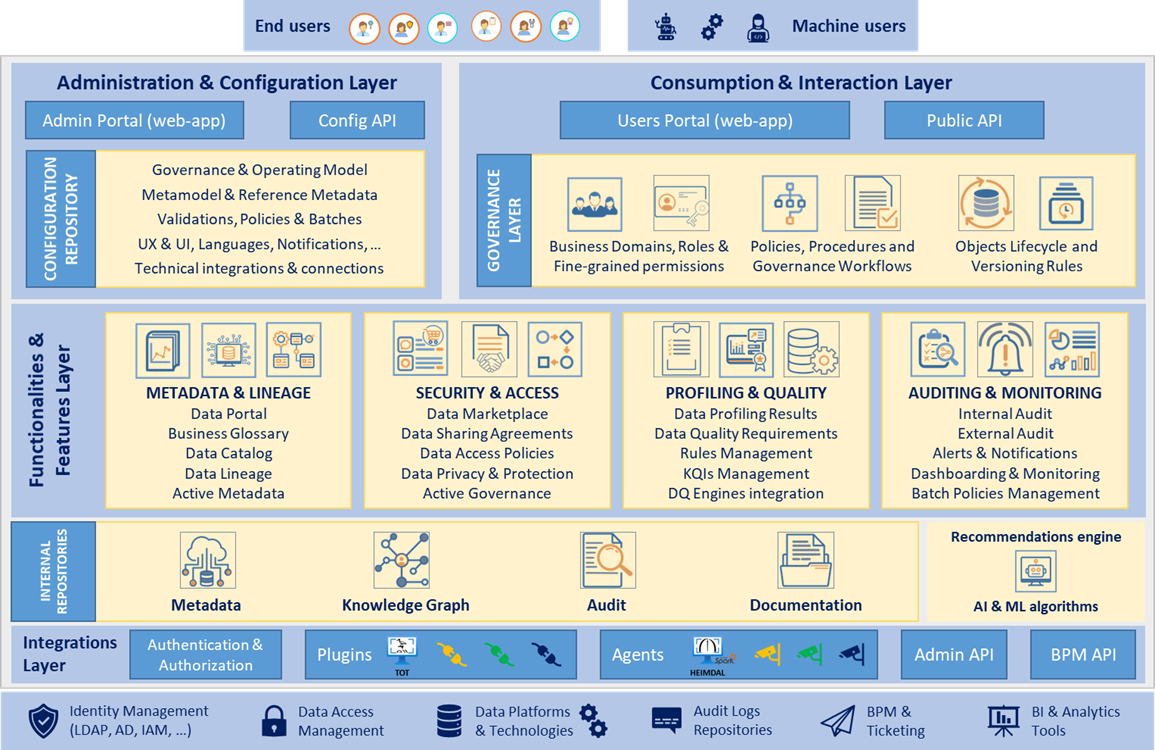
One of the differentiating values of Anjana Data lies in its microservices-oriented architecture, fully scalable and interoperable with extended native integration across a multitude of technologies and data platforms, with a special focus on Big Data and Cloud-native technologies.
Furthermore, thanks to the design of its architecture and the technologies used, Anjana Data offers a series of capabilities in terms of flexibility, adaptability, customization, extensibility, scalability and interoperability that make it one of the most cutting-edge and innovative solutions on the market from a technical standpoint. Thus, Anjana Data allows solution customization through parameterization without the need for code development, while also offering a resource kit for developing new plugins and agents for integration with other technologies, and provides different API layers for bidirectional interaction with the solution modules.

Thanks to the various fully independent yet integrated and interconnected microservices, the capabilities of the different layers and modules of the solution are decoupled while ensuring full coherence and a unified user experience across the entire platform.
From an operational perspective, Anjana Data places data governance at the beginning of the data value chain, making it the "single window" from which the various necessary processes are orchestrated over the corresponding pieces to ensure the correct management of a governed data ecosystem.
That is why Anjana Data's integration vision with the different pieces of a data ecosystem goes far beyond basic integrations and includes the following types of native integration that represent a paradigm shift in the understanding of a data governance solution.

Thanks to all these integrations with different pieces of an organization's data ecosystem and to Anjana Data's philosophy based on interoperability, it is possible to automate a multitude of technical processes orchestrated in a governed manner from integrated demand management within data governance, thereby abstracting data management and governance from the technologies of storage, processing and exploitation platforms.
Capacity Requirements
|
Component |
Cores (X86 64bit) |
Ram (GB) |
|
Anjana & Portuno UI |
2 |
4 |
|
Zeus |
2 |
2 |
|
Viator |
2 |
1 |
|
Kerno |
2 |
4 |
|
Hermes |
2 |
4 |
|
Minerva |
2 |
4 |
|
Portuno |
2 |
4 |
|
Solr (< 1tb of storage) |
2 |
8 |
|
Postgresql |
4 |
4 |
|
Horus |
1 |
2 |
|
Minio |
1 |
1 |
|
Tot |
1 |
1 |
|
Tot plugin (optional) |
1 |
1 |
|
Dritesta |
1 |
1 |
Open-source technology inventory
The following details the technologies used to implement each of the different modules that make up the Anjana Data solution. The programming language used has been Java 17 for the Backend.
|
Technology |
More information |
|
Angular |
|
|
Spring Cloud |
|
|
LDAP |
|
|
SOLR |
|
|
PostgreSQL |
|
|
Spark |
|
|
Spring Boot |
|
|
Activiti |
|
|
Grafana |