
Modelo de integración
Extracción de metadatos
Se utilizan los métodos que ofrece el driver de JDBC mediante los cuales se accede a la definición de esquemas y tablas.
El plugin extrae los siguientes atributos que deben llamarse igual en la tabla attribute_definition, campo name para que aparezcan en la plantilla:
-
catalog con el valor de catalog en la base de datos
-
schema con el valor de schema en la base de datos
-
physicalName y name con el mismo valor, el nombre de la tabla
-
path con la concatenación de los valores de catalog, schema and table
-
infrastructure con el valor seleccionado
-
technology con el valor seleccionado
-
zone con el valor seleccionado
También envía los siguientes atributos relativos a los campos del recurso pedido:
-
name con el valor del campo correspondiente
-
physicalName con el valor del campo correspondiente
-
defaultValue con el valor por defecto definido para el campo correspondiente
-
fieldDataType con el tipo de dato definido para el campo correspondiente
-
length con el tamaño del campo correspondiente
-
incrementalField indicando si es un campo incremental
-
position posición que ocupa el campo correspondiente
-
precision con el valor de la precisión del campo correspondiente
-
nullable indicando si el campo correspondiente es nullable
-
pk indicando si el campo es una pk
-
description con el valor correspondiente para el campo
Los atributos a crear en Anjana deben de tener los siguientes tipos:
|
Nombre de atributo |
Tipo de atributo |
|
catalog |
INPUT_TEXT |
|
schema |
INPUT_TEXT |
|
physicalName |
INPUT_TEXT |
|
path |
INPUT_TEXT |
|
infrastructure |
SELECT |
|
technology |
SELECT |
|
zone |
SELECT |
|
name |
INPUT_TEXT |
|
defaultValue |
INPUT_TEXT |
|
fieldDataType |
INPUT_TEXT |
|
length |
INPUT_NUMBER |
|
incrementalField |
INPUT_CHECKBOX |
|
position |
INPUT_NUMBER |
|
precision |
INPUT_NUMBER |
|
nullable |
INPUT_CHECKBOX |
|
pk |
INPUT_CHECKBOX |
|
description |
ENRICHED_TEXT_AREA_INTERNATIONAL |
El plugin es capaz de realizar la extracción de metadatos sobre los tipos de elementos que se configuren para él. Por defecto se intentará extraer Tablas (TABLE) y Vistas (VIEW). Si la tecnología acepta otras, revisar el YAML mencionado en Configuración.
Documentación genérica de Java sobre los campos disponibles en JDBC si algún driver no disponibiliza su catálogo de metadata https://docs.oracle.com/javadb/10.10.1.2/ref/rrefcrsrgpc1.html
Muestreo de datos
Utilizando el driver genérico de JDBC de Java se ejecuta una query simple de SELECT para acceder a un número limitado de elementos de la tabla para recuperar una muestra de los datos almacenados. Adicionalmente se sustituyen los valores de los campos sensibles por asteriscos.
Si la muestra de datos se hace sobre una tabla del esquema default de Hive (o database por defecto), Anjana puede mostrar algún error debido a la discrepancia del nombre de las columnas que gestiona el driver y el nombre de las mismas en una consulta select. Esta discrepancia impide que se asocie de manera correcta el valor con la columna representada en Anjana.
Vendors disponibles
Para cada vendor se detalla qué versiones se soportan, el formato de conexión, y que permisos se requieren para las funcionalidades del plugin (extracción y sampleo de datos).
⚠️ Nota
Si, al ejecutar la extracción de metadato conectando con una base de datos de Oracle, sale el siguiente error:
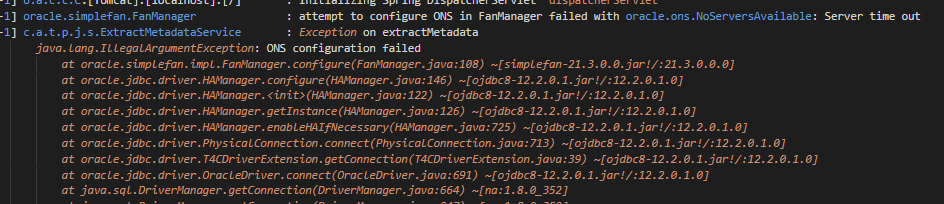
Es necesario incluir en el comando de ejecución del descriptor de servicio del plugin “-Doracle.jdbc.fanEnabled=false” (info del problema: https://support.oracle.com/cloud/faces/DocumentDisplay?_afrLoop=190836230347481&_afrWindowMode=0&id=2616175.1&_adf.ctrl-state=qk122q2vr_4)