
Introducción
Este glosario recoge los conceptos, pantallas y componentes específicos de Anjana Data que se mencionan a lo largo de la documentación oficial. Su objetivo es facilitar la comprensión de la herramienta a todos los perfiles de usuario —tanto técnicos como de negocio— ofreciendo una definición clara, accesible y alineada con el modelo de gobierno de datos de la compañía.
Cada entrada describe de manera sencilla qué significa el término dentro del contexto de Anjana Data, cuál es su función principal y, cuando resulta útil, ejemplos de uso práctico. De esta forma, se asegura que cualquier lector, independientemente de su experiencia previa, pueda interpretar correctamente las referencias al producto y relacionarlas con su propio rol dentro de la organización.
El glosario está pensado como un punto de consulta rápida y un marco común de vocabulario, reforzando la coherencia de la documentación y mejorando la experiencia tanto de aprendizaje como de uso de la plataforma.
Buscador de objetos
Es la pantalla del Portal de datos que permite localizar rápidamente cualquier objeto gobernado en Anjana Data (datasets, APIs, informes, términos de negocio, modelos de IA...). Ofrece un buscador semántico y filtros personalizables ayudan a encontrar información de manera eficiente, incluso en catálogos amplios y complejos.
Ejemplo de uso: un Data Steward utiliza el Buscador de objetos para localizar todos los datasets asociados al dominio Facturación.
Claves de traducción
Las claves de traducción son identificadores que permiten configurar la aplicación en multiidioma, de forma que cada elemento de Anjana Data pueda mostrarse en el idioma seleccionado por cada usuario.
Estas claves se aplican a todos los componentes configurables de la plataforma, incluyendo:
-
Roles y dominios
-
Menús y secciones de las plantillas de metadatos
-
Atributos y descripciones
-
Notificaciones y mensajes del sistema
Gracias al uso de claves de traducción, la plataforma garantiza una experiencia de usuario coherente y adaptada al idioma preferido de cada persona, facilitando la adopción del modelo de gobierno en organizaciones multilingües.
Panel de configuración
Es la interfaz reservada a usuarios con rol de administración o configuración funcional. Desde el Panel de configuración se definen aspectos clave del modelo operativo (roles, permisos, dominios de datos, workflows, notificaciones), el metamodelo (entidades y relaciones) y las plantillas de metadatos.
En ocasiones se conoce internamente como Portuno, ya que este es el nombre del microservicio asociado a las capacidades de configuración de la plataforma.
🔑 Acceso: se realiza a través de la URL del dominio seguida de /configpanel/login. Ejemplo: https://<midominio>.anjanadata.net/login
Ejemplo de uso: un administrador accede al Panel de configuración para crear un nuevo workflow de modificación de modelos de IA.
Portal de datos
Es la interfaz principal de Anjana Data orientada a los usuarios de negocio. Desde el Portal de datos se puede consultar, colaborar en la creación del catálogo/glosario y solicitar acceso a activos de datos e información de la organización. Su objetivo es facilitar el acceso al repositorio centralizado de metadatos de la organización, reduciendo la fricción entre negocio y tecnología.
🔑 Acceso: se realiza a través de la URL del dominio seguida de /login. Ejemplo: https://<midominio>.anjanadata.net/login
Ejemplo de uso: un usuario de negocio accede al Portal de datos para buscar información sobre clientes y solicitar acceso a un dataset.
Dominio de datos / dominio funcional / dominio de negocio / unidad organizativa
Un dominio de datos es el mecanismo mediante el cual se establece la custodia de los activos de datos dentro del Glosario de Negocio o del Catálogo de Datos, permitiendo representar la realidad de la organización en términos de dominios funcionales o semánticos de datos.
Los activos de datos se clasifican en las diferentes Unidades Organizativas (o dominios de datos) que se han identificado en la organización. De esta forma, los usuarios que desempeñan un rol de gobierno en una unidad organizativa son responsables de los activos de datos que pertenecen a dicho dominio.
Cada dominio actúa, además, como base de los mecanismos de autorización, determinando qué usuarios pueden ejercer qué roles sobre los activos de datos asociados.
⚠️ Nota importante: no se deben confundir los dominios de datos con la jerarquía organizativa o el organigrama de una empresa. Mientras que la estructura jerárquica suele ser cambiante, los dominios de datos deben permanecer relativamente estables en el tiempo, ya que reflejan la semántica y la lógica de negocio de la organización.
Metamodelo de Anjana
El conjunto de entidades y relaciones que se van a poder gobernar desde la Plataforma de Anjana Data es lo que se conoce como Metamodelo. Ese metamodelo es totalmente configurable, es decir, la organización tiene que realizar el ejercicio de definir una estrategia de gobierno en el que, entre otras cosas, define qué entidades quiere gobernar y qué tipos de relaciones quiere establecer entre los diferentes tipos de entidades para ofrecer la visión end2end de los datos.
Entidad
Es la representación de cualquier elemento de datos dentro del mapa semántico de la organización. Dependiendo de la naturaleza de las entidades, se clasifican en entidades del Glosario de Negocio (en el caso de que estén más relacionadas con el Negocio) o entidades del Catálogo de Datos (más relacionadas con TI).
En Anjana Data es posible crear tantos tipos de entidades como se desee definir.
Algunos ejemplos de entidades pueden ser términos de negocio, métricas, dimensiones, informes, procesos de negocio o reglas de calidad de datos.

Además, también es posible definir entidades que representan activos físicos como datasets, procesos o esquemas de BD.

Algunas de estas entidades son nativas de Anjana y sobre ellas la aplicación lleva a cabo cierta lógica especificada más adelante:
-
Dataset y dataset_fields
-
DSA
-
Proceso e instancia de proceso
-
Solución
Relación
Es el mecanismo que proporciona Anjana Data para establecer un enlace entre entidades que de algún modo se encuentran conectadas, ya sea por asociación, involucramiento, pertenencia, etc. Por ejemplo, relaciones entre términos de negocio que permiten calcular una métrica o las reglas de calidad de datos que aplican a un determinado informe.
Mediante las relaciones es posible establecer el ciclo de vida end2end de los datos, es decir, es posible gobernar el linaje técnico (cómo fluyen los datos por los diferentes sistemas de TI y qué transformaciones sufren), cómo se utilizan los datos con fines analíticos, la semántica asociada a los datos, dónde se aplican puntos de calidad para verificar la conformidad de los datos, o incluso qué usuarios están consumiendo ciertos datos.
Las relaciones permiten vincular entidades del Glosario de Negocio entre sí, pero también relacionar entidades del Glosario de Negocio con entidades del Catálogo de Datos para localizar, por ejemplo, dónde se almacena un determinado término de negocio.
Igual que ocurre con las entidades, en Anjana es posible configurar tantos tipos de relaciones como se necesite, que convivirán con el conjunto de relaciones nativas (o internas) de la aplicación. Estas relaciones nativas asocian entidades nativas entre sí y no son dadas de alta desde el wizard de creación de objetos si no por medio de funcionalidades propias de estas entidades. Estas relaciones son:
-
STRUCTURE: Relación entre un dataset y sus dataset_fields
-
DSA_CONTENT: Relación entre un DSA y las entidades que contiene
-
INSTANCE_PROCESS: Relación entre un proceso y sus instancias
-
INSTANCE_DATASET_IN: Relación entre una instancia y sus datasets de entrada
-
INSTANCE_DATASET_OUT: Relación entre una instancia y sus datasets de salida
-
SOLUTION_RELATED_INSTANCE: Relación entre solución y sus instancias relacionadas
-
SOLUTION_OWNED_INSTANCE: Relación entre solución y sus instancias propias
Objetos del metamodelo nativo
A pesar de la flexibilidad del metamodelo de Anjana Data y la posibilidad, por tanto, de crear tantas entidades como se desee representar, el metamodelo del Catálogo de Datos se basa en los siguientes objetos principales: datasets (y sus dataset_fields), DSAs, procesos (y sus instancias) y soluciones junto con sus relaciones, metadatos y linaje.
DATASET
En Anjana Data, un dataset es una entidad del metamodelo que representa un conjunto de datos, independientemente de su naturaleza técnica o formato físico.
Un dataset puede representar datos estructurados (ej. tablas en bases de datos relacionales como Oracle, SQL Server o MySQL), semiestructurados (ej. ficheros en data lakes en formatos como CSV, JSON, Parquet) o no estructurados (ej. documentos, imágenes, audios o vídeos).
Asimismo, un dataset puede ser persistente (almacenado de forma estable en un repositorio o sistema) o transitorio (generado de manera temporal durante la ejecución de un proceso o flujo de trabajo).
De esta forma, el concepto de dataset en Anjana Data actúa como un abstracción unificada, que permite gobernar de manera homogénea activos de datos de distinta tipología y origen, garantizando la trazabilidad, el linaje y la aplicación de políticas de gobierno sobre ellos.
DATASET FIELD
Un dataset field es la unidad mínima de un dataset estructurado. Representa un campo o columna dentro del dataset y cuenta con sus propios metadatos (nombre, tipo de dato, formato, reglas de validación, clasificaciones, etc.), lo que permite gobernar la información con un nivel de detalle más granular.
En Anjana Data, los dataset fields son entidades que se utilizan para documentar y gestionar las características individuales de los atributos de un dataset, facilitando procesos como la búsqueda, la clasificación, el linaje y el control de calidad de los datos.
DSA (Data Sharing Agreements)
Es un activo lógico que puede incluir una o varias entidades para facilitar la agrupación de activos físicos de datos en un nivel más cercano al consumo de la información.
Es el mecanismo mediante el cual se facilita el acceso a los datos gobernados y permite compartir datos entre proveedores y consumidores por medio de la firma de un contrato por el cual el usuario se compromete a cumplir unas condiciones de uso de los datos.
Es enriquecido con metadatos de negocio.
Proceso
Se corresponde con grupos de funciones definidas para extraer datos desde las fuentes, moverlos, transportarlos, transformarlos, explotarlos y/o generar nuevos datos (ETLs, scripts de transformación, ejecuciones de controles de calidad, generación de reportes…).
Instancia de Proceso
Un proceso puede tener una o más instancias en función de los diferentes escenarios de ejecución en base a posibles configuraciones que pueda tomar, con el fin de ejecutar los módulos de software desarrollados en distintas situaciones o plataformas.
Una instancia es una ejecución específica de un proceso con una parametrización y un conjunto de datasets de entrada y de salida. Permite la definición de las piezas de un framework sin necesidad de dar de alta un proceso para cada una de ellas. Una vez definida, cada ejecución es auditable.
Solución
La solución representa el “contrato de datos” que autoriza el movimiento de datos a través de los procesos. De esta forma, se garantiza que existen autorizaciones para el movimiento de datos entre sistemas o aplicaciones. Por tanto, es un activo lógico que engloba varias instancias de procesos junto con sus datasets relacionados para tener una visión end-2-end de las ejecuciones.
Una solución tiene un responsable de su administración y mantenimiento que garantiza su ejecución.
Los metadatos de la solución pueden ser enriquecidos con metadatos de negocio.
La diferencia entre las soluciones y los DSA es que las soluciones posibilitan el consumo por parte de los procesos de TI y las aplicaciones mientras que los DSAs gobiernan el consumo por parte de los usuarios consumidores.
Ciclo de vida de los objetos
Los objetos nativos de Anjana Data tienen su propio ciclo de vida, de forma que los objetos gobernados van pasando por diferentes estados que permiten realizar desde un gobierno pasivo tradicional a un gobierno activo con gestión de impactos.
A continuación se presenta el ciclo de vida por el que pasan los objetos en Anjana.
Ciclo de vida de las Entidades nativas de Anjana
Las entidades nativas de Anjana tienen un ciclo de vida diferente al de las entidades que no son nativas. En este apartado se presentan los estados por los que puede pasar una entidad nativa:

-
Importado: Las entidades creadas usando la Extracción Automática de Metadatos quedan en estado Importado.
-
Borrador: Si se modifica una entidad Importada para rellenar sus datos, pasa a estado Borrador.
Si se crea por medio de Subida de Excel o de creación Manual (ya sea usando la API o el propio portal), se crea una entidad nativa en estado Borrador.
Si se modifica una entidad Aprobada, se crea una nueva versión con estado Borrador.
Si se modifica una entidad Rechazada, ésta pasa a estado Borrador.
-
Pendiente: Una vez se envía la entidad a validar, pasa a estado Pendiente.
-
Aprobado: Si todos los validadores aprueban una entidad, ésta pasa a estado Aprobado. Si se vuelve a editar, se genera una entidad con dichos cambios en estado Borrador.
Una entidad con estado Desactivado puede volver a estar Aprobada tras la activación de la misma.
-
Rechazado: Si algún validador rechaza la validación de una entidad, pasa a estado Rechazado. Si se vuelve a editar para corregir los motivos del rechazo, vuelve al estado Borrador.
-
Deprecado: El estado Deprecado se aplica a una entidad nativa cuando, tras realizarse modificaciones significativas que generan una nueva versión, la versión anterior queda automáticamente marcada como obsoleta una vez aprobada la nueva versión.
-
El término proviene del inglés deprecated y, aunque no existe como tal en español, en Anjana Data se utiliza para reflejar la obsolescencia programada de un activo de datos ante un proceso de migración o cambios relevantes en su definición o comportamiento.
-
Las reglas que determinan qué modificaciones generan una nueva versión —y, por tanto, provocan que la anterior pase a estado Deprecado— son configurables dentro de la plataforma.
-
Además, es posible deprecar una entidad con el objetivo de indicar que, pasado un tiempo, expirará.
-
Expirado: Una vez se cumpla la fecha de expiración que se haya marcado en una entidad nativa, ésta pasa automáticamente a estado Expirado.
Versionado
El versionado de los activos tiene dos objetivos fundamentales:
-
Disponer de un mecanismo de control de impactos desde el punto de vista de la interoperabilidad, calidad, seguridad, protección de datos, etc.
-
Disponer de un histórico de versiones con los cambios más significativos.
La organización establece qué cambios en las plantillas de metadatos de las entidades nativas de Anjana deben generar una nueva versión del mismo.
Es posible configurar cualquiera de los siguientes casos:
-
Que se genere una nueva versión de un objeto cuando se produzca cualquier cambio en atributos significativos de la plantilla de un objeto.
-
Que versione un DSA cuando cambien las entidades a las que da acceso.
-
Que versione una instancia cuando se cambian los dataset input o output de la instancia.
-
Que versione una solución cuando cambien sus instancias relacionadas.
-
-
Que se produzca versionado cuando un atributo adquiere un valor concreto.
-
Que se genere una nueva versión del dataset cuando cambia un determinado atributo de un dataset field o se añade o elimina un dataset field.
-
Que se edite una entidad deprecada o expirada para la que no hay versión más actual aprobada.
Deprecación
La deprecación de las entidades nativas de Anjana desencadena una serie de cambios en los objetos y el lanzamiento de avisos a usuarios relacionados con ellos.
-
DATASET:
-
Sus dataset_fields serán deprecados
-
Los DSAs en los que está incluido NO serán deprecados
-
Las instancias a las que esté asociado NO serán deprecadas
-
Se enviará un aviso a los owners del dataset
-
Se enviará un aviso a los adheridos al DSA y a sus owners
-
Se enviará un aviso a los owners de las instancias relacionadas
-
-
DSA:
-
Se enviará un aviso a los owners de DSA
-
Se enviará un aviso a los owners de las entidades que contiene el DSA
-
Se enviará un aviso a los adheridos al DSA
-
-
PROCESO:
-
Las instancias asociadas al proceso serán deprecadas
-
Se enviará un aviso a los owners de proceso
-
-
INSTANCIA DE PROCESO:
-
El proceso relacionado con una instancia NO se deprecará
-
La solución propia NO se deprecará
-
Las soluciones relacionadas NO se deprecarán
-
Se enviará un aviso a los owners del proceso
-
Se enviará un aviso a los owners de las soluciones relacionadas
-
Se enviará un aviso a los owners de las soluciones propias (que son los owners de la instancia)
-
Se enviará un aviso a los owners de los dataset que la instancia escribe (DATASET_OUTPUT)
-
Se enviará un aviso a los usuarios adheridos de los dataset que la instancia escribe (DATASET_OUTPUT)
-
-
SOLUCIÓN:
-
Las instancias propias NO se deprecarán
-
Las instancias relacionadas NO se deprecarán
-
Se enviará un aviso a los owners de solución
-
Expiración
La expiración de las entidades nativas de Anjana desencadena una serie de cambios en los objetos y el lanzamiento de avisos a usuarios relacionados con ellos.
-
DATASET:
-
Si está gobernado, se procederá a eliminar sus permisos de acceso que se hayan incluido con DSAs
-
Sus dataset_fields serán expirados
-
Los DSAs en los que esté incluido NO serán expirados
-
Las instancias a las que esté asociado NO serán expiradas
-
Se enviará un aviso a los owners del dataset
-
Se enviará un aviso a los adheridos al DSA que contenga el dataset y a sus owners
-
Se enviará un aviso a los owners de las instancias relacionadas
-
Se enviará un aviso a los owners de las entidades relacionadas con el dataset y de los DSAs que contengan al dataset
-
-
DSA:
-
Si contiene entidades gobernadas se procederá a eliminar el grupo y todos los permisos que tuviera
-
Se enviará un aviso a los owners de DSA
-
Se enviará un aviso a los owners de las entidades que contiene el DSA
-
Se enviará un aviso a los adheridos al DSA
-
Se enviará un aviso a los owners de las entidades relacionadas con el DSA
-
-
PROCESO:
-
Las instancias asociadas al proceso serán expiradas
-
Se enviará un aviso a los owners de proceso
-
Se enviará un aviso a los owners de las entidades relacionadas con el proceso
-
-
INSTANCIA DE PROCESO:
-
El proceso relacionado con una instancia NO se expira
-
La solución propia NO se expira
-
La solución relacionada NO se expira
-
Se enviará un aviso a los owners del proceso
-
Se enviará un aviso a los owners de las soluciones relacionadas
-
Se enviará un aviso a los owners de las soluciones propias (que son los owners de la instancia)
-
Se enviará un aviso a los owners de los dataset que la instancia escribe (DATASET_OUTPUT)
-
Se enviará un aviso a los usuarios adheridos de los dataset que la instancia escribe (DATASET_OUTPUT)
-
Se enviará un aviso a los owners de las entidades relacionadas con la instancia
-
-
SOLUCIÓN:
-
Las instancias propias NO se expiran
-
Las instancias relacionadas NO se expiran
-
Se enviará un aviso a los owners de solución
-
Se enviará un aviso a los owners de las entidades relacionadas con la solución
-
Ciclo de vida de las Entidades no nativas de Anjana
Las entidades no nativas de Anjana pasan por los siguientes estados en su ciclo de vida:

-
Importado: Las entidades creadas usando la Extracción Automática de Metadatos quedan en estado Importado.
-
Borrador: Si se modifica una entidad Importada para rellenar sus datos, pasa a estado Borrador.
Si se crea por medio de Subida de Excel o de creación Manual (ya sea usando la API o el propio portal), se crea una entidad no nativa en estado Borrador.
Si se modifica una entidad Aprobada, se crea una nueva versión con estado Borrador.
Si se modifica una entidad Rechazada, ésta pasa a estado Borrador.
-
Pendiente: Una vez se envía la entidad a validar, pasa a estado Pendiente.
-
Aprobado: Si todos los validadores aprueban una entidad, ésta pasa a estado Aprobado. Si se vuelve a editar, se genera una entidad con dichos cambios en estado Borrador.
Una entidad con estado Desactivado puede volver a estar Aprobada tras la activación de la misma.
-
Rechazado: Si algún validador rechaza la validación de una entidad, pasa a estado Rechazado. Si se vuelve a editar para corregir los motivos del rechazo, vuelve al estado Borrador.
-
Desactivado: Si la entidad no nativa deja de tener sentido es posible desactivarla, pasando de estado Aprobado a estado Desactivado.
Ciclo de vida de las Relaciones
Las relaciones pasan por los siguientes estados en su ciclo de vida:
-
Importado: Las relaciones creadas usando la Extracción Automática de Metadatos quedan en estado Importado.
-
Borrador: Si se modifica una relación Importada para rellenar sus datos, pasa a estado Borrador.
Si se crea por medio de Subida de Excel o de creación Manual (ya sea usando la API o el propio portal), se crea una relación en estado Borrador.
Si se modifica una entidad Aprobada, se crea una nueva versión con estado Borrador.
Si se modifica una entidad Rechazada, ésta pasa a estado Borrador.
-
Pendiente: Una vez se envía la relación a validar, pasa a estado Pendiente.
-
Aprobado: Si todos los validadores aprueban una relación, ésta pasa a estado Aprobado. Si se vuelve a editar, se crea una relación con dichos cambios en estado Borrador.
Una relación Desactivada puede volver a estar Aprobada tras la activación de la misma.
-
Rechazado: Si algún validador rechaza la validación de una relación, pasa a estado Rechazado. Si se vuelve a editar para corregir los motivos del rechazo, vuelve al estado Borrador.
-
Desactivado: Si la relación deja de tener sentido es posible desactivarla, pasando de estado Aprobado a estado Desactivado.
Workflows/Flujos de validación
¿Qué son?
Los workflows representan la secuencia de pasos de validación que se deben seguir para que una acción realizada en Anjana Data por un usuario pueda ser validada por otros usuarios, estableciendo un entorno de trabajo colaborativo basado en roles.
Los workflows permiten materializar los procedimientos del modelo de gobierno de la organización y asegurar que todos los roles intervinientes en los procesos ejercen su responsabilidad, son informados y/o consultados.
Estas son algunas de sus características:
-
Los workflows son configurables y cada uno de ellos tiene un diagrama de estados propio
-
Cuando un usuario envía una solicitud en Anjana, automáticamente se genera el workflow correspondiente al rol del usuario y la petición realizada si no hay reglas configuradas que lo eviten
-
En cada workflow un usuario de cada rol asignado debe validar la solicitud para que pase a aprobada. En caso de que un usuario rechace la validación, el workflow quedará automáticamente cancelado
-
Cada estado del workflow implica la revisión y validación de la petición por uno o más usuarios dependiendo de sus roles y del tipo de petición. Esta revisión se materializa con la aprobación o el rechazo del validador al workflow
-
Las validaciones siempre irán acompañadas de un comentario del usuario indicando el motivo de su respuesta
-
Es posible que se lancen workflows en Anjana con más pasos de los que finalmente se validarán. Los intervinientes en el flujo de aprobación pueden variar en función de:
-
El rol del usuario que lanza el flujo de validación
-
El usuario que lanza la validación
-
El tipo de acción bajo validación
-
El tipo de objeto bajo validación
-
El subtipo de objeto bajo validación
-
Atributos de la plantilla del objeto bajo validación
-
La decisión del validador
-
La unidad organizativa del objeto
-
La versión del objeto
-
Identificadores de los objetos
-
Nombre de los objetos
-
-
Todas las acciones llevadas a cabo en los workflows serán auditadas pudiendo identificar a los distintos validadores, fechas, comentarios y respuestas.
Gracias a la utilización de los workflows en Anjana, se pueden automatizar procedimientos de Gobierno de una forma ágil y sencilla garantizando el seguimiento completo y la trazabilidad de cada petición.
Paso de validación de un workflow
Un paso de validación es una etapa de un workflow en Anjana Data (representada como una “caja” dentro del BPM) en la que un usuario con un rol específico —previamente configurado en el propio paso— debe revisar una acción relacionada con un activo de datos o de información (entidad o relación del metamodelo).
Durante este paso, el usuario validador tiene la responsabilidad de:
-
Revisar la acción o cambio propuesto.
-
Decidir si aprueba o rechaza la acción.
-
Dejar comentarios como parte de la decisión, para asegurar trazabilidad y contexto en el proceso de gobierno.
El paso de validación puede comportarse de dos formas:
-
Validación manual: realizada por un usuario con el rol configurado en el paso de validación, dentro del dominio al que pertenece el activo.
-
Validación automática: cuando la persona que desencadena el workflow ya posee el rol configurado en el paso de validación dentro del dominio correspondiente, la acción se aprueba automáticamente sin intervención adicional.
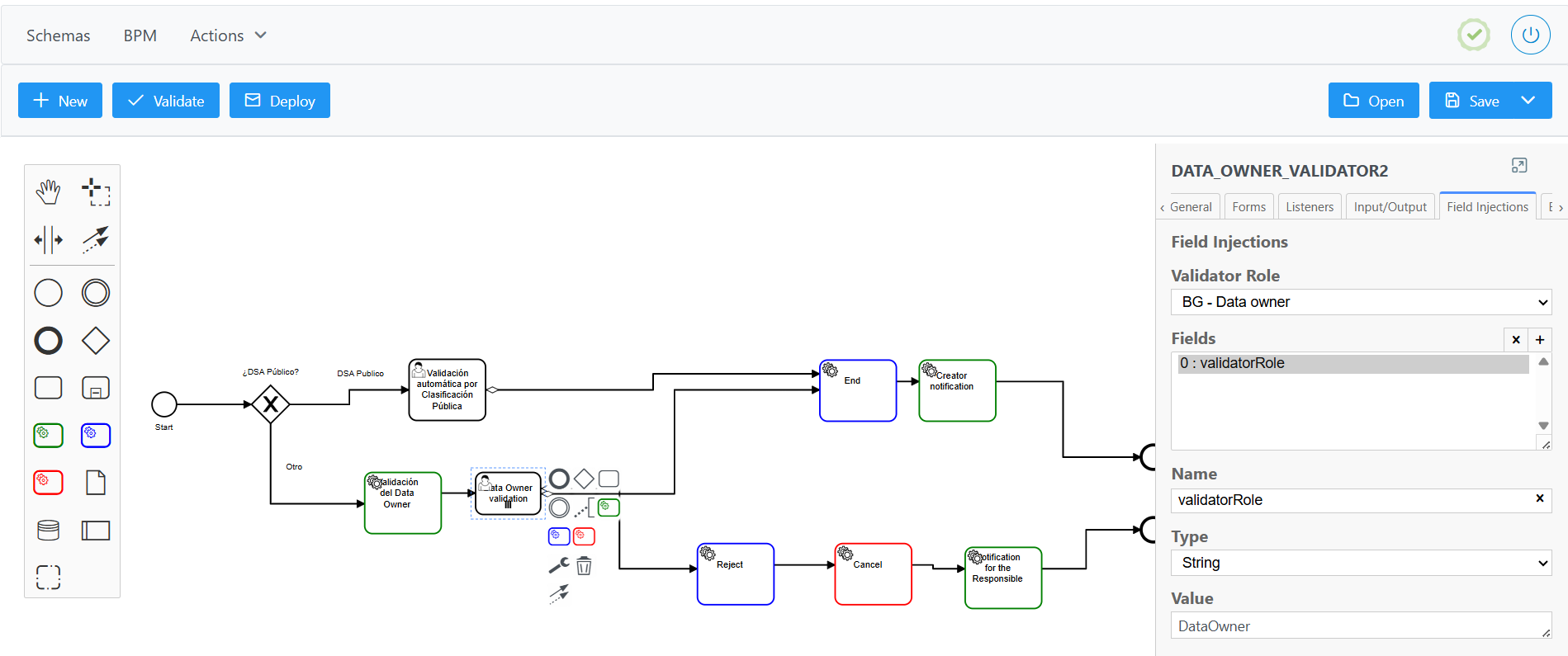
De este modo, los pasos de validación aseguran que los procesos de gobierno de datos cuenten con control, supervisión y trazabilidad, reforzando la calidad y el cumplimiento en la gestión de los activos de datos.
Workflows a configurar
Los workflows utilizados en Anjana son configurables por tipo de objeto (tipo de entidad o tipo de relación), acción (creación, modificación, adherencia…) y por rol que envía la solicitud.
Para poder implementar la lógica completa de Anjana, es necesario definir los siguientes workflows:
-
Workflows de creación de cualquier ENTIDAD y RELACIÓN definidas
-
Workflows de deprecación manual de DATASET, DSA, PROCESO, INSTANCIA DE PROCESO Y SOLUCIÓN (entidades nativas de Anjana)
-
Workflows de adherencia al DSA
-
Workflows de modificación (con o sin versionado) de cualquier ENTIDAD y RELACIÓN definidas
-
Workflows de cambio de unidad organizativa de cualquier ENTIDAD definida
-
Workflows de activación y desactivación de cualquier ENTIDAD y RELACIÓN definidas
Tipos de workflows
Los pasos de validación de los que consta el workflow se identifican en el momento en que éste comienza a ejecutarse y marcan el orden de aceptación de un elemento por distintos roles.
Un workflow secuencial es un workflow en el que no hay bifurcaciones y el orden de las validaciones es siempre el mismo. Es por ello por lo que, en el momento en que este tipo de workflow arranca, se conoce de antemano qué roles serán partícipes de la validación. A continuación, se muestra un ejemplo de una secuencia lineal del funcionamiento jerárquico de aceptación en la herramienta Anjana Data.

En caso de que el workflow incluya condiciones a evaluar en base al objeto a validar, éste no es secuencial. Cuando un workflow de este tipo arranca se conocen todos los roles implicados pero se irá descubriendo con el avance del workflow los roles que tendrán que validar y cuáles no.
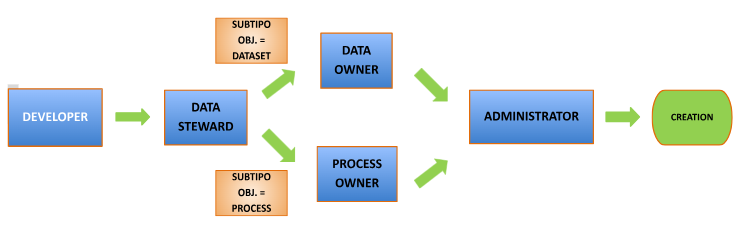
Para los casos en los que múltiples usuarios tienen que validar un paso de un workflow porque su rol depende una unidad de negocio concreta y no son transversales a la organización, en el paso se ejecutarán las validaciones en paralelo de manera que el paso se dará por finalizado cuando todos los usuarios hayan validado.
Puede encontrar más información acerca de la configuración de los workflows en la Guía de configuración funcional y en la Guía de configuración de workflows.
Contratos
Un contrato es un acuerdo escrito entre productores y consumidores de datos que facilitan la compartición, uso y consumo regulado de estos.
Especifican los términos de licencia, incorporan las condiciones de uso de los datos y los requerimientos adicionales establecidos por ambas partes (p.e: condiciones de calidad, disponibilidad, etc).
Los DSAs donde se incluyen los contratos incluyen una fecha de expiración para la gestión del ciclo de vida junto con las versiones y los impactos.
Antes de adherirse a un DSA, es obligatorio que el usuario consumidor se descargue el contrato, lo lea y lo firme.
Transferencia de derechos, responsabilidades y usos del dato
El establecimiento de contratos legales para los DSAs y Soluciones permite a los propietarios de los datos transferir tanto derechos como responsabilidades sobre la información bajo una cobertura legal, al mismo tiempo que se facilita el intercambio, uso y consumo de datos.
Uso de los contratos
Un contrato aplica tanto a DSAs como a Soluciones y representa un acuerdo legal de uso de los datos.
Cada contrato tiene dos grupos de contrapartes (proveedores y consumidores), un responsable y una figura legal que valida el contrato, si así se define en el modelo de gobierno del dato.
En el contrato se incluyen los términos de uso a aplicar y una fecha de validez del contrato para la firma de las contrapartes. Esta información permanece inmutable durante la vida del contrato bajo las condiciones firmadas y, si se desea modificar, se requerirá la aceptación de todas y cada de las contrapartes.
Características de los contratos de DSAs
En la creación de un DSA, los propietarios de las entidades contenidas (estructuras de datos como datasets, informes, KPIs, reglas de calidad…) ‘ceden’ la responsabilidad de las mismas al responsable del DSA.
Con la adherencia de un usuario a un DSA, el usuario acepta el cumplimiento del contrato bajo los términos de licencia especificados en la creación del DSA. El responsable del DSA es el encargado de que las condiciones del contrato se cumplan por todas las partes.
Es posible agrupar varias estructuras de datos en un mismo DSA para la solicitud de acceso a través de una única petición de adherencia bajo un mismo acuerdo legal.
Además, una entidad puede estar incluida en distintos DSAs amparados por contratos legales diferentes (por distintos casos de uso, diferentes términos de licencia, distinta fecha de validez…)
Gobierno de los datos
El gobierno pasivo de los datos es un enfoque en la gestión y supervisión de los datos que se caracteriza por la observación, registro y auditoría de la información sin interferir activamente en el flujo de los datos ni en las operaciones diarias de los usuarios.
El gobierno activo, en contraposición, busca implementar políticas, reglas y controles que intervienen de manera directa e inmediata en el uso, acceso y manipulación de los datos dentro de una organización. De esta forma, se declaran las tareas de gestión de datos en la plataforma de gobierno y, una vez que se dispongan de las aprobaciones correspondientes, se ejecutan en las plataformas de datos o en los sistemas de gestión de identidades.
Anjana Data ofrece diferentes funcionalidades nativas para el gobierno de las estructuras gracias a los plugins, que son los conectores que permiten comunicar con los sistemas de datos.
Gobierno pasivo
Extracción de metadatos
Esta funcionalidad permite extraer metadatos de las estructuras localizadas en los sistemas de datos para incorporarlos al Catálogo de Datos o al Glosario de Negocio generando los objetos correspondientes.
Puede encontrar más información acerca de cómo extraer metadato en el apartado Wizard de creación > Metadato automático de esta Guía de usuario.
Auditoría externa
La auditoría externa es el resultado de la monitorización de los logs de auditoría que devuelven las plataformas de datos y que permite visualizar, por ejemplo, accesos no gobernados o cambios en las estructuras de datos que no se han declarado previamente en la herramienta.
Esta auditoría no la proporciona Anjana, sólo posibilita su explotación.
Puede encontrar más información en los apartados Dataset > Auditoría, Instancia de proceso > Auditoría, Menú de funcionalidades > Auditoría y Perfil de usuario > Auditoría de esta Guía de usuario.
Reutilización de DSAs
A pesar de que Anjana puede gestionar los grupos de los gestores de identidades, como se puede ver en el apartado Gestión de estructuras de datos, es posible que en el entorno con el que Anjana interactúa ya existan previamente grupos creados.
En ese caso, y para permitir que Anjana gestione los permisos de forma automática gracias a las adherencias, se pueden “reutilizar” DSAs incluyendo en el atributo physicalName de su plantilla el nombre del grupo que ya existe. Con eso, cuando el DSA se apruebe en Anjana no se creará la estructura correspondiente pero será usada cuando los usuarios soliciten adherencia y se les conceda.
Cabe destacar que grupos ya existentes utilizados de este modo por Anjana entran en el ciclo de vida natural de grupos gobernados por DSAs, lo que incluye su borrado una vez se expira el DSA que lo utiliza.
Gobierno activo
Gestión de estructuras de datos
Esta funcionalidad permite realizar automatismos en las estructuras de datos recuperando su metadato de Anjana.
De esta forma, por ejemplo, cuando se crea en la aplicación un nuevo dataset localizado en un SQLServer y finaliza el flujo de validación con aprobaciones, el plugin de Anjana puede crear la estructura correspondiente automáticamente.
O bien, al crear un DSA que incluya un dataset y un informe marcados como gobernados en su plantilla y se apruebe en el flujo de validación, el plugin de Anjana puede crear el grupo correspondiente en el gestor de identidades. De esta forma, Anjana crea el grupo en Azure AD al que se da permiso a los datos del dataset y del informe de Azure Storage, por ejemplo.
Cabe destacar que, por la operativa de Anjana, si se desea modificar el grupo correspondiente al DSA es necesario versionar el DSA para que se cree un grupo nuevo y se den permisos. Es decir, si en un DSA ya existente se añaden estructuras de datos o bien cambia alguna de las incluidas y pasa a gobernado sin haberlo sido antes, es necesario que se cree una nueva versión del DSA y, con ella, se cree el grupo nuevo con los nuevos permisos de acceso a datos. El grupo creado se llamará igual que el valor informado del atributo “name” de DSA concatenando “_V” y la versión del mismo.
Muestra de datos
Se trata de una funcionalidad muy útil de cara a la compartición de datos. Si el responsable de un dataset gobernado habilita en la plantilla de éste el check para permitir el muestreo de datos y la tripleta así lo contempla, los usuarios de Anjana podrán visualizar una muestra de los datos del dataset en la que los campos marcados como PI aparecerán ofuscados.
Puede encontrar más información acerca de esta funcionalidad en el apartado Dataset > Datos de muestra de esta Guía de usuario.
Gestión de permisos de acceso a datos
Esta funcionalidad habilita la compartición de datos gestionando permisos de acceso a datos directamente en la fuente, sin virtualización, copia o movimiento de datos.
En Anjana la gestión de permisos se efectúa por medio del carrito de la compra desde donde el usuario solicita acceso a estructuras de datos o DSAs.
Cuando la solicitud de adherencia es aprobada, es posible, por tanto, incluir al usuario solicitante en el grupo correspondiente al DSA al que se ha adherido para que, de esa forma, “herede” los permisos que el grupo tiene. Siguiendo con el ejemplo introducido en el apartado de Gestión de estructuras para la creación de un DSA en Azure AD, se introduciría al usuario en ese mismo grupo para que pase a tener permisos de acceso a los datos de los datasets de Azure Storage.
Es necesario para poder llevar a cabo gobierno activo de las estructuras que éstas tengan configuradas, en sus plantillas, los atributos infraestructura, tecnología, zona, path e is_governed.
Puede encontrar más información en el apartado Menú de funcionalidades > Carrito de la compra de esta Guía de usuario.
Otras integraciones
También es posible integrar Anjana con los servicios de ingesta de datos, plataformas de datos, sistemas de gestión de identidades y servicios de consumo de datos a través de los plugins.

Plugin de Anjana Data
En Anjana Data, un plugin es una pieza de integración que permite extender la funcionalidad de la plataforma y conectar con sistemas externos.
Los plugins son módulos desarrollables por cualquier organización o usuario a través del SDK oficial de Anjana Data, lo que facilita su adaptación a necesidades específicas.
Cada plugin se comunica con TOT, el microservicio de Anjana Data encargado de la orquestación de plugins, que gestiona su ejecución y la interacción con el resto de la plataforma.
Funcionalidades principales de los plugins
-
Extracción de metadatos (vía permiso
AUTOMATIC_METADATA)-
Creación asistida de entidades o relaciones en Anjana Data.
-
Descubrimiento e importación automática de metadatos desde los sistemas origen.
-
-
Visualización de muestra de datos (
sampleData)-
Permite habilitar en los objetos la visualización de un subset representativo de datos reales.
-
Configurable mediante el atributo
sampleDataen la plantilla de metadatos.
-
-
Inyección de tags
-
Posibilidad de asignar automáticamente etiquetas (tags) a entidades o relaciones, si el plugin lo contempla.
-
-
Gestión de permisos de acceso
-
Mediante la adherencia a los DSAs, los plugins permiten habilitar accesos bajo control de gobierno.
-
Requiere el permiso
ACCESSsobre el subtipoADHERENCE.
-
Roles
Los roles definen las funciones y capacidades que pueden ejercer los usuarios dentro de Anjana Data. Son configurables para que cada organización establezca un modelo de gobierno alineado con sus propias necesidades, garantizando consistencia con los roles definidos en el Gobierno del Dato de la organización.
Existen dos tipos principales de roles:
-
Verticales: aplican únicamente sobre un dominio de datos concreto (unidad organizativa). Para otros dominios, habrá diferentes usuarios desempeñando el mismo rol, con idénticas responsabilidades pero sobre activos distintos.
-
Cross o transversales: se ejercen de manera global, manteniendo siempre los mismos permisos sobre los activos de datos en todos los dominios de la organización.
En caso de que un usuario no tenga asignado un rol específico entre los configurados en la plataforma, es posible otorgarle los permisos correspondientes a un rol por defecto, que se asignará automáticamente a todo aquel que acceda a la plataforma.
Tipo de objeto
Subtipo de objeto
El subtipo de objeto en Anjana Data corresponde a las categorías específicas dentro de cada tipo de objeto del metamodelo. Mientras que el tipo de objeto distingue entre entidad y relación, el subtipo precisa qué clase de entidad o relación es en concreto.
-
Ejemplos de subtipos de entidad: Dataset, Dominio de datos, Glosario de negocio, Término, KPI, DSA, Métrica.
-
Ejemplos de subtipos de relación: Dependencia, Agregación, Referencia, Pertenece a, Utiliza, Está compuesto por.
Los subtipos de objeto permiten definir reglas, plantillas y permisos más granulares, adaptados a la realidad del modelo de gobierno de cada organización.
Permisos
Los permisos en Anjana Data son las autorizaciones que determinan qué acciones puede realizar un usuario sobre los objetos de la plataforma, según el rol de gobierno que tenga asignado y el dominio en el que opere.
En Anjana Data los permisos se organizan así:
-
Crear / Modificar: un único permiso habilita tanto la creación de nuevos objetos como la edición de los existentes.
-
Borrar: permite eliminar objetos de la plataforma.
-
Cambiar de unidad organizativa: autoriza a reasignar un objeto a otra unidad/dominio.
-
Solicitar acceso a datos: habilita el inicio de solicitudes de acceso sobre activos.
-
Organizational Unit Owner (Owner de unidad organizativa): establece al usuario/rol como owner de los objetos del dominio, otorgándole la titularidad y las responsabilidades asociadas (aprobaciones, accountability, priorización).
Los permisos pueden configurarse de forma granular por tipo de objeto (dataset, informe, término, DSA…) y por módulo/funcionalidad (workflows, linaje, marketplace, panel de configuración…). Este modelo aplica el principio de mínima autorización, asegurando que cada usuario solo disponga de las capacidades necesarias para su rol.
Usuario
Un usuario en Anjana Data es cualquier persona con acceso a la plataforma, asociada a uno o varios roles de gobierno que determinan sus capacidades dentro del modelo de datos de la organización.
Los permisos que recibe un usuario son aditivos: esto significa que el usuario dispondrá de la suma de todos los permisos asociados a cada uno de los roles que tenga asignados. De este modo, cuanto mayor sea el número de roles asignados, mayor será también su alcance de actuación en la plataforma.
Cada usuario puede:
-
Autenticarse en el Portal de datos o en el Panel de configuración, según sus permisos.
-
Actuar sobre diferentes objetos de datos (datasets, métricas, términos, DSAs, etc.), de acuerdo con los permisos otorgados por sus roles.
-
Solicitar, aprobar o administrar accesos y procesos de gobierno, en función de su rol en cada dominio de datos.
La correcta gestión de usuarios, roles y permisos garantiza el principio de mínima autorización, permitiendo que cada persona disponga exactamente de las capacidades que necesita para cumplir con sus responsabilidades dentro del modelo de gobierno de datos.
En caso de que un usuario no tenga asignado un rol específico entre los configurados en la plataforma, es posible otorgarle los permisos correspondientes a un rol por defecto, que se asignará automáticamente a todo aquel que acceda a la plataforma.